
「待つ」時代の終わり:拡散モデルがテキスト生成にもたらす破壊的変革

生成AIを使って仕事をしているとき、画面上のカーソルが点滅し、文字がポツポツと表示されるのをぼんやり眺めている時間がないでしょうか。プロンプト(指示)を投げてから回答が完了するまでの数秒から数十秒。このわずかな「待ち時間」に、私は最近、強烈な違和感を覚えるようになりました。どうやら、私たちの思考を分断していたこの「待つ」時代は、技術の進化によって唐突に終わりを迎えそうです。
本章では、従来のAIとは一線を画す「拡散モデル」を応用したテキスト生成AIが、私たちの仕事や開発のプロセスをどのように変えてしまうのかを解説します。この技術を知っておくことで、あなたは今後登場する爆速のAIツールを、「単なる時短ツール」としてではなく、「思考を拡張するパートナー」として使いこなす準備ができるはずです。
人間の読解速度を置き去りにする「毎秒2,000トークン」の世界

まず、衝撃的な数字を見てみましょう。私たちが普段使っているChatGPTなどの対話型AIは、速いものでも1秒間に50〜100トークン程度(日本語で約30〜70文字)の速度で文字を生成します。これでも人間がタイピングするよりはずっと速いですが、目で追える速度です。
ところが、現在研究が進んでいる「拡散モデル」を応用した新しいAIは、次元が違います。
例えば、Google DeepMindが発表した実験モデルGemini Diffusionは、毎秒1,000〜2,000トークンという速度を記録しました。
また、Inception AIが開発したMercury Coderというコード生成AIは、NVIDIA H100という高性能な計算機上で毎秒1,000トークン以上を生成すると報告されており、ByteDanceのSeed Diffusionに至っては毎秒2,146トークンという数値を叩き出しています。
これがどれくらい速いか想像できるでしょうか。
一般的な成人の読書速度は、英語で1分間に200〜300語程度と言われています。1秒あたりに換算すると約3〜5語です。つまり、最新の拡散言語モデル(DLM)は、人間が読む速度の100倍から300倍以上のスピードでテキストを生成するのです。スマートフォンで長い記事を一瞬でスクロールし終えるような感覚で、長文のレポートや複雑なプログラムコードが「パッ」と画面に出現する。そんな世界が目前に迫っています。
「生成」から「瞬時の具現化」へ
この圧倒的な速度は、単に「作業が速く終わる」以上の意味を持ちます。それは、私たちがAIを使うときの「試行錯誤(トライ・アンド・エラー)のループ」そのものを変質させてしまうからです。
これまでのチャットボットとの対話は、次のようなリズムでした。
- 私たちが質問を入力する
- AIが考え、文字を生成するのを待つ
- 生成された文章を読み、修正点を見つける
- 「もっと短くして」と指示し、また生成を待つ
この「待つ」時間が、私たちの集中力を削いでいました。しかし、生成が一瞬で終わるなら、このリズムは劇的に変わります。
- 私たちがアイデアを入力する
- 瞬時に形になる
- 「ここを変えて」と操作する
- 瞬時に全体が書き換わる
思考した瞬間に結果が表示されるため、脳の処理が待ち時間によって中断されません。まるで自分の頭の中にあるイメージが、そのまま画面に投影されているような感覚になるはずです。Googleの研究者たちは、この特性を活かして、テキストやコードを貼り付けて最小限の指示で瞬時に書き換えるInstant Editという機能を提案しています。これは、「AIに生成をお願いする」という体験から、「AIを使って思考を直接編集する」という体験へのシフトを意味します。
試行錯誤のコストがゼロになる
仕事において「失敗」が怖くなくなる、という点も重要です。
例えば、プログラマーが新しい機能を実装しようとするとき、従来は「AIにコードを書かせて、エラーが出たら修正させる」という往復に数分かかっていました。一回の試行に時間がかかると、私たちは無意識に「一回で正解を出したい」と考え、慎重に指示文(プロンプト)を練り込んでしまいます。これでは本末転倒です。
しかし、拡散言語モデルのように毎秒数千トークンで出力されるなら、失敗のコストはほぼゼロになります。「とりあえず書いてみて」「やっぱりこのパターンも」「あ、こっちの設計も試して」といった指示を、息をするように連発できるようになります。
実際、Mercury Coderのようなモデルは、開発者が思考する速度に合わせてコードを補完・生成することを目指して設計されています。質を高めるために時間をかけるのではなく、圧倒的な回数の試行錯誤を瞬時に繰り返すことで、結果的に質の高い成果物にたどり着く。そんな新しい働き方が可能になるのです。
なぜ、そんなに速いのか?
読者の皆さんは、「なぜ急にそんなに速くなったの?」と不思議に思うかもしれません。実は、これまでのAI(ChatGPTなど)と、この新しいAI(拡散モデル)では、文章を作る「手順」が根本的に異なります。
- これまでのAI(自己回帰モデル): 「昔々、」→「ある、」→「ところに、」と、前の言葉に続く言葉を一つずつ順番に予測して積み上げていました。丁寧な一筆書きのようなもので、並列処理(同時に計算すること)が難しく、どうしても時間がかかります。
- 新しいAI(拡散モデル): 最初に「ノイズ(意味のない文字列)」を画面全体にばら撒き、それを一気に整えて文章にします。全体を同時に処理できるため、コンピュータの計算能力をフル活用でき、爆発的な速度が出せるのです。
この「一筆書き」から「全並列推敲」への転換こそが、速度革命の正体です。次章では、この直感に反するユニークな仕組みについて、もう少し詳しく、しかし誰にでもわかる比喩を使って掘り下げていきましょう。どうやら、この仕組みを知ることは、AIの「癖」を理解し、上手に使いこなすための近道になりそうです。
一筆書きの限界を超える:拡散言語モデル(DLM)の「全並列推敲」メカニズム

前章でお伝えしたように、拡散言語モデル(DLM)は人間が読む速度の100倍以上という驚異的なスピードでテキストを生成します。しかし、なぜこれほどまでに速いのでしょうか。そして、なぜGoogleやスタートアップ企業がこぞってこの技術に賭けているのでしょうか。
どうやらその秘密は、コンピュータの計算能力の問題というより、そもそも「文章をどうやって作るか」という作法そのものの違いにあるようです。私たちが普段使っているChatGPTのようなAIと、この新しいAIの違いを知ることは、今後私たちがAIをどう使い分けるべきかを理解する上で、非常に重要なヒントになります。
従来のAIは「即興スピーチ」の達人

現在主流のAI(大規模言語モデル:LLM)は、専門的には「自己回帰(Autoregressive)モデル」と呼ばれています。少し難しそうな名前ですが、やっていることはシンプルで、「左から右への一筆書き」です。
例えば、「昔々、あるところに」と書いたら、AIはこれまでの文脈だけを見て、次にくる確率が最も高い「おじいさんが」という言葉を予測します。それが決まったら、また次の一語を予測する。これを延々と繰り返しています。
これは人間で言えば、台本なしの即興スピーチをしている状態に近い気がしませんか?
一度口に出してしまった(生成してしまった)言葉は、基本的には取り消せません。また、文の後半で素晴らしいオチを思いついても、それに合わせて冒頭の話を修正することはできません。常に「過去」から「現在」に向かって、後戻りできない一本道を進んでいるのです。
この仕組みには、2つの弱点があります。
- 並列処理ができない: 前の言葉が決まらないと次の言葉が計算できないため、どれだけ高性能なコンピュータ(GPU)を使っても、処理を「手分け」してスピードアップすることが難しいのです。
- 全体整合性が苦手: 書きながら考えているため、長文になると前の内容と矛盾したり、論理が迷子になったりすることがあります。
拡散モデルは「霧の中から全体が現れる」
一方で、今回注目している拡散モデル(Diffusion Model)のアプローチは、これとは全く異なります。あえて名付けるなら、「全並列推敲(すいこう)」とでも呼ぶべきプロセスです。
拡散モデルがテキストを生成する様子は、まるで濃い霧がサーッと晴れて、景色が一気に見えてくるような感覚に近いでしょう。
具体的な手順はこうです。
- 最初はノイズだらけ: まず、画面全体にデタラメな文字列(ノイズ)をばら撒きます。まだ意味のある文章ではありません。
- 一斉に修正する: AIは全体を眺めて、「ここはこう直したほうが文章らしくなるな」という修正を、すべての箇所で同時に行います。
- 推敲を繰り返す: この「全体を見渡して一斉に直す」というステップを数回から数十回繰り返します。すると、最初は砂嵐のようだったノイズが、徐々に鮮明な文章へと収束していきます。
Googleの研究チームは、このプロセスを「粗から密へ(Coarse-to-Fine)」と表現しています。最初から完成品を一文字ずつ置くのではなく、全体の大まかな下書きを一瞬で作り、それを猛烈なスピードで何度も推敲して仕上げるのです。
なぜ、この仕組みが圧倒的に速いのか?
この「全並列推敲」の最大の利点は、現代のコンピュータ(GPU)の得意技をフル活用できる点にあります。
GPUは、単純な計算を大量に同時にこなすのが得意な「並列処理のモンスター」です。
従来の一筆書きモデルでは、前の文字が決まるまで次の計算が待たされるため、せっかくのGPUの能力を持て余していました。しかし、拡散モデルなら「1文字目も、100文字目も、1000文字目も、全部まとめて一斉に計算」できます。
例えるなら、100問のテストを解くときに、従来モデルが「1人の天才が1問ずつ順番に解いている」のに対し、拡散モデルは「100人の秀才が一斉にそれぞれの担当問題を解いている」ようなものです。これなら、どんなに長い文章でも、計算リソースさえあれば一瞬で生成できる理由がわかります。
「未来」を見て「過去」を直す力
さらに面白いのは、拡散モデルが持つ「非因果的推論(Non-causal reasoning)」と呼ばれる能力です。
一筆書きのAIは、常に「過去(前の単語)」からしか影響を受けられません。しかし、全体を同時に扱える拡散モデルは、「未来(文の後ろの方にある単語)」の情報を使って、「過去(文の前の単語)」を修正することができます。
例えば、ミステリー小説を書くとして、「犯人はヤスだった」という結末(未来)が決まった瞬間に、冒頭の伏線(過去)をそれに合うように書き換えることができるのです。Inception AIのMercury Coderがコード生成に強いのも、この特性のおかげでしょう。プログラムコードは、最後の閉じカッコ一つ抜けただけで全体が動かなくなります。上から順に書くよりも、全体構造を見ながら整合性を取る「推敲型」のアプローチの方が、論理的に正しいコードを書きやすいのではないでしょうか。
私たちは「使い分け」の時代へ
こうして見てくると、拡散言語モデルは単に「速いChatGPT」ではないことがわかります。
- 自己回帰モデル(従来): 文脈の流れを重視する、物語やチャットのような「続きを書く」タスクが得意。
- 拡散モデル(次世代): 全体の整合性が重要な、コード生成、要約、定型的なレポート作成、そして推敲・編集タスクが得意。
どうやら私たちは、ツールを用途に合わせて選ぶ段階に来ているようです。
次章では、この拡散モデルの特性を最大限に活かした具体的なモデル、Googleの「Gemini Diffusion」やInception AIの「Mercury Coder」が、実際のベンチマークでどのような性能を叩き出しているのか、その実力に迫ります。「生成」から「編集」へとシフトする新しいUIの姿が見えてくるはずです。
Google Gemini DiffusionとMercury Coder:爆速モデルが切り開く「生成」から「編集」へのシフト
前章では、拡散モデルが「霧の中から全体を一気に浮かび上がらせる」ような仕組みで動いていることを見てきました。では、その仕組みを使って実際に作られたAIは、私たちの目の前でどのような挙動を見せるのでしょうか。
どうやら、単に「返事が速いチャットボット」が登場するだけではなさそうです。Googleやスタートアップが発表した最新モデルの動きを追っていると、私たちがAIとどう付き合うか、その「作法」自体が根本から変わってしまうような予感がしてきました。
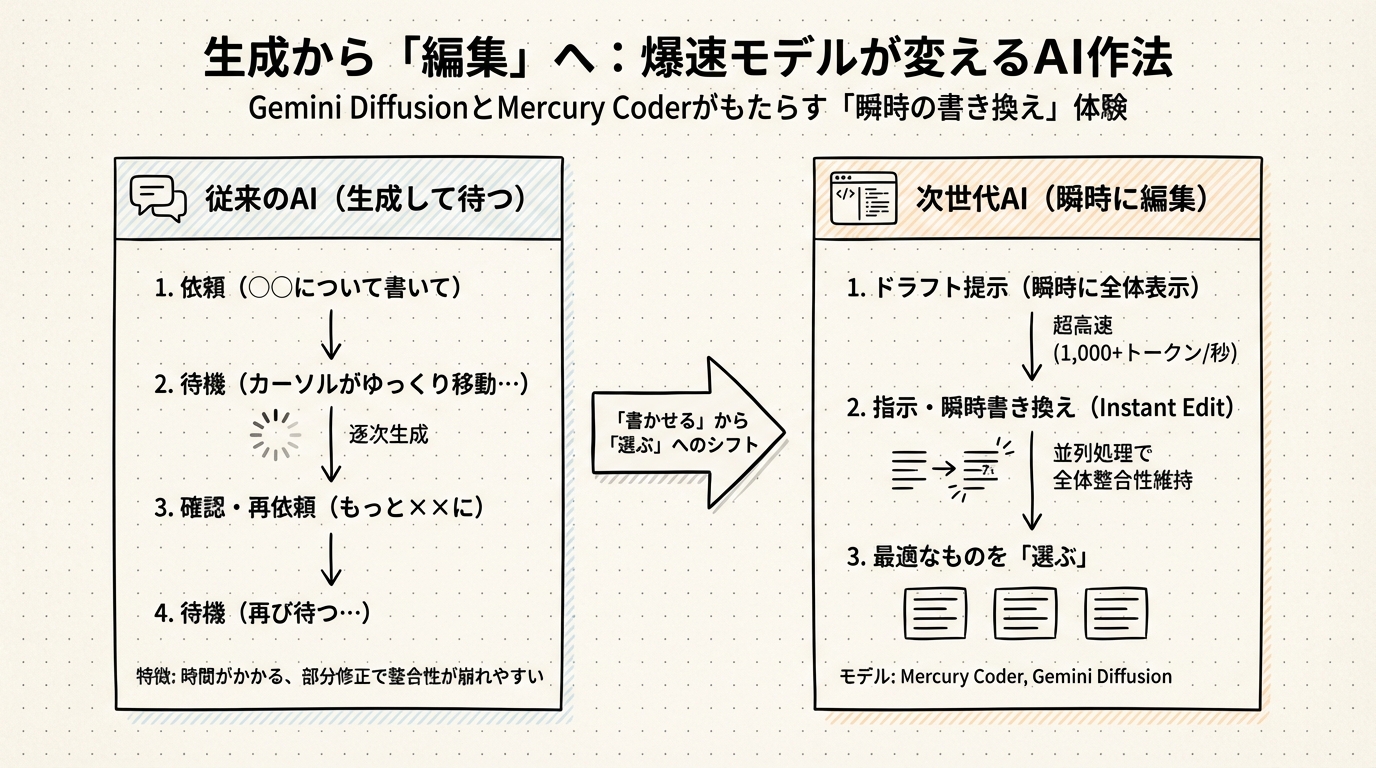
「書かせる」から「選ぶ」へのシフト
最新モデルの動向を見ていると、私たちの仕事の進め方が、「ゼロからAIに書かせる」スタイルから、「AIが出したドラフトを一瞬で直させる」スタイルへとシフトしていく未来が見えてきます。
例えば、企画書を作るシーンを想像してみてください。
これまでは、AIに構成案を作らせて、それを人間が時間をかけて手直ししていました。
これからは、手元にあるメモ書きをAIに放り込み、「企画書にして」と指示すれば一瞬で形になり、「やっぱりトーンを柔らかく」と言えば、また一瞬で別のバージョンが表示される。私たちは生成されたものを待って読むのではなく、次々と提示されるバリエーションの中から最適なものを「選ぶ」ことが主な仕事になるのかもしれません。
VentureBeatの記者がGemini Diffusionを試した際、簡単なアプリのUIを作る指示に対して、2秒未満で動作するインターフェースが生成されたと報告しています。これだけの速度があれば、試行錯誤の回数を劇的に増やせます。「作る」コストが限りなくゼロに近づくことで、「どれにするか決める」という人間の判断力が、より重要になってくる気がします。
チャット欄が消える日?
さて、ここで一つ問いかけです。
もしAIが「待つ必要がない」ほど速くなり、対話よりも「書き換え」が得意になったとしたら、私たちが今使っている「チャット形式のUI」は、本当に正解なのでしょうか?
現在のAIブームは「チャットボット」から始まりました。しかし、拡散モデルの登場は、AIのインターフェースを、LINEのような吹き出し画面から、GoogleドキュメントやVS Codeのような「エディタ画面」へと回帰させる可能性があります。左側にチャット欄があるのではなく、エディタ上の文字が、自分の思考と同期するかのようにリアルタイムで変形していく。そんな未来です。
ただ、ここで冷静になる必要があります。「速い」ということは、それだけコンピュータのリソースを食うということでもあります。また、初動(最初の1文字目が出るまで)は少し遅いという弱点も指摘されています。
次章では、この夢のような技術を実際に私たちの手元に届けるために、エンジニアたちがどのような壁(コストや初動の遅さ)と戦っているのか、その裏側に迫ります。どうやら、ただ速いだけでは実用化にはまだ遠いようです。
「速いが、初動が重い」の壁を越える:実用化に向けたTTFT短縮とサービングコスト最適化の最前線
前章で、拡散モデルが「一瞬で全体を書き換える」魔法のような体験をもたらすとお話ししました。しかし、ここで正直な話をしなければなりません。この魔法には、実用化を阻む2つの高く分厚い壁が存在します。
それは、「初動の遅さ」と「お金(コスト)」の問題です。
どうやら、拡散モデルは「走り出せば世界最速だが、スタートダッシュが苦手なスプリンター」のような性質を持っているようです。この章では、エンジニアたちがこの気難しいスプリンターをどうやって手なずけようとしているのか、その最前線の戦いを見ていきましょう。
最初の1文字が出るまでの「タメ」
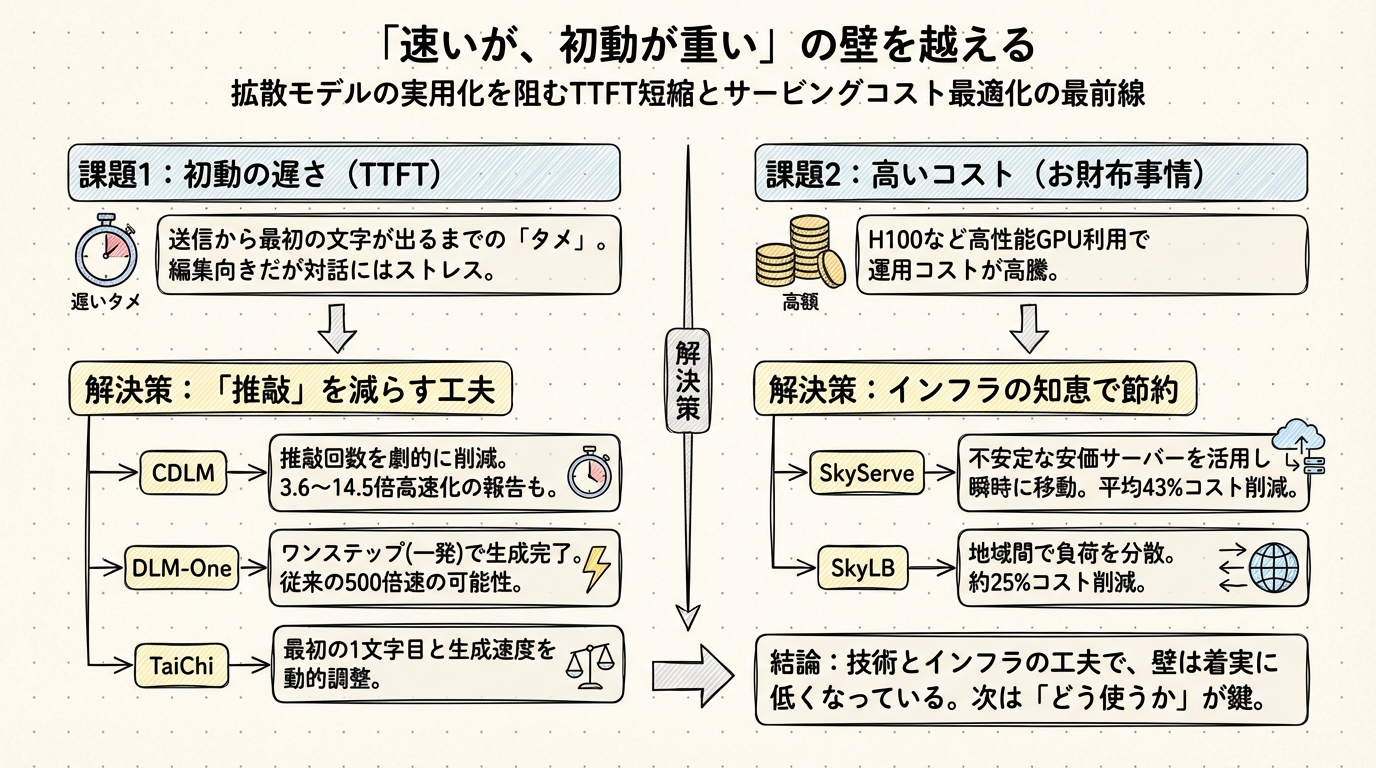
生成AIを使っているとき、私たちが最もストレスを感じるのはいつでしょうか? それは「送信ボタンを押してから、最初の文字が表示されるまでの待ち時間」ではないでしょうか。エンジニア用語でTTFT(Time To First Token)と呼ばれるこの指標こそが、拡散モデルの最大の弱点です。
従来のChatGPTのようなAI(自己回帰モデル)は、いわば「考えながら話す」タイプです。文全体の構成が決まっていなくても、とりあえず「えー、それはですね…」と最初の単語を吐き出し始めることができます。だから、私たちは「即レス」されたと感じます。
一方、拡散モデルは「頭の中で推敲を重ねてから、完成原稿を一気に読み上げる」タイプです。ノイズだらけの状態から全体を何度も修正し、納得いく形になって初めて私たちに見せてくれます。そのため、送信ボタンを押してから結果が出るまでに、どうしても一瞬の「タメ(沈黙)」が生まれてしまうのです。
「1秒間に2,000文字書ける」といっても、書き始めるまでに3秒待たされたら、チャットボットとしては「遅い」と感じてしまうかもしれません。これが、拡散モデルが「対話」よりも「編集」に向いている理由の一つでもあります。
「何度も書き直さない」という解決策
この「タメ」をなくすために、研究者たちは常識外れのアプローチを取り始めました。「推敲に時間がかかるなら、推敲の回数を減らせばいいじゃないか」という発想です。
CDLM(Consistency Diffusion Language Models)という技術がその筆頭です。
通常、拡散モデルは何十回、何百回と書き直し(デノイズ)を行って文章を完成させます。しかしCDLMは、「最終的な完成形がどうなるか」をAIにあらかじめ予測させることで、この書き直しステップを劇的に減らそうとしています。実験では、推論にかかる時間を3.6倍から14.5倍も短縮できたという報告もあります。
さらに極端な例として、DLM-Oneという技術も登場しています。これは名前の通り、「ワンステップ(一発)」で生成を完了させようという野心的な試みです。もしこれが実用化されれば、従来の500倍近い速度で処理が完了する可能性すらあります。
また、TaiChiというシステムは、「最初の1文字目(TTFT)」と「その後の生成速度(TPOT)」のバランスを動的に調整することで、ユーザーを待たせない工夫を凝らしています。
どうやら、「じっくり推敲する」という拡散モデルの美徳を、あえて「直感で一発書きする」方向にチューニングすることで、弱点を克服しようとしているようです。
「速い」は「高い」? サービングコストの壁
もう一つの壁は、切実な「お財布事情」です。
H100のような最新鋭のGPUを使って「毎秒1,000トークン」を叩き出すということは、裏側でとてつもない計算パワーを使っていることを意味します。Googleの研究者も、拡散モデルの課題としてサービングコスト(運用コスト)の高さを挙げています。
いくら便利なAIでも、使うたびに数百円かかるとしたら、誰も仕事では使えません。この「高嶺の花」をどうやって民主化するか。ここで登場するのが、クラウド上の「訳あり物件」を活用する知恵です。
「不安定なサーバー」を乗りこなすSkyServe
クラウドの世界には「スポットインスタンス」と呼ばれる仕組みがあります。これは、AmazonやGoogleが「今は余っているから安く貸すけど、必要になったらすぐ取り上げるよ」という条件で貸し出しているサーバーです。定価の半額以下で使えることもありますが、いつ強制終了されるかわからないため、安定したサービスには使えないのが常識でした。
しかし、SkyServeという技術は、この常識を覆しました。
SkyServeは、世界中のあちこちにある「安いけど不安定なサーバー」を監視し、ある場所のサーバーが止まりそうになったら、瞬時に別の場所の安いサーバーへ処理を逃がすという曲芸のようなことをやってのけます。
これにより、高いGPUを定価で借り続けるのと比べて、平均で43%ものコスト削減に成功したというデータがあります。また、地域をまたいで負荷を分散させるSkyLBという技術でも、25%程度のコスト削減が見込まれています。
拡散モデルという「大飯食らい」のAIを養うために、インフラ側でも涙ぐましい節約術が開発されているのです。
壁は崩れつつある
「初動が遅い」「コストが高い」。
この2つの壁は、かつては拡散モデルの実用化を阻む決定的な要因に見えました。しかし、アルゴリズムの工夫(CDLMなど)とインフラの知恵(SkyServeなど)によって、その壁は着実に低くなっています。
Inception AIが5,000万ドルもの資金調達に成功したのも、投資家たちが「この壁は近いうちに突破できる」と踏んでいるからでしょう。
技術的な障害が取り除かれたとき、残るのは「私たちがどう使うか」という問題だけです。速すぎて制御不能になりかねないこの「暴れ馬」を、実務の中でどう乗りこなせばいいのでしょうか?
次章では、明日月曜日から使える具体的な「生存戦略」について考えます。ただ速く生成するだけでなく、その速度を「品質」に変換するための、新しい仕事の回し方を提案します。
月曜日からの生存戦略:速度を「品質」と「検証」に変換する新しいワークフロー

ここまで拡散モデルの話をしてきて、ふとあることに気づきました。私たちはAIに「速さ」を求めるとき、無意識に「ラクをすること」ばかり考えていないでしょうか?
「1秒で終わるなら、残りの時間は遊べるじゃん」と。
でも、どうやら拡散モデルがもたらす未来は、そう単純な「手抜き」の世界ではないような気がしてきます。むしろ、浮いた時間をすべて「品質」に再投資することで、人間一人ひとりの生産性を極限まで高める、そんなストイックな生存戦略が見えてきました。
未来の月曜日の朝、我々がデスクに座った瞬間から使える、具体的なアクションプランを想定してみましょう。
1. 「書かせる」のではなく「直させる」:Instant Editの活用
まず、AIへの指示出し(プロンプト)の流儀がガラリと変わりそうです。
これまでは「〇〇についての記事を書いて」「ログイン画面のコードを書いて」と、ゼロから生成を依頼するのが一般的でした。しかし、拡散モデルが得意なのは、ノイズ(不完全な状態)から完成形を作り出すプロセスです。これは実務で言えば「推敲」や「編集」に当たります。
明日からは、書きかけの仕様書や、バグだらけのコード、あるいは箇条書きのメモ書きを「ノイズ」に見立ててAIに放り込み、「これを完成品にリファインして」と頼むワークフローに切り替えてみてください。
Googleが示したGemini Diffusionの「Instant Edit(瞬時の書き換え)」機能は、まさにこの転換を象徴しています。
- 従来(自己回帰モデル):「ゼロから書いて」→ AIが考えながらゆっくり生成 → 人間が時間をかけて直す
- これから(拡散モデル):「この下書きを直して」→ AIが一瞬で全体を整形 → 人間が確認して完了
AIを「ライター」としてではなく、「超高速な編集者」として使う。自分で書いた拙い文章やコードを、一瞬でプロレベルに引き上げさせる。この「編集」へのシフトこそが、拡散モデルの能力を最も引き出せる使い方ではないでしょうか。
2. 浮いた時間で「自己検証(Self-Correction)」を回す
次に、圧倒的な速度を「信頼性」に変換するアプローチです。
生成速度が10倍、20倍になるということは、人間が1回試行する間に、AIは10回、20回試行できるということです。この余裕を単なる時短に使わず、「検証」に使いましょう。
最近の研究では、モデル自身に間違いを修正させる能力が注目されています。例えば、拡散モデルであるMercury Coderを使ってコードを書く際、単に出力して終わりにするのではなく、次のようなループを自動化するのです。
- 生成:コードを高速生成する
- 検証:別のAI(またはテストプログラム)がエラーをチェックする
- 修正:エラーがあれば、拡散モデルがその部分を一瞬で修正する
従来の遅いモデルでは、これをやると日が暮れてしまいましたが、毎秒1,000トークンを超える速度Inception Labsがあれば、ユーザーがコーヒーを一口飲む間にこのループを数回回せます。これを「Draft-and-Verify(生成と検証)」のワークフローと呼びます。
結果として私たちの手元に届くのは、単に「速く書かれたコード」ではなく、「既に検証済みの動くコード」になるわけです。これが速度を品質に変えるということです。
3. 開発者・PM向けの判断基準:TTFTとTPOTの分離
もしあなたがAIシステムの開発者やプロダクトマネージャー(PM)なら、明日からのシステム設計で意識すべき指標が変わります。これまでは漠然と「レスポンス速度」を見ていたかもしれませんが、これからはTTFT(最初の1文字が出るまでの時間)とTPOT(全部書き終わるまでの時間)を明確に分けて管理する必要があります。
前述の通り、拡散モデルは「初動(TTFT)」が少し苦手ですが、一度出始めれば「完了(TPOT)」までは爆速です。この特性を理解した上で、SLO(サービスレベル目標)を次のように使い分けてみてはどうでしょうか。
- チャットボット(対話):ユーザーを待たせられないので、TTFT重視。ここはまだ従来の自己回帰モデル(Gemini Flashなど)が強い領域かもしれません。
- 裏方処理(要約、翻訳、コード変換):ユーザーがじっと画面を見ていないタスクなら、TTFTは数秒遅くても構いません。その代わり、膨大な処理をTPOT重視で一瞬で終わらせる拡散モデルの独壇場です。
適材適所。拡散モデルは「バックグラウンドで大量の仕事を片付ける職人」として配置するのが、今のところ賢い戦略と言えそうです。
最後に:私たちは「監督」になる
こうして見ると、拡散モデルがもたらす変化は、単に「AIが速くなる」ことだけではありません。人間が「手を動かす時間」が極端に減り、代わりに「何を作るか決め(ディレクション)」、「出来上がったものを評価する(チェック)」時間が増える。つまり、私たちはプレイヤーから監督へと、強制的に昇格させられるようなものです。
月曜日、会社に行ったら、まずは手元のタスクを見渡してみてください。「これをAIに一瞬で直させるには、どんな下書き(ノイズ)を用意すればいいか?」
そう考え始めた瞬間、あなたはもう新しいワークフローの中にいます。
さあ、準備はいいでしょうか? 爆速の世界が、すぐそこまで来ています。
調査手法について
こちらの記事はデスクリサーチAIツール/エージェントのDeskrex.AIを使って作られています。DeskRexは市場調査のテーマに応じた幅広い項目のオートリサーチや、レポート生成ができるAIデスクリサーチツールです。
調査したいテーマの入力に応じて、AIが深堀りすべきキーワードや、広げるべき調査項目をレコメンドしながら、自動でリサーチを進めることができます。

また、ワンボタンで最新の100個以上のソースと20個以上の詳細な情報を調べもらい、レポートを生成してEmailに通知してくれる機能もあります。
ご利用をされたい方はこちらからお問い合わせください。
また、生成AI活用におけるLLMアプリ開発や新規事業のリサーチとコンサルティングも受け付けていますので、お困りの方はぜひお気軽にご相談ください。
市場調査やデスクリサーチの生成AIエージェントを作っています 仲間探し中 / Founder of AI Desk Research Agent @deskrex , https://deskrex.ai


コメント