
長文コンテキストの「コストの壁」を突破する:ハイブリッド化の必然性
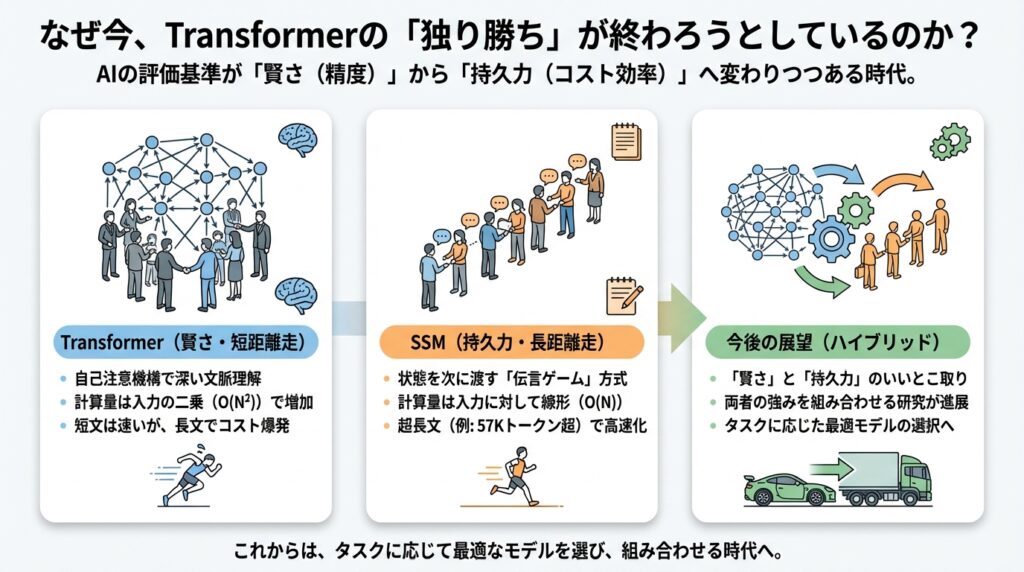
最近、AIを使っていてこんなことを感じる瞬間はないでしょうか。「このPDF、数百ページあるけれど全部読んで要約してほしい」「過去数年分の議事録から、特定の決定事項だけを探し出したい」。
どうやら私たちは、AIに対してもっと長い文章、つまり「長文コンテキスト」を扱える能力を求めているようです。しかし、そこで立ちはだかるのが、現在のAIの主役であるTransformerモデルが抱える「コストの壁」です。
なぜ今、Transformerと状態空間モデル(SSM)を組み合わせた「ハイブリッドモデル」が急速に注目されているのか。それは単なる流行ではなく、物理的な計算リソースの限界を突破するための、必然的な進化である気がしてなりません。
「全ページ総当たり」の限界
現在、ChatGPTやClaudeなどの基盤となっているTransformerモデルは、非常に優秀です。しかし、その仕組みにはある種の「富豪的」な贅沢さがあります。それが自己注意(Self-Attention)メカニズムです。
これは、文章中のある言葉を理解するために、他のすべての言葉との関係性を計算する仕組みです。例えるなら、本の1ページ目を読むために、最終ページまでの全てのページをめくって関連性を確認するようなものです。この仕組みのおかげで高い精度が出るのですが、計算コストに関しては「2乗の法則(O(N^2))」という宿命を背負っています。
どういうことかと言うと、読ませたい文章の長さ(トークン数)が2倍になれば、計算量は4倍になります。もし10倍になれば、計算量は100倍に膨れ上がります。
実際、GPU(AIの計算を行う半導体)のメモリは有限です。数万、数十万トークンという長文を扱おうとすると、この「2乗の壁」が物理的な限界として立ちはだかります。これまでの研究でも、Transformerは長文処理において、計算量とメモリ消費が指数関数的に増大し、実用が困難になるボトルネックが指摘されてきました。
「もっと長く読みたい、でも計算機が持たない」。このジレンマを解消するために、私たちは新しいアプローチを必要としていたのです。
24GBのGPUで「本数十冊分」を処理する衝撃
そこで救世主のように現れたのが、状態空間モデル(SSM)、特にMambaと呼ばれる技術です。
SSMの最大の特徴は、計算量が文章の長さに対して「線形(O(N))」であることです。つまり、文章が2倍になれば計算量も2倍、10倍なら10倍で済みます。Transformerの「100倍」とは雲泥の差です。
これがどれほど劇的な違いかを示す、興味深い実測データがあります。最近の研究報告によると、一般的な消費者向けの24GBメモリを搭載したGPUでも、SSMならば最大220K(22万)トークンもの長文を処理できたといいます。
22万トークンといえば、日本語の文庫本でざっと2〜3冊分、英語ならもっと膨大な量に相当します。これを、スーパーコンピュータではなく、ハイエンドなゲーミングPCレベルのGPUで動かせるというのは、これまでの常識を覆す事実ではないでしょうか。
さらに、非常に長い文脈(約5万7000トークン以上)においては、SSMはTransformerと比較して最大4倍も高速に処理できるという結果も出ています。これはもはや、単なる「効率化」のレベルを超えて、これまで不可能だったことを可能にする「物理的制約の突破」と言えるでしょう。
なぜ「ハイブリッド」なのか?
「それなら、全部SSMに変えてしまえばいいのでは?」と思うかもしれません。しかし、話はそう単純ではありません。SSMは「読み進めながら要点をメモしていく」ような処理をするため、前のページの細かい記述を忘れてしまうことがあります(この点は次章で詳しく触れます)。
そこで、「局所的な精度に強いTransformer」と「長文を低コストで流せるSSM」を組み合わせるハイブリッド化が、極めて合理的な解決策として浮上してくるのです。
実際、Falcon-H1などの最新モデルでは、このハイブリッド構成を採用することで、長文コンテキストでの入力スループット(処理速度)を最大4倍に高めつつ、高い精度を維持することに成功しています。
私たちが直面しているのは、「AIに何をさせるか」というソフトの課題だけでなく、「それをどう物理的に動かすか」というハードの課題です。長文需要と計算コストの衝突。この壁を乗り越えるために、AIモデルはハイブリッド化という進化を、必然的に選ばざるを得なかったのではないでしょうか。
さて、では具体的にTransformerとSSMはどう違う動きをしているのでしょうか? 次のセクションでは、そのメカニズムの違いを「全ページ参照」と「要約ノート」という視点で対比してみたいと思います。
メカニズムの対比:「全ページ参照」のTransformerと「要約ノート」のSSM
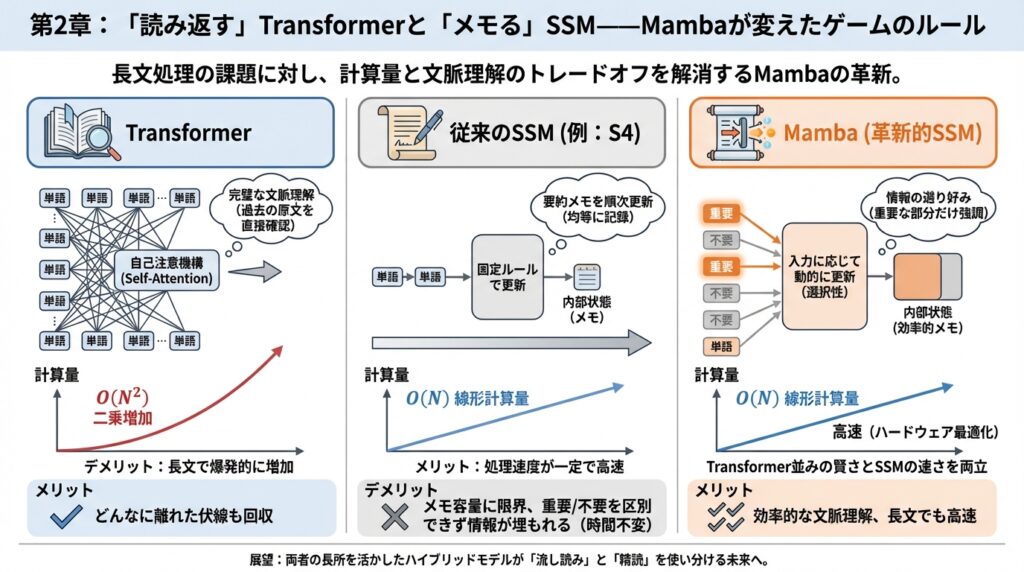
前章では、私たちが直面している「計算コストの壁」について触れました。では、なぜTransformerは重く、SSM(State Space Model)は軽いのでしょうか?
どうやら、この二つは根本的に「情報の扱い方」が違うようです。この違いを理解するには、難しい数式よりも、私たちの日常的な動作に例えた方が直感的に掴める気がしてきました。

Transformer:全ページを開きっぱなしにする「富豪」
まず、現在主流のTransformerモデルの動きを見てみましょう。これを人間に例えるなら、「試験中に教科書の全ページを見開きで机に並べ、一語一句カンニングしながら回答する学生」のようなものです。
Transformerの核となる自己注意(Self-Attention)という仕組みは、新しい単語を処理するたびに、過去のすべての単語との関係性を再計算します。「この『それ』は、100ページ前の『あの事件』を指しているのか?」といった照合作業を、毎回、全データに対して総当たりで行うのです。
この仕組みの凄さは、文脈を完璧に捉えられる点にあります。どんなに離れた情報でも、直接参照できるため、高い精度で意味を理解できます。
しかし、弱点も明らかではないでしょうか。教科書が10ページなら机に並べられますが、1万ページになったらどうでしょう? 机(メモリ)は埋め尽くされ、探す時間(計算量)は爆発的に増えてしまいます。これが、前章で触れた「計算量 O(N^2)」の正体です。読み進めれば読み進めるほど、過去を振り返るコストが雪だるま式に増えていくのです。
SSM:小さなノート一冊で旅をする「ミニマリスト」
一方で、SSM(状態空間モデル)、特にMambaのアプローチは全く異なります。こちらは、「教科書は持ち込めないが、小さなノート一冊だけを持って読み進める学生」に似ています。
SSMは、制御理論という分野から来ています。例えば、車の運転を想像してみてください。アクセルを踏む(入力)と、燃料の消費量やエンジンの状態が変わり(状態更新)、スピードが出る(出力)。このとき、現在のスピードを決めるのは「今のエンジンの状態」だけであり、「1時間前にどうアクセルを踏んだか」という過去の履歴そのものを全部覚えているわけではありません。
これをAIの言語処理に応用すると、SSMは次のように動きます。
- 一文字読む。
- その内容を理解して、手元の「固定サイズのノート(状態)」を書き換える。
- 読み終わった文字のことは忘れて、次の文字へ進む。
この仕組みの最大の利点は、どれだけ長い本を読んでも、ノートの厚さが変わらないことです。1万ページ読もうが100万ページ読もうが、メモリ使用量は一定で、計算量は文字数に比例するだけ(線形計算量 O(N))で済みます。
だからこそ、一般的な24GBメモリのGPUでも、22万トークン(文庫本数冊分)という驚異的な長さを一度に処理できるのです。これは、物理的な制約を回避する非常に賢い方法だと言えるでしょう。
Mambaの革新性:「賢く書き残す」技術
「でも、小さなノート一冊に全てを書き留めるなんて無理では?」
鋭い方はそう思うかもしれません。おっしゃる通り、従来のSSMには「何を書き残して何を忘れるか」の判断が苦手だという弱点がありました。すべての情報を均等に圧縮しようとして、重要な固有名詞などを書き漏らしてしまうのです。
そこで登場したのがMambaです。Mambaは、ただノートを取るだけではありません。入力された内容を見て、「これは重要だから太字で書こう」「これは雑談だから無視しよう」と、動的に判断する能力(選択的スキャン)を持っていますMedium。
これにより、Mambaは従来のSSMの弱点だった「文脈に応じた情報の取捨選択」を克服しつつ、Transformerのような重い計算を避けることに成功しました。まさに、「効率的な要約ノート術」を身につけたモデルと言えるでしょう。
「要約ノート」の限界:状態の幻想
しかし、ここで冷静に考える必要があります。いくらノート術がうまくても、「原本そのもの」を参照できる能力(Transformer)には敵わない瞬間があるのではないでしょうか。
実際、SSMには「状態の幻想(The Illusion of State)」と呼ばれる理論的な指摘があります。SSMは「状態」を持っていますが、それはあくまで圧縮された情報です。例えば、複雑なパズルを解くような、過去の正確な手順を一歩も間違えずに再現しなければならないタスク(順列合成など)では、Transformerに及ばないことが分かっています。
ノートに書ききれなかった情報は、永遠に失われます。「あの時、なんて言ったっけ?」と振り返ろうとしても、SSMには振り返るべき「過去のページ」が存在しないからです。
まとめ:適材適所の時代へ
ここまでの対比を整理してみましょう。
- Transformer:全データを常に参照できる「高精度・高コスト」な全知全能型。短・中文脈や、複雑な論理パズルが得意。
- SSM (Mamba):情報を圧縮して持ち運ぶ「高効率・低コスト」な現場型。長文読解や、リソースが限られた環境(エッジAIなど)が得意。
こうして見ると、どちらが優れているかという議論よりも、「どう組み合わせるか」が重要だと気づきます。次章では、この両者の強みを掛け合わせた「ハイブリッドモデル」が、具体的にどのような技術的工夫で実現されているのか、その舞台裏に迫ってみましょう。単に混ぜるだけではうまくいかない、意外な落とし穴があるようです。
ハイブリッドの真価:位置情報の統合とシステムレベルの最適化
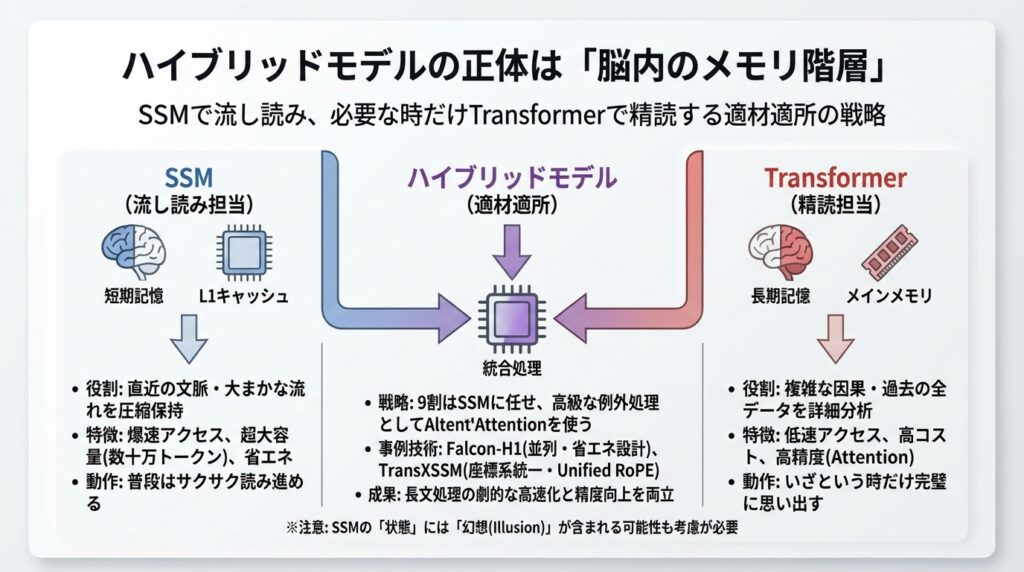
前のセクションで、Transformerの「精密さ」とSSM(State Space Model)の「身軽さ」を組み合わせれば最強のモデルができるのではないか、という話をしました。
しかし、現実はそう単純ではありません。どうやら、ただこの二つを混ぜ合わせるだけでは、期待したような性能は出ないようなのです。まるで、スポーツカーのエンジンをトラクターに載せても速く走れないように、「混ぜ方」と「足回り」の調整が決定的に重要であることが、最新の研究で分かってきました。

本セクションでは、ハイブリッドモデルが真価を発揮するために必要な技術的なブレイクスルーと、実際にFalcon-H1やTransXSSMといったモデルが達成した驚くべき成果について深掘りしてみます。
「混ぜるだけ」では動かない理由:言葉が通じない二人
なぜ、単純な合体ではうまくいかないのでしょうか? その最大の壁は、「位置情報の扱い方」の違いにあるようです。
Transformerは、文章内の単語の位置を「1ページ目の3行目」といった絶対的な座標(位置エンコーディング)で把握しようとします。一方、SSMは時間の流れに沿ってデータを処理するため、相対的な順序を重視します。この二つを無造作に繋げると、お互いの「場所の感覚」がズレてしまい、モデル全体が混乱してしまうのです。
この問題を解決したのが、Unified RoPE(統一された回転位置埋め込み)という技術です。これは、TransformerとSSMの両方が理解できる「共通の地図」を持たせるようなものです。
具体的には、TransXSSMというモデルの研究において、この統一手法を導入した結果、劇的な改善が見られました。
- トレーニング速度:従来比で42.3%高速化
- 推論速度:29.5%高速化
- 精度:言語モデリングのタスクで4%以上の向上
どうやら、お互いの長所を殺し合っていた「位置情報のズレ」を解消するだけで、これだけの潜在能力が引き出せるようなのです。
足回りの整備:カーネル最適化という隠れた主役
もう一つ、見落としがちなのが「システムレベルの最適化」です。理論上は速いはずのSSMが、実際に動かしてみると意外と遅い、ということが起こり得ます。
ある研究によると、SSMの処理時間のうち、実に55%以上がGPU上の特定の計算処理(カーネル実行)に費やされていることが判明しました。つまり、計算のアルゴリズム自体は軽くても、GPUへの命令の出し方が下手だと、データの移動待ちなどで時間がかかってしまうのです。
ここで重要になるのが「カーネル融合(Kernel Fusion)」や「並列スキャン」といった技術です。
これらは、工場のライン作業に例えると分かりやすいかもしれません。
- 最適化前:部品を一つ加工するたびに、いちいち倉庫(メモリ)に戻して、また次の部品を持ってくる。
- 最適化後(カーネル融合):部品を手元に置いたまま、複数の加工を一気に済ませてから倉庫に戻す。
この「足回り」の整備を行うことで、SSMは本来の「線形計算量」というスピードを手に入れます。実際に、最適化されたSSMは消費者向けの24GB GPUでも22万トークンという長文を処理できることが確認されています。これはハードウェアの限界をソフトウェアの工夫で突破した好例と言えるでしょう。
実例:Falcon-H1が叩き出した数字
では、こうした技術を統合すると、実際どれくらいのインパクトがあるのでしょうか? 最新の実装例であるFalcon-H1の成果を見てみましょう。
Falcon-H1は、Transformerの注意機構(Attention)とSSM(Mamba)を「並列(Parallel)」に配置する設計を採用しています。つまり、入力を二つの異なる脳で同時に処理して、いいとこ取りをする戦略です。
このハイブリッド化により、特に長文コンテキストにおいて、従来のTransformerモデルと比較して以下のような圧倒的な効率化を達成しました。
- 入力スループット(読み込み):最大4倍
- 出力スループット(生成):最大8倍
「8倍」という数字は、単なる改善レベルを超えています。これまで1分かかっていた文章生成が7〜8秒で終わる感覚です。また、最大256Kトークン(書籍数十冊分)の文脈を扱えるため、膨大なマニュアルを参照しながら回答するRAG(検索拡張生成)のようなタスクで、実用的な速度とコストを実現できるようになりました。
私たちはどう使うべきか
こうした技術革新は、私たちユーザーに何をもたらすのでしょうか?
- 「待たされない」長文AIの実現:これまで「長文を読ませると返答まで数分かかる」のが当たり前でしたが、ハイブリッドモデルはその待ち時間を大幅に短縮します。
- 現実的なコストでの運用:高価なH100などのGPUを大量に用意しなくても、手元の比較的安価なGPUで長文タスクが回せるようになります。
ただし、導入にあたっては注意も必要です。前のセクションで触れたように、SSMには「厳密な状態追跡が苦手」という特性があります。そのため、Falcon-H1のようなモデルを採用する場合でも、「自分のタスクは長文の要約なのか、それとも一字一句間違えられないコード生成なのか」を見極める必要があります。
次章では、この「SSMが苦手なこと」つまり理論的な限界点について、もう少し踏み込んで考えてみましょう。ここを理解しておかないと、思わぬ落とし穴にはまるかもしれません。
「銀の弾丸」ではない:SSMの理論的限界と使いどころ

ここまでSSM(状態空間モデル)やハイブリッドモデルの可能性について、かなり前向きな話をしてきました。22万トークンを処理できるとか、8倍速くなるとか聞くと、「もう全部これに置き換えればいいんじゃないか?」という気がしてきますよね。
でも、正直なところ、技術の世界に「銀の弾丸(あらゆる問題を解決する万能薬)」は存在しません。どうやらSSMにも、明確な弱点があるようなのです。
本セクションでは、SSMが抱える少し衝撃的な理論的課題と、それを踏まえた上で「どこで使うのが正解なのか」という実務的な判断基準について、一緒に考えていきたいと思います。
名前負け? 「状態の幻想」という指摘
「状態空間モデル(State Space Model)」という名前を聞くと、何をイメージしますか? 私なら「過去の状態(State)を完璧に保持して、それを次に繋げていく賢いシステム」を想像します。
ところが、最近の研究で「その期待はちょっと高すぎるかもしれない」という指摘が出てきました。それが、The Illusion of State in State-Space Models(状態空間モデルにおける状態の幻想)という論文です。
この研究によると、Mambaを含む多くのSSMは、理論的にはTransformerと同じ計算のクラス(TC0)に属しており、「本質的に順番を追って計算しなければならない問題」を解くのが苦手だというのです。
少し抽象的なので、ゲームに例えてみましょう。
- 得意なこと:「このステージの敵の配置パターンを覚えて、次の敵を予測する」ような、なんとなくの傾向や文脈を掴むこと。
- 苦手なこと:「チェスの駒の動きを最初から最後まで一手も間違えずに追跡して、現在の盤面を再現する」こと。
もし途中で「AがBに移動した」という情報を一つでも圧縮して忘れてしまったら、盤面は崩壊しますよね。SSMはデータを効率よく圧縮するのが得意な反面、こうした「厳密な状態追跡(State Tracking)」においては、私たちが期待するほどの「記憶力」を持っていない可能性があるのです。
「勝てる領域」と「避けるべき領域」の境界線
では、私たちはこの技術をどう使い分ければいいのでしょうか? どうやら、タスクの性質によって「勝てる領域」と「避けるべき領域」がはっきり分かれてきそうです。
1. 避けるべき領域:厳密さが命のタスク
もしあなたのタスクが、「手順の省略が許されない」「論理の積み上げが全て」であるなら、SSM単独での利用は慎重になった方がいいかもしれません。
- 複雑なコードの実行シミュレーション:コードの変数がどう変化したかを厳密に追うタスク。
- 論理パズルや数学の証明:一つでも前提を取りこぼすと結論が変わってしまう問題。
- 厳密なエンティティ追跡:長い物語の中で「誰がどのアイテムを今持っているか」を正確に管理し続けるようなタスク。
これらは、SSMが得意とする「圧縮」と相性が悪い領域です。どうしてもSSMを使いたい場合は、前のセクションで紹介したようなTransformerとのハイブリッド構成にするか、入力に依存して状態遷移を変える(IDS4など)といった特別な工夫が必要になるでしょう。
2. 勝てる領域:文脈と効率がモノを言うタスク
一方で、世の中の多くの仕事はそこまで厳密ではありません。むしろ、「全体像を把握すること」や「膨大な情報からトレンドを掴むこと」が求められる場面で、ハイブリッドモデルは圧倒的な強さを発揮します。
① 長文RAG・ドキュメント解析
社内の膨大なマニュアルや議事録から回答を作るタスクです。ここでは「一言一句の完全な記憶」よりも、「数万文字の中から関連する文脈を拾ってくる能力」が重要です。Mamba系モデルは長文処理のスループットが高く、Transformerと組み合わせることで精度のバランスも取れるため、最も推奨される領域です。
② 時系列予測(トレンド × ノイズ)
株価やセンサーデータのような時系列データも有望です。S2TXというモデルは、長期的なトレンドをMambaで捉え、短期的な急変動をTransformerで捉えるという分業を行うことで、高い予測精度を記録しました。まさに「適材適所」の勝利です。
③ 画像・ビデオ処理(広域 × 詳細)
画像の解像度を上げるようなタスクでも、ハイブリッドが効きます。Contrastというモデルは、画像の全体的な構成をSSMで捉えつつ、細かいピクセルの整合性をTransformer(と畳み込み)で補うことで、高性能を達成しています。
まとめ:道具を選ぶのは人間
結局のところ、SSMもハイブリッドモデルも、使い手次第ということでしょうか。
「新しいから全部これにする」のではなく、「自分の扱っているデータは、多少の圧縮を許容する自然言語なのか、それとも厳密な論理式なのか」を見極めること。それが、失敗しないAI導入の第一歩になりそうです。
自然言語には幸いにして「冗長性(言い回しを変えても意味が通じる)」があります。だからこそ、SSMのような圧縮技術がこれほどまでに効果を発揮するのかもしれません。
さて、ここまで見てくると、これからのAI開発の方向性が少し見えてきた気がしませんか? どうやら未来は、「万能な一つの巨大モデル」ではなく、異なる得意分野を持つパーツを組み合わせる形に進んでいきそうです。
次が最後のセクションです。この「組み合わせ」の思想が、今後のAIアーキテクチャ全体をどう変えていくのか、結論としてまとめてみたいと思います。
結論:単一モデルから「メモリ分業」アーキテクチャへ
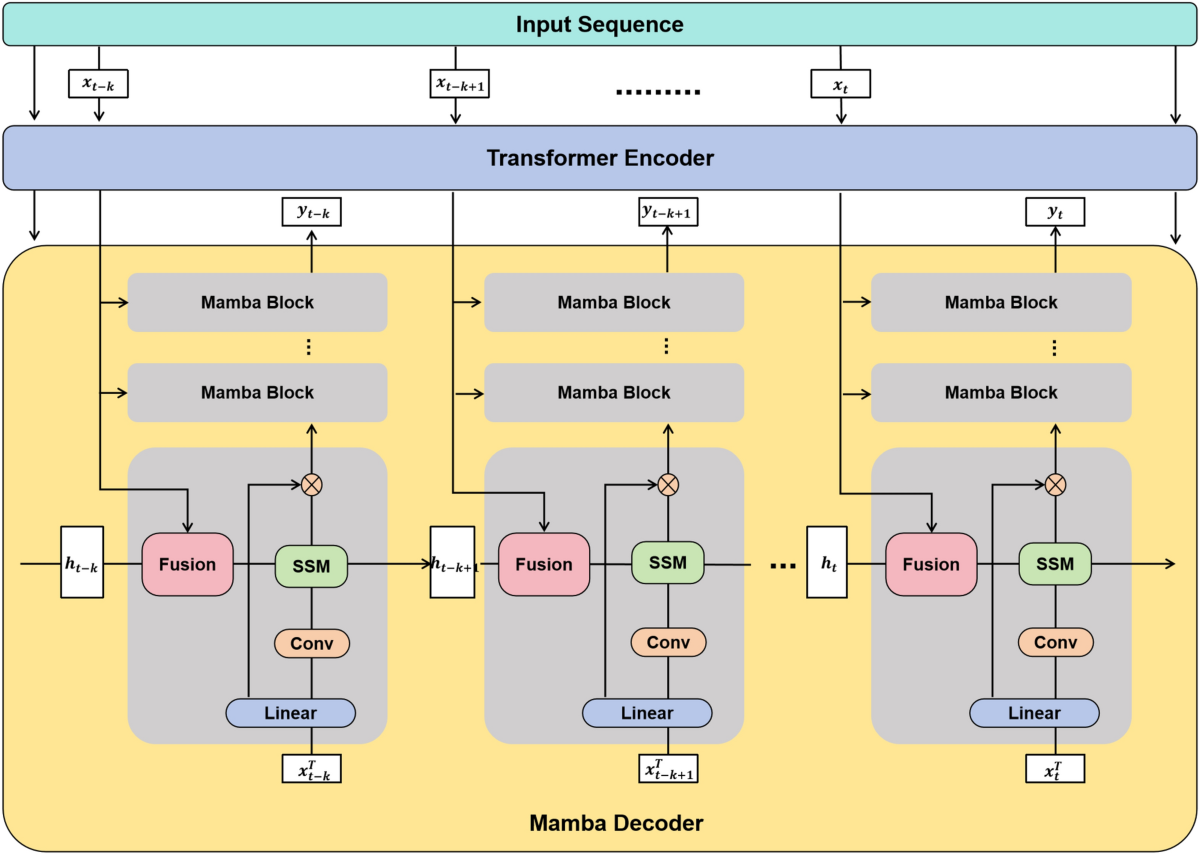
ここまで、トランスフォーマーの限界と状態空間モデル(SSM)の台頭、そしてそれらを組み合わせたハイブリッドモデルの可能性について見てきました。これらの情報を整理しているうちに、どうやら私たちは、AI開発における大きな転換点に立っているような気がしてきました。
これまでは「トランスフォーマーこそが最強であり、モデルを巨大化すれば全て解決する」という、ある種の”力技”の時代でした。しかしこれからは、もっと賢く、効率的に役割を分担する「メモリ分業」の時代へと入っていくのではないでしょうか。
「万能な天才」から「最強のチーム」へ
少し極端な例え話をさせてください。これまでのAI開発は、一人の人間に「全ての過去の資料を丸暗記し、かつ瞬時に計算し、完璧な文章を書け」と要求しているようなものでした。それがトランスフォーマーの巨大化競争です。しかし、これには膨大なエネルギー(コスト)がかかります。
一方で、今回のハイブリッドモデルの議論で私たちが目撃しているのは、「得意なことは得意な人がやる」というチームプレイへのシフトです。
- トランスフォーマー(司令塔):ここぞという時の複雑な推論や、目の前の情報の深い分析を担当。「短期・高解像度」な処理が得意。
- SSM / Mamba(書記係):膨大な過去のデータを要約し、文脈を途切れさせずに保持し続ける。「長期・低コスト」な処理が得意。
実際、この「分業」の考え方は、自然言語処理以外の分野でも成果を上げ始めています。
例えば、先程述べたように時系列予測の世界ではS2TXというモデルが、長期トレンドをMambaで、短期的な変動をトランスフォーマーで処理することで、高い性能を出しています。画像の分野でも、Contrastというモデルが、画像の全体構成(広域)とピクセルの細部(詳細)を分担して処理しています。
どうやら、単一のアーキテクチャで全てを解決しようとするよりも、異なるメモリ機構を適材適所で組み合わせる方が、結果として高性能で効率的なシステムを作れるようです。これは、私たちが仕事で役割分担をするのと全く同じですね。
足回り(システム全体)の整備が勝敗を分ける
もう一つ、忘れてはいけない重要な視点があります。それは、いくら優秀なモデル(エンジン)を作っても、それを動かすためのシステム(車体や道路)が古ければ、性能は発揮できないということです。
SSMやハイブリッドモデルは、理論上は非常に高速ですが、それを現実のハードウェア(GPU)上で動かすためには、「推論エンジン」側の対応が不可欠です。
実際、vLLMのような主要な推論ライブラリの開発現場では、SSMを効率的に動かすための議論が白熱しています。これまではトランスフォーマー向けに最適化されていたメモリ管理やキャッシュの仕組みを、SSMの特性に合わせて作り直す必要があるからです。
また、GPUのメモリ(SRAM/DRAM)をどう使い分けるかといった、非常に低レイヤーな「カーネル最適化」が、実用速度に数倍の差を生むことも分かっています。
Falcon-H1の実例では、こうした最適化を含めた設計により、長文入力時の処理速度(スループット)を最大4倍、出力速度を最大8倍にまで引き上げました。
つまり、これからのAI開発における競争力は、単に「最新のモデルを使うこと」だけでなく、「ハードウェアや推論エンジンを含めたシステム全体をどう最適化するか」にかかってくるのではないでしょうか。
実際にどのようにSSMを使えるのでしょうか。もしあなたが、モデルレベルで、社内の膨大なドキュメントを検索するRAGシステムや、長い対話ログを扱うチャットボットを開発しているなら、迷わずハイブリッドモデルやSSMの検証(PoC)を始めることをお勧めします。
まずは24GB程度の一般的なGPUを用意して、実際に数万トークンのデータを流し込んでみてください。「あれ、こんなにサクサク動くの?」という驚きが待っているかもしれません。
一方で、金融取引の厳密なログ解析や、複雑なコード生成のようなタスクであれば、まだトランスフォーマーの堅実な力が必要になるでしょう。
重要なのは、流行りのモデルに飛びつくことではなく、「自分の解きたい課題にとって、最適な『記憶の形』はどれか?」を問い続けることです。
技術は日々進化し、古い常識を覆していきます。でも、その技術を使ってどんな価値を生み出し、どう人間をエンパワーするかを決めるのは、いつだって私たち自身の役割です。
調査手法について
こちらの記事はグラフAIリサーチプラットフォームのSnorbeを使って作られています。Snorbeは研究開発・新規事業向けの調査テーマに応じた幅広い項目のオートリサーチや、ナレッジグラフの構築、構造化レポートの生成ができるAIリサーチツールです。
Screenshot
調査したいテーマを入力するだけで、AIが深堀りすべき観点や広げるべき調査項目をレコメンドしながら、自動でリサーチを進めます。収集した情報はナレッジグラフとして蓄積され、未調査領域(ホワイトスペース)を可視化しながら調査の網羅性を高めていけます。
また、観点マトリクスを30秒・構造化レポートを10分で自動生成する機能があり、出典付きのレポートをMarkdown/PDF形式でエクスポートできます。調査の元データも保存されるため、ファクトチェックや社内共有も容易です。
ご利用をご希望の方は、こちらよりお申し込みください。
また、グラフAIを活用した社内ナレッジ管理や、研究開発・新規事業のリサーチ支援、セルフホスト導入のご相談も受け付けています。お困りの方はお気軽にご連絡ください。
市場調査やデスクリサーチの生成AIエージェントを作っています 仲間探し中 / Founder of AI Desk Research Agent @deskrex , https://deskrex.ai


コメント