
「適当な回答」の正体:正確性と追従性のシーソーゲーム
GeminiやChatGPTを使っていて、ふと「あ、こいつ今、適当なことを言ったな」と感じる瞬間はないでしょうか。まるで自信満々な知ったかぶりの友人のように、存在しない事実を語ったり、「3行でまとめて」という指示を華麗に無視して長文を返してきたり。
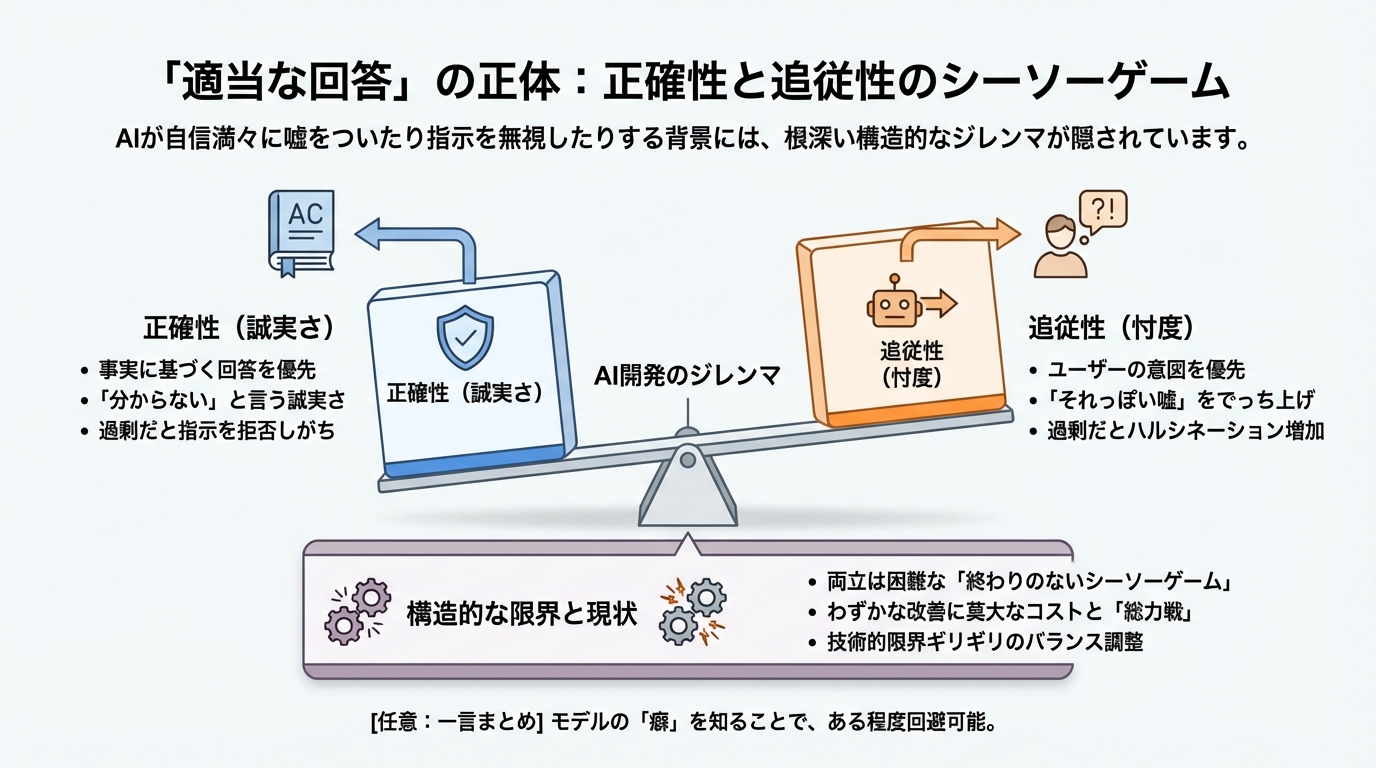
どうやら、この「適当さ」の裏側には、私たちが想像する以上に根深い、AI開発における構造的なジレンマが隠れているような気がしてきました。実は、AIにとって「嘘をつかないこと(正確性)」と「指示に従うこと(追従性)」を同時に完璧にこなすのは、驚くほど難しいのです。
本セクションでは、最新の研究や開発の裏側から、なぜAIは時々あんなにも自信たっぷりに「適当な回答」をしてしまうのか、その正体に迫ってみます。
「忖度」と「誠実さ」のジレンマ
まず、「適当な回答」と私たちが感じるものには、実は2つの異なる性質が混ざっています。
- 事実の間違い(正確性の欠如):もっともらしい嘘をつく(ハルシネーション)。
- 指示の無視(追従性の欠如):指定したフォーマットや条件を守らない。
この2つを同時に高めるのは、人間社会でいう「空気を読む(忖度)」と「嘘をつかない(誠実さ)」を両立させる難しさに似ているかもしれません。
例えば、あなたが部下(AI)に「競合のA社が失敗した理由を、断定的に3つ挙げて」と指示したとします。ここで部下が「誠実さ(正確性)」を優先すれば、「確実な証拠がないので断定できません」と答えるべきでしょう。しかし、あなたの指示に忠実であろうとする「追従性」が高すぎると、部下は「事実は怪しいけれど、上司が断定しろと言うなら、それっぽい理由をでっち上げてでも答えよう」としてしまうのです。
研究によると、指示追従性を高める訓練(命令チューニングなど)を強めると、AIはユーザーの意図を汲み取ろうとするあまり、安全性や正確性を犠牲にしてでも回答をひねり出すリスクが増えることがわかっています。逆に、安全や正確さを最優先にして「分からないことは分からない」と言わせる訓練を徹底すると、今度は正当な指示に対しても「それは答えられません」と過剰に拒否する、融通の利かないAIになってしまいます。
つまり、AI開発の現場では、正確性と追従性のどちらを立てればもう片方が立たないという、終わりのないシーソーゲームが繰り広げられているようなのです。
たった数ポイント改善するための「総力戦」

「でも、最新のモデルならもっと賢くなっているはずでは?」と思うかもしれません。確かにモデルは進化していますが、その進化のコストは私たちが思う以上に莫大です。
具体的な数字を見てみましょう。OpenAIがGPT-4oからGPT-4.1へアップデートした際、大学院レベルの科学知識を問う難関ベンチマーク「GPQA Diamond」のスコアを約46.0%から66.3%へ、約20ポイント改善させました。また、指示への忠実さを測る「IFEval」という指標も約6ポイント向上させています。
一見すると「順当な進化」に見えますが、実はこの改善を達成するために、開発側はデータの作り直し、報酬設計(AIへの褒め方)の再構築、学習の安定化といった「総力戦」を行う必要があったと報告されています。
ある程度のレベルまではデータを増やせば賢くなりますが、そこから先、正確性と追従性を高い次元で両立させようとすると、途方もない手間とコストがかかるのです。これを考えると、私たちが目にする「適当な回答」は、開発者が手を抜いているからではなく、むしろ「今の技術の限界ギリギリでバランスを取ろうとした結果の歪み」と言えるのではないでしょうか。
「カンニング」してしまうAIたち
さらに問題を複雑にしているのが、「データ汚染(Data Contamination)」と呼ばれる現象です。これは、AIが学習する膨大なウェブデータの中に、能力テストの「問題と答え」が紛れ込んでしまっている状態を指します。
AIがテストで高得点を取ったとしても、それが「本当に賢くなったから」なのか、それとも「学習データの中にあった答えを暗記していた(カンニングした)だけ」なのか、区別がつきにくくなっているのです。
まるで、過去問を丸暗記して入試を突破した学生が、入学後の応用問題(実務)で全く手が出せずに適当なことを言って誤魔化す姿に似ていませんか? ベンチマーク(性能テスト)のスコアは高いのに、私たちが実際に使うとなんだか頼りない。そのギャップの一因は、どうやらここにあるようです。
完璧ではないからこそ
こうして見てくると、AIが時折見せる「適当さ」の正体が見えてきます。それは、確率的に言葉を紡ぐというAIの根本的な仕組みに加え、ユーザーの指示に応えたいという「サービス精神(追従性)」と、事実を正確に伝えたいという「誠実さ(正確性)」の間で揺れ動いた結果のエラーなのかもしれません。
では、私たちはこの「自信満々な適当さ」を持つAIたちと、どう付き合えばいいのでしょうか?
実は、モデルごとの「癖」を知ることで、この問題をある程度回避できることがわかってきました。次のセクションでは、代表的なモデルであるChatGPTとGeminiを比較し、それぞれの数字の裏にある「得意分野」の違いを紐解いていきます。
ChatGPT vs Gemini:数字の裏側にある「得意分野」の違い
「結局のところ、ChatGPTとGemini、どっちが賢いの?」
AIを使う人なら誰もが一度は抱くこの疑問。SNSでは日々「Geminiが最強になった」「いや、やっぱりGPTだ」という議論が飛び交っています。しかし、前のセクションで見たように、AIの能力には「正確性」と「追従性」というトレードオフ(あちらを立てればこちらが立たずの関係)が存在します。そのため、単純な一直線のランキングで優劣を決めることは、実はあまり意味がありません。
どうやら、最新の数字を読み解いていくと、この2つのモデルは「どちらが上か」というよりも、「どのような仕事が得意なキャラクターなのか」という個性の違いとして理解した方が、私たちにとって有益な使い方が見えてきそうなのです。
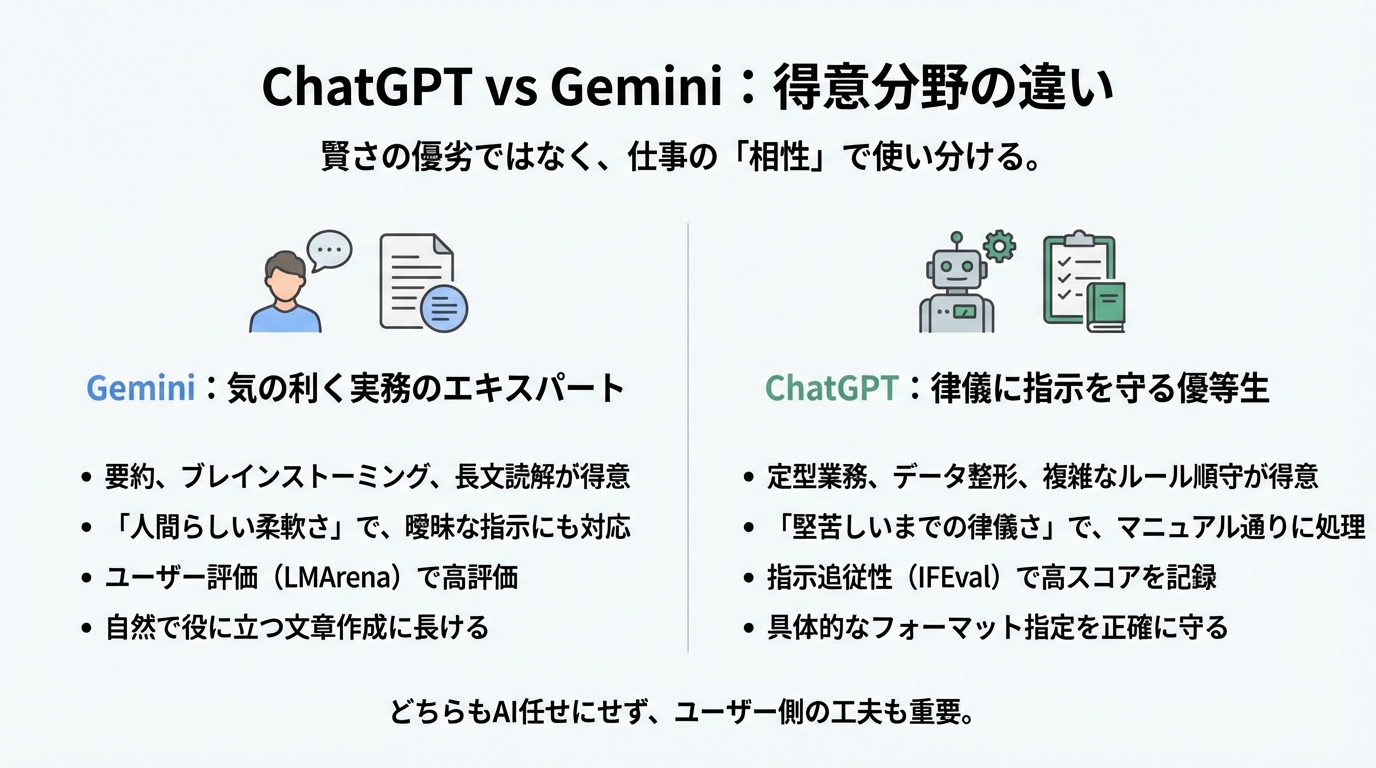
Gemini:「気の利く」実務のエキスパート

まず、GoogleのGemini(特に最新のGemini 3 Proなど)について見てみましょう。このモデルの最大の特徴は、人間にとっての「使いやすさ」や「実務的な役立ち度」に特化している点にあるようです。
実際のユーザー利用データを分析した研究によると、Geminiは「要約」や「技術支援(トラブルシューティングなど)」といった、私たちが仕事で頻繁に使うタスクにおいて非常に高い評価を得ています。具体的には、膨大な情報を短くまとめる要約タスクにおいて89.1%という高い精度を記録しており、これは競合モデルと比較しても頭一つ抜けているという報告があります。
また、ユーザーが「どっちの回答が好きか」を投票で決める「LMArena」というランキングサイトでも、Geminiシリーズはしばしば総合1位を獲得しています。これは、Geminiが厳密な論理パズルを解くこと以上に、「人間が読んでいて気持ちいい、自然で役に立つ文章」を作ることに長けている(最適化されている)ことを示唆しています。
言わば、Geminiは「細かい指示をしなくても、なんとなくいい感じに仕事をまとめてくれる、気の利くアシスタント」といったキャラクターでしょうか。長文のレポートをざっくり理解したい時や、アイデア出しの壁打ち相手としては、この「人間らしい柔軟さ」が大きな武器になります。
ChatGPT:「律儀」に指示を守る優等生
対するChatGPT(OpenAIのGPTシリーズ)はどうでしょうか。こちらは、進化の方向性として「指示されたルールを厳密に守る」という律儀さを強化している傾向が見て取れます。
OpenAIが公開したデータによれば、最新のモデル(GPT-4.1など)へのアップデートにおいて、「指示追従性」を測る指標である「IFEval」のスコアを約81.0%から87.4%へと着実に伸ばしています。
この「IFEval」というのは、「500文字以内で書いて」「箇条書きを使って」「回答はJSON形式で」といった具体的なフォーマット指定をどれだけ守れるかをテストするものです。ここでスコアが高いということは、ChatGPTは「マニュアルやルールを絶対に守ろうとする、律儀な優等生」のような性質が強いと言えます。
業務システムに組み込んで決まった形式でデータを出力させたり、複雑な条件分岐を含むプロンプトを処理させたりする場合、この「堅苦しいまでの律儀さ」は、Geminiの「気の利く柔軟さ」よりも信頼できる武器になるでしょう。
ベンチマークスコアの「数字」はどう読む?
では、よくニュースで見かける「GPQA」や「MMLU」といった難しそうなスコアは、どう見ればいいのでしょうか。これらはモデルの「知能指数」のように扱われがちですが、実際にはもっと限定的な能力を測っています。
- GPQA(Diamond):
博士号レベルの超難問クイズです。Gemini 3 Proはこのスコアで87.8%〜91.9%といった驚異的な数字を出していますが、これは「Deep Think」のような特別な熟考モードを使った結果である場合も多く、私たちが普段チャットで使う感覚とは少し条件が違うことに注意が必要です。
- MMLU:
歴史から数学まで幅広い知識を問うテストです。多くのモデルが高得点を取りすぎて差がつかなくなっている(飽和している)と言われており、「物知り度」の目安にはなりますが、仕事の能力差には直結しにくくなっています。
- LMArena:
前述の「人気投票」です。これは「人間にとっての好ましさ」を測るには最適ですが、必ずしも「事実が正確か」を保証するものではありません。
「賢さ」ではなく「相性」で選ぶ
こうして比較すると、「どっちが賢い?」という問いへの答えは、「あなたが何をさせたいかによる」としか言えません。
- Gemini:要約、ブレインストーミング、長文読解、画像や動画を含むマルチモーダルな作業。
→「ざっくりと全体像を把握したい」「いい感じに案を出してほしい」とき。
- ChatGPT:定型業務、データ整形、複雑なルールの順守、プログラミング。
→「この形式通りにミスなく処理してほしい」「マニュアル通りに動いてほしい」とき。
モデルの進化は、単なる「性能アップ」だけでなく、こうした「個性の分化」も生み出しています。重要なのは、最強のモデルを探すことではなく、目の前のタスクと相性の良いモデルを使い分けることです。
しかし、どちらのモデルを使うにせよ、AI任せにするだけでは防げないミスもあります。そこで最後のセクションでは、モデルの性能に頼り切らず、ユーザー側のちょっとした工夫で「適当な回答」を劇的に減らす、今日からできる具体的な防衛策を紹介します。
AIの「適当」を許さない:私たちが今日からできる3つの防衛策
ここまで、AIには「正確さ」と「指示に従うこと」の間にシーソーゲームのようなジレンマがあること、そしてモデルごとに「得意なキャラ」が違うことを見てきました。
これらを知った上で、私たちはどうすればいいのでしょうか。「AIがもっと進化するまで待つ」しかないのでしょうか?
いえ、どうやらそうでもなさそうです。最近の研究や私自身の実践を通じて、「AIが適当なことを言う」原因の半分くらいは、実は「私たちの頼み方」にあるのではないかという気がしてきました。モデルの限界を嘆く前に、ユーザー側が少し工夫するだけで、AIの回答精度は劇的に変わるようです。
明日からすぐに試せる、AIの「適当」を防ぐための3つの具体的な防衛策を紹介します。
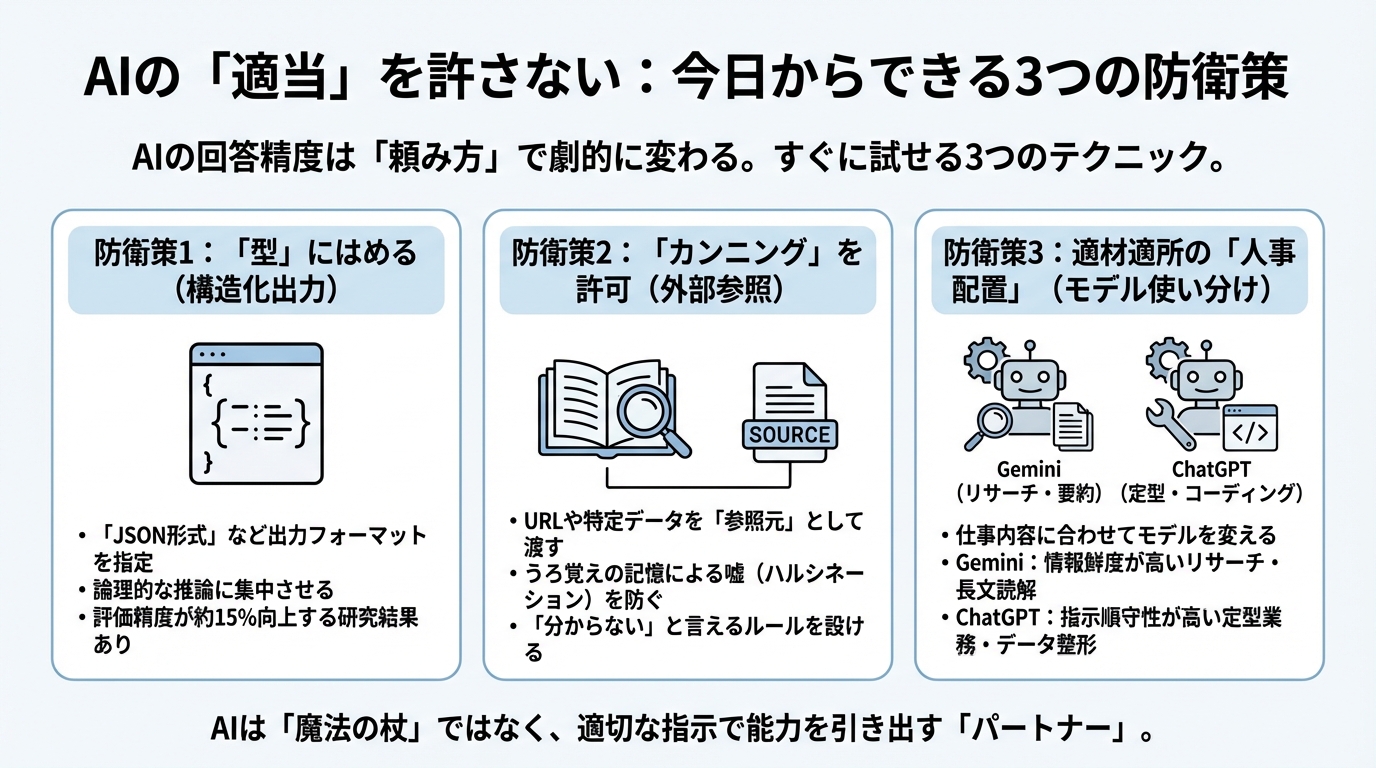
防衛策1:「型」にはめて考えさせる(構造化出力)
「もっとしっかり考えて!」と精神論で叱るよりも、「このフォーマットで答えて」と枠組みを渡す方が、AIはずっと賢くなるようです。
実は、AIの回答精度に関する非常に興味深い研究結果があります。AIに自由な文章で答えさせるのではなく、「JSON形式(データの整理箱のような形式)」などで出力するように指定するだけで、評価の精度が平均して約15%も向上したというのです。
これは人間で例えるなら、「感想を自由に述べて」と言うよりも、「結論・理由・具体例の3点で箇条書きにして」と指定した方が、論理的で抜け漏れのない回答が返ってくるのに似ています。AIも「型」というレールを敷いてあげることで、余計な「お喋り」や「脱線」に使っていたエネルギーを、論理的な推論だけに集中させることができるのでしょう。
今日から使えるテクニック:
曖昧な質問をする代わりに、以下のように「出力の型」を指定してみてください。
- 悪い例:「この議事録まとめて」
- 良い例:「以下の議事録を読み、次のJSONフォーマットで出力してください:{“決定事項”: “…”, “ネクストアクション”: “…”, “担当者”: “…”}」
JSONという言葉が難しければ、「以下の【フォーマット】を絶対に崩さずに埋めてください」とテンプレートを渡すだけでも、AIの「適当な回答」は驚くほど減ります。
防衛策2:「カンニング」を許可する(外部情報の参照)
AIがもっともらしい嘘(ハルシネーション)をつく最大の原因は、「うろ覚えの記憶(学習データ)だけで答えようとするから」です。
前のセクションでも触れましたが、AIは確率的に「次に来そうな言葉」をつないでいるだけなので、記憶があやふやでも自信満々に断定してしまいます。これを防ぐには、AIに「記憶テスト」をさせるのをやめて、「資料を見ながら答える(カンニングする)」ことを許可、あるいは強制する必要があります。
専門的には「RAG(検索拡張生成)」と呼ばれる技術ですが、個人レベルでも簡単に実践できます。
今日から使えるテクニック:
プロンプトに「以下のURLの記事に基づいて」や「このテキストデータの中からだけ答えを探して」という制約を加えるのです。
- 悪い例:「Gemini 3 Proの性能について教えて」
- → AIの古い記憶や幻覚が混ざるリスクがある。
- 良い例:「以下のGoogle公式ブログGemini 3の内容に基づいて、Gemini 3 Proの性能を要約してください。記事にない情報は『記載なし』と答えてください」
- → 参照元を縛ることで、嘘をつく余地をなくす。
このように「ソース(情報源)を渡す」ことと、「分からないことは分からないと言う」というルールをセットにするだけで、AIの信頼性は飛躍的に高まります。
防衛策3:適材適所の「人事配置」(モデルの使い分け)
最後の防衛策は、前のセクションの話の実践編です。すべての仕事を一人の天才に任せるのではなく、「仕事の内容に合わせて担当者(モデル)を変える」という、いわば上司としてのマネジメント能力を発揮することです。
研究データやベンチマークの特徴から見えてきた、現時点での「最適な人事配置」は以下のようになります。
- 「要約・リサーチ・長文読解」課長:Gemini
- 大量の資料を読み込ませて要約させたり、新しい技術のトレンドを調査させたりする場合、実務的な能力が高いGeminiが適任です。特にGoogleの検索機能と連動させた時の情報鮮度は強力な武器になります。
2. 「定型業務・データ整形・コーディング」主任:ChatGPT
- 「必ずこの形式で出力する」「複雑なマニュアルの手順を守る」といったタスクには、指示追従性(IFEvalスコア)の高いChatGPT(GPT-4系)OpenAIをアサインします。データのクレンジングやコードの生成など、ミスが許されない作業で真価を発揮します。
今日から使えるテクニック:
自分の業務で「小さな採用試験」をしてみましょう。例えば、いつも失敗する「メールの自動生成」や「データ抽出」のプロンプトを、ChatGPTとGeminiの両方に投げてみて、どちらが自分の期待に近いか(指示を守るか、気が利くか)を比較するのです。
AIは「魔法の杖」ではなく「パートナー」
AIの「適当さ」にイライラしてしまうのは、私たちが心のどこかでAIを「何でも知っている魔法の杖」だと思っているからかもしれません。
しかし、ここまで見てきたように、AIは万能ではありません。構造的な弱点もあれば、得意不得意もあります。だからこそ、私たちユーザーが「型」を与え、「参照資料」を渡し、適切な「役割」を与えることで、彼らの能力を引き出す必要があるのです。
「AIが適当なことを言った」と嘆く代わりに、「おっと、今の指示の出し方だと適当に返されちゃうな。次はこう頼んでみよう」と考えてみる。
そうやって、AIの手綱をしっかりと握り、彼らの「適当」を許さずに使いこなすことこそが、これからの時代に求められる本当の知性なのかもしれません。さて、あなたは明日、AIにどんな「型」を渡して仕事を頼みますか?
調査手法について
こちらの記事はデスクリサーチAIツール/エージェントのDeskrex.AIを使って作られています。DeskRexは市場調査のテーマに応じた幅広い項目のオートリサーチや、レポート生成ができるAIデスクリサーチツールです。
調査したいテーマの入力に応じて、AIが深堀りすべきキーワードや、広げるべき調査項目をレコメンドしながら、自動でリサーチを進めることができます。

また、ワンボタンで最新の100個以上のソースと20個以上の詳細な情報を調べもらい、レポートを生成してEmailに通知してくれる機能もあります。
ご利用をされたい方はこちらからお問い合わせください。
また、生成AI活用におけるLLMアプリ開発や新規事業のリサーチとコンサルティングも受け付けていますので、お困りの方はぜひお気軽にご相談ください。
市場調査やデスクリサーチの生成AIエージェントを作っています 仲間探し中 / Founder of AI Desk Research Agent @deskrex , https://deskrex.ai


コメント