
生成AIとは似て非なる「人間基盤モデル」の正体
最近、生成AIを使っていると「文章はとても流暢だけれど、こちらの意図や行動のクセまでは理解してくれていない」と感じることはないでしょうか。私たちが普段使っているチャットAIは、インターネット上の膨大なテキストを学習して「もっともらしい文章」を作る天才ですが、人間が日々直面する「どう迷い、何を選ぶか」という意思決定のプロセスそのものを理解しているわけではありません。
実は今、この「人の選択」そのものを予測しようとする新しいAI、「人間基盤モデル(Human Foundation Models)」が登場しつつあります。どうやら、AIの進化は「言葉を操る」段階から、「心をシミュレートする」段階へと進み始めているようなのです。
本セクションでは、これまでの生成AIとこの新しいモデルがどう違うのか、そしてなぜ今、文章作成ではなく「意思決定の予測」に特化したAIが必要とされているのか、その正体に迫ります。
言葉の達人と、心の理解者は違う
まず、「人間基盤モデル」とは一体何なのでしょうか。
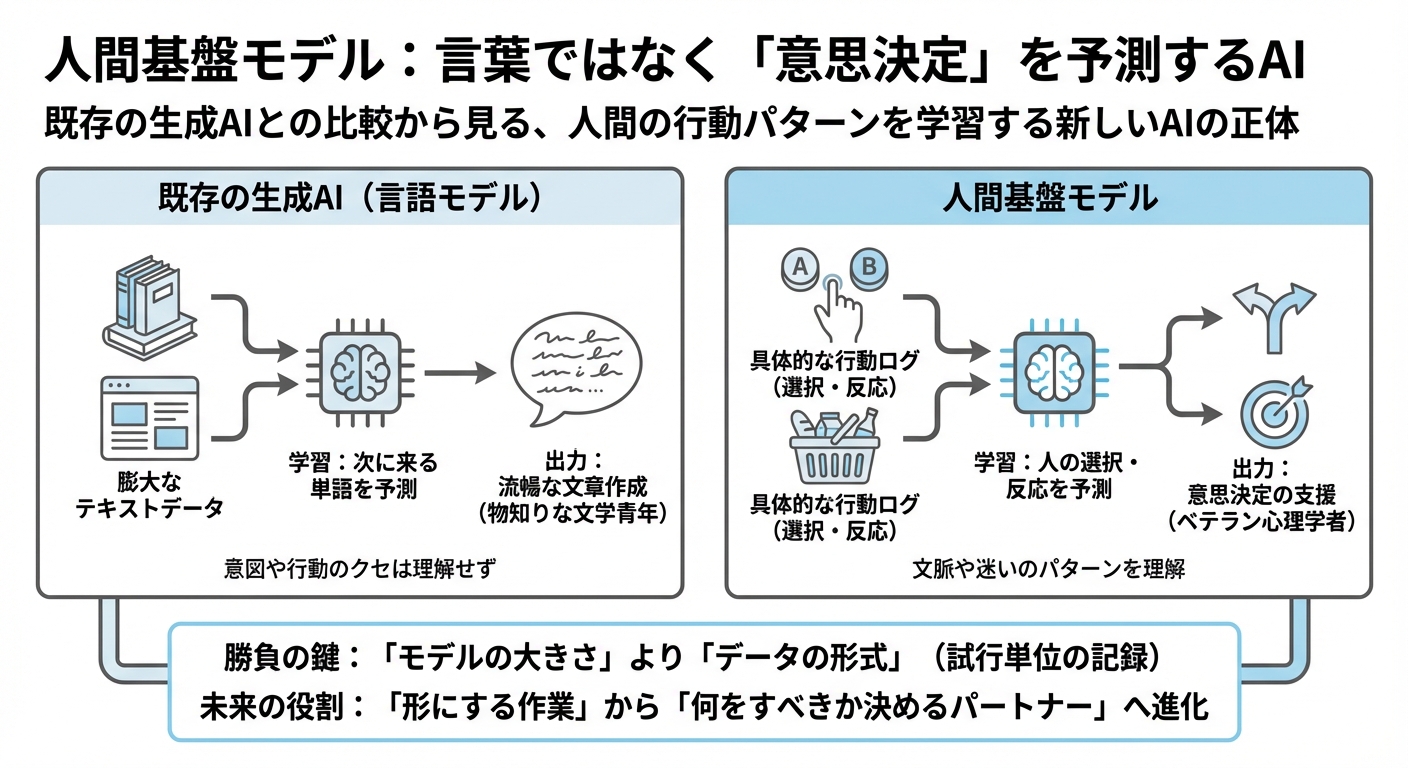
これまでのAI(汎用大規模言語モデルなど)は、主にテキストデータを読み込んで「次に来る単語」を予測するように訓練されてきました。いわば、世界中の本や記事を読み込んだ「物知りな文学青年」のようなものです。

対して、人間基盤モデルは学習するデータの中身が根本的に異なります。心理実験の結果や、経済ゲームでの行動ログといった「人がどんな状況で、どの選択肢を選んだか」という具体的な行動データを学習します。その目的は、文章を作ることではなく、「人の選択や反応を予測すること」です。代表的な例として、CentaurやBe.FMといったモデルが挙げられます。
例えるなら、人間基盤モデルは「何万人もの人々の行動パターンをひたすら観察し続けた、ベテランの心理学者」のような存在と言えるかもしれません。言葉巧みに話すことと、相手が次にどう動くかを見抜くことは、全く別の能力ですよね。
なぜ「言葉」だけでは不十分なのか
では、なぜわざわざ別のモデルを作る必要があるのでしょうか。「今のAIも十分に賢いじゃないか」と思われるかもしれません。しかし、人間の行動には「言葉の意味」だけでは説明できない複雑なパターンがあります。
MIT Sloanの記事で紹介されている、非常に分かりやすい例を見てみましょう。スーパーマーケットでの買い物を想像してください。「乳糖フリーミルク(お腹に優しい牛乳)」と「普通の牛乳」は、言葉の説明や商品カテゴリとしては非常によく似ています。もしAIが言葉の意味だけで判断すれば、「この二つは関連性が高い」と考えるでしょう。
しかし、実際の買い物客の行動を見るとどうでしょうか。この二つを同時に買い物カゴに入れる人はめったにいません。むしろ、「乳糖フリーミルク」を買う人は、言葉の上では全く違う「グルテンフリーのパン」を一緒に買う傾向があります。これは「特定の健康上の理由やこだわり」という、言葉には表れにくい文脈が購買行動を決めているからです。
このように、言葉の類似性だけを見ていては、人間の実際の意思決定は見えてきません。だからこそ、言語処理ではなく、人間の「選択の共起(何と何が一緒に選ばれるか)」や「迷いのパターン」を直接扱うモデルが急務となっているのです。
「モデルの大きさ」よりも「データの形式」が勝負
この新しいAIの開発において、興味深い事実があります。どうやら勝負の鍵は、AIの頭脳の大きさ(パラメータ数)ではなく、「どのような形式でデータを学ばせるか」にあるようなのです。
例えば、Centaurというモデルは、160種類以上の心理実験データ(Psych-101)を使って訓練されました。ここで使われたのは単なる文章ではなく、「ある条件下で、参加者がAとBのどちらを選んだか」という「試行(トライアル)」単位の記録です。このデータセットには、6万人以上の参加者による1,000万回を超える選択が含まれています。
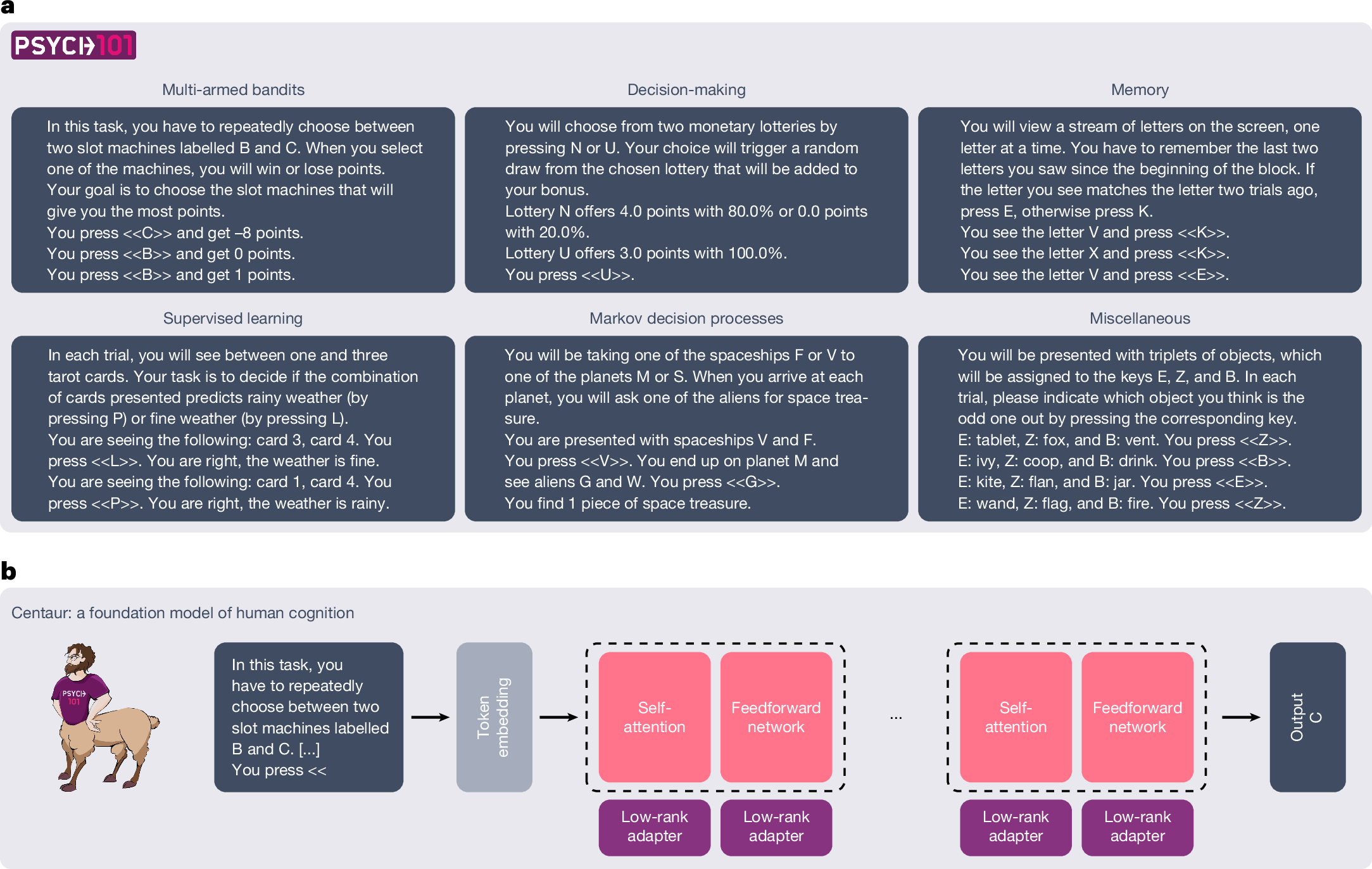
また、Be.FMというモデルは、経済ゲームやアンケート、行動科学の文献などを統合して学習しています。これにより、AIは単に知識を蓄えるのではなく、まるで人間のように「不確実な状況でどうリスクを取るか」や「相手をどれくらい信頼するか」といった行動の分布を予測できるようになります。
これらのモデルは、既存のAIをベースにしつつも、学習させるデータを「人間の行動ログ」に特化させることで、驚くべき能力を獲得しています。それは、一度も会ったことのない人の行動を予測したり、まだ実施していない心理実験の結果をシミュレーションしたりする能力です。
AIは「何を作るか」を決めるパートナーへ
これまでの生成AIは、メールの下書きや画像の生成など、私たちが「決めたこと」を形にする作業を助けてくれました。しかし、人間基盤モデルが目指しているのは、その手前にある「何をすべきか」「どちらを選ぶべきか」という意思決定そのものの支援です。
市場調査のために何万人もの人へアンケートを配らなくても、AIが仮想の顧客となって反応を返してくれる未来。あるいは、新しいアプリのボタン配置にユーザーがどう反応するかを、リリース前にAIがテストしてくれる未来。そんな世界が、すぐそこまで来ている気がしませんか?
さて、ここで一つの疑問が浮かびます。行動データを学習させただけで、なぜAIはそこまで人間らしくなれるのでしょうか? 実は、この学習プロセスによって、AIの内部では人間の脳活動に似た変化さえ起きているという報告があります。次のセクションでは、心理実験データがどのようにしてAIの「脳」を書き換え、人間らしい予測能力を与えているのか、その驚きのメカニズムに迫ります。
心理実験データがAIの「脳」を書き換える仕組み
前のセクションでは、AIに「もっともらしい言葉」を語らせるのではなく、「人間の選択」そのものを学ばせる人間基盤モデルについて触れました。
ここで一つ、面白い想像をしてみましょう。もしあなたが、全く知らないゲームの達人になりたいとしたら、どうしますか?
インターネット上の攻略サイトを端から端まで読むでしょうか。それとも、実際にプレイした何千人もの「勝ち負けの記録」をひたすら見続けるでしょうか。
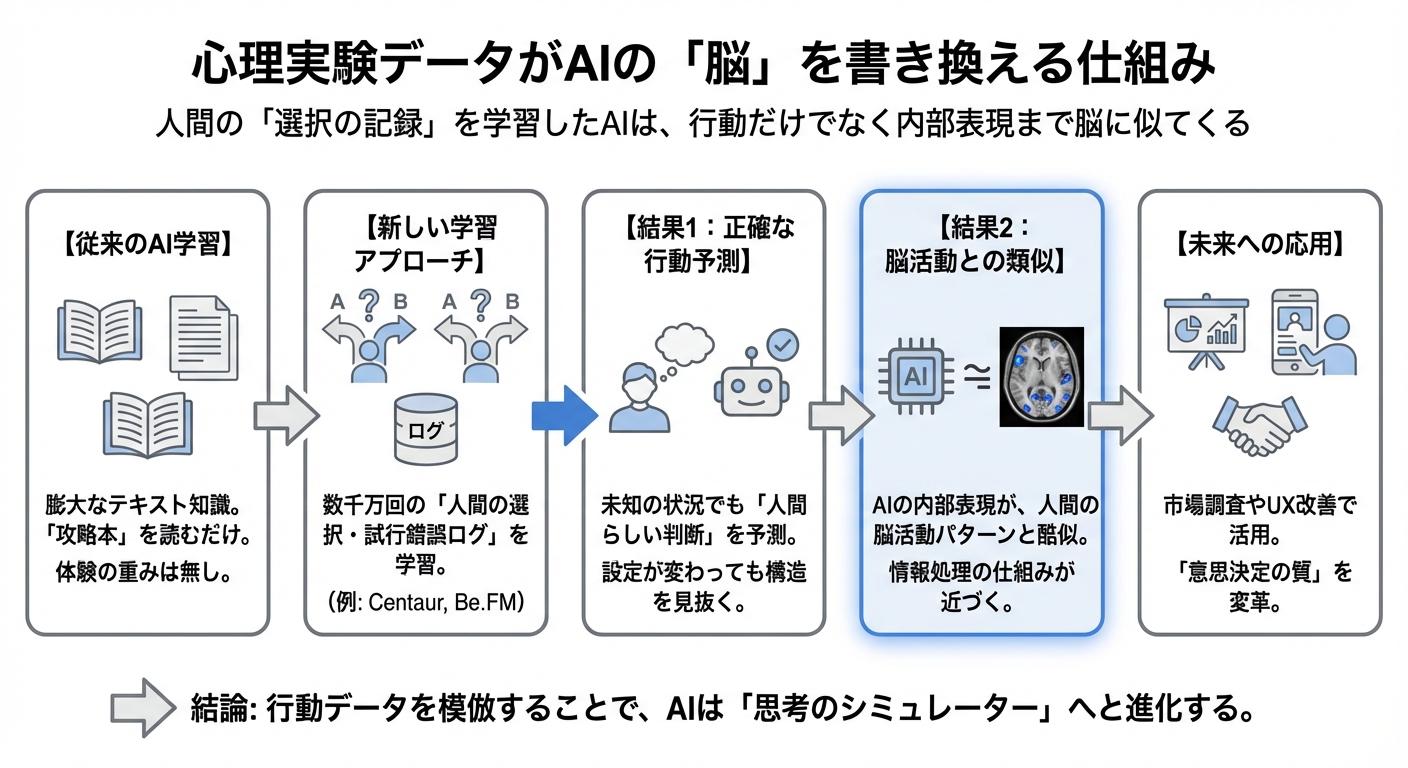
どうやら、人間基盤モデルが選んだのは後者の道のようです。そして驚くべきことに、その学習プロセスは、AIの中身(内部表現)を人間の脳活動にそっくりな形へと書き換えてしまったようなのです。
本セクションでは、先程少し紹介した最新の研究成果であるCentaurやBe.FMを例に、AIがどのようにして人間の「心」をシミュレートするに至ったのか、その仕組みを紐解いていきます。
攻略本を読むか、痛い目を見るか
私たちが普段使っている生成AI(LLM)は、いわば「世界中の攻略本を読み込んだAI」です。テキストデータを通じて、知識としては膨大な量を持っています。しかし、「実際にその場面で人間がどう動揺し、どう判断したか」という「体験の重み」は持っていません。
そこで登場したのが、前述したCentaurというモデルです。研究チームが行ったのは、AIに対する教育方針の転換でした。彼らはAIにテキストを読ませる代わりに、「Psych-101」と呼ばれる巨大な心理実験データセットを与えました。
ここには、160種類以上の心理学実験に参加した6万人以上の人々による、1,000万回を超える「選択の記録」が含まれています。
例えば、「確率の違う2つのスロットマシンのどちらを引くか」といった単純な賭けから、複雑な記憶課題まで、人間が悩み、選び、成功したり失敗したりした「試行(トライアル)」の履歴を徹底的に学ばせたのです。
これは、AIに「痛い目を見た経験」や「うまくいった感覚」を、何千万回分も擬似体験させることに近いのかもしれません。その結果、何が起きたのでしょうか。
未知の状況でも「人間ならこうする」が分かる
驚くべきことに、こうして鍛えられたAIは、一度も会ったことのない参加者の行動までピタリと予測できるようになりました。
さらに興味深いのは、実験の設定(ストーリー)を変えても、その予測能力が落ちなかったことです。元々の実験が「宇宙船に乗って惑星を選ぶ」という設定だったものを、「魔法の絨毯に乗って場所を選ぶ」という全く違う話に変えても、AIは「人間ならこの状況でどう迷うか」という構造を見抜いて、正確な予測を続けました。
これは、AIが表面的な単語(宇宙船や絨毯)に惑わされず、その奥にある「意思決定のルール」そのものを獲得したことを示唆しています。まるで、RPGで何度もダンジョンに潜ったベテランプレイヤーが、初めて見るボスモンスターを前にしても「あ、こいつはこのタイミングで攻撃してくるな」と直感で分かるようなものでしょうか。
行動を真似たら、脳まで似てしまった
さらに、この研究には続きがあります。実はここが一番の驚きポイントなのですが、行動データで訓練されたAIの中身を調べてみると、人間の脳活動(fMRIデータ)との整合性が高まっていたのです。
研究チームは、AIを脳波データで直接訓練したわけではありません。ただひたすら「人間はどう選ぶか」という行動ログを学ばせただけです。それなのに、AIの内部表現(計算処理の途中経過)が、人間が同じ課題を行っているときの脳のスキャン画像と似たパターンを示すようになったのです。
どうやら、「人間のような行動」を突き詰めて再現しようとすると、情報処理の仕組みも自然と「人間の脳」に近づいていく、という不思議な現象が起きているような気がしてきませんか?
これは私の推測ですが、AIは膨大な試行錯誤のデータから、「報酬」や「リスク」、「過去の記憶」といった、意思決定に本当に必要な変数だけを効率よく圧縮して持つようになったのではないでしょうか。その結果として、機能的に脳と似た振る舞いをするようになったのかもしれません。
経済ゲームで「人間臭さ」をインストールする
心理実験だけでなく、もっと社会的な場面でもこの技術は応用されています。前述したBe.FMというモデルは、MobLabというプラットフォームから得られた経済ゲームのデータを学習しています。
経済ゲームとは、「自分のお金を相手にどれくらい分けるか」といった、協力や裏切りの判断を迫る実験です。人間はここで、必ずしも自分の利益最大化のためだけに動くわけではありません。「公平でありたい」と思ったり、「相手に良く思われたい」と考えたりします。
Be.FMは、こうした複雑な駆け引きのデータを学ぶことで、人間特有の「非合理的な判断」や「性格による振る舞いの違い」までシミュレートできるようになりました。もはやAIは、計算高いロボットではなく、「空気を読んだり、情に流されたりする人間」の代理人になりつつあるのです。
AIの脳書き換えがもたらす未来
心理実験や経済ゲームの「試行データ」を学習させることで、AIは単なるテキスト処理マシンから、人間の認知プロセスを模倣する「思考のシミュレーター」へと変貌を遂げました。
では、この「人間の心が分かるAI」を、私たちのビジネスや社会に持ち込むと、一体どんなことが可能になるのでしょうか?
例えば、1万人の仮想モニターに一瞬で新製品を試してもらったり、ユーザーがアプリを削除する直前の「心の揺らぎ」を検知したりできるかもしれません。
次のセクションでは、この技術が市場調査やUX改善といった現場で具体的にどう役立つのか、コスト削減だけではない「意思決定の質」を変えるインパクトについて掘り下げていきます。
市場調査からUXまで、「迷い」を予測してビジネスを変える
前のセクションでは、AIが心理実験データを学ぶことで、どうやら人間の脳に近い反応を示すようになってきたことについてお話ししました。
では、この「人間の心が分かるAI」は、私たちの仕事の現場で一体どう役立つのでしょうか。
正直なところ、「AIが人間に代わって仕事をする」という話はもう聞き飽きた方も多いかもしれません。しかし、人間基盤モデルがもたらす変化は、単なる自動化とは少し違う種類のインパクトになりそうな気がしています。
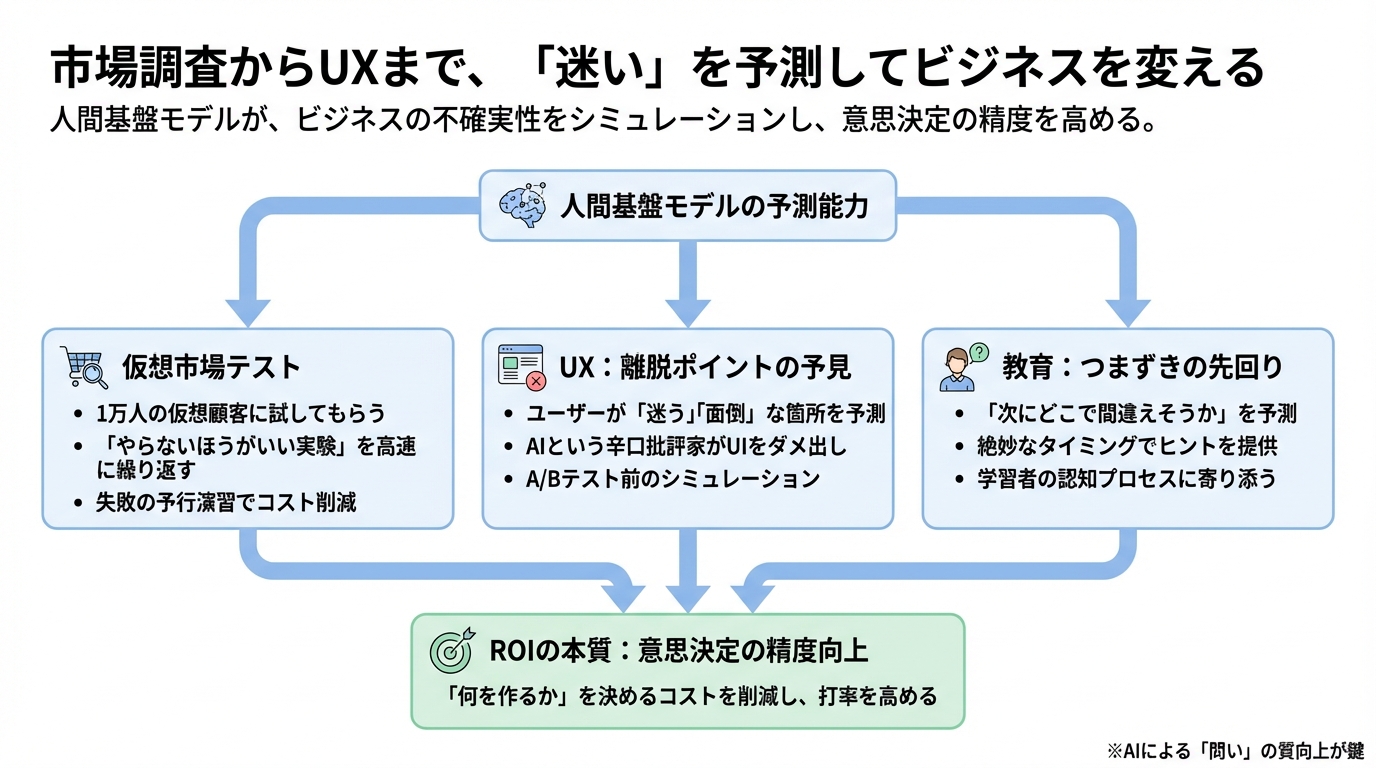
それは、私たちがビジネスで最も頭を抱える「人間がどう動くか分からない」という不確実性を、事前にシミュレーションできるようになる、ということです。
ここでは、市場調査、UX(ユーザー体験)、そして教育の現場で始まっている具体的な変化を見ながら、この技術がどうビジネスの意思決定を変えるのかを考えてみましょう。
1万人の仮想顧客に「試してもらう」

新しい商品を出すとき、私たちはよくアンケートやグループインタビューを行います。しかし、これには「お金と時間がかかる」以上に、もっと根本的な問題があります。それは、人間はアンケートに本音を書かない、あるいは自分がどう行動するかを自分でも分かっていないということです。
例えば、「乳糖フリーの牛乳」と「普通の牛乳」はテキスト上の説明は似ていますが、実際の購買行動では「乳糖フリー牛乳」と「グルテンフリーパン」の方がセットで買われやすい、といった行動のクセがあります。言葉の類似度だけで予測しようとする従来のAIでは、こうした「実際の選択」を見落としてしまうのです。
そこで、人間基盤モデルの出番です。
もし、実際の人間ではなく、行動データで訓練された何千、何万という「仮想のエージェント」に新商品を試してもらえたらどうでしょうか。
実際に、ある化粧品会社の事例では、フランスのZ世代やミレニアル世代の美容消費者をモデルにした1万人の仮想エージェントを生成し、新製品への反応をシミュレーションするという試みが行われています。彼らは単に設定されたペルソナ通りに喋るだけではありません。過去の購買履歴やソーシャルメディアでのトレンド反応といった「行動の記憶」を持っており、仮想の店舗で買い物をし、仲間と情報を交換し、製品に対する態度を変えていきます。
これなら、現実の市場に出して失敗する前に、デジタルの箱庭の中で「やらないほうがいい実験」を何度でも高速に繰り返すことができます。コスト削減はもちろんですが、それ以上に「失敗の予行演習」ができる価値は計り知れません。
ユーザーが離脱する「迷い」を予見する
Webサービスやアプリを作っている方なら、ユーザーがどこでつまづき、どこで嫌になって画面を閉じてしまうかを知るために、A/Bテストを繰り返していることでしょう。これもまた、「実際にユーザーに見せてみないと分からない」という限界との戦いです。
しかし、Centaurのようなモデルがあれば、このプロセスも変わりそうです。
このAIは、人間が不確実な状況でどう意思決定するかを徹底的に学んでいます。そのため、新しいアプリのオンボーディング(使い始めの案内)画面を見せたときに、「ここでユーザーは迷うだろう」「このステップで面倒だと感じるだろう」という離脱ポイントを、人間が高い確率で予測するように言い当てることができるのです。
例えば、フィンテック(金融技術)の分野では、借入の申し込み画面で「金利のスライダー」をどう動かすとユーザーが不安を感じるか、あるいはリスクを感じて離脱するかをシミュレーションするリスクエンジンとしての活用が期待されています。
実際のユーザーを使ってテストをする前に、AIという「辛口の批評家」にUIを触らせて、ダメ出しをしてもらう。そんな開発フローが当たり前になるかもしれません。
「つまずき」を先回りする教育
教育の分野でも、この「予測能力」は強力な武器になります。
優れた教師は、生徒が問題を解いている様子を見て、「あ、この子は次のステップで計算ミスをしそうだな」と直感で分かるといいます。人間基盤モデルは、この「つまずきの予感」をシステム上で再現できる可能性があります。
学習者の過去の回答パターンや、似たような特性を持つ他の学習者のデータを元に、AIが「次にどこで間違えそうか」を予測します。そして、生徒が実際に間違える前に、絶妙なタイミングでヒントを出したり、問題の難易度を調整したりするのです。
これは単に正解を教えるだけのAIとは違います。学習者が「どこで迷い、どう考えるか」という認知プロセスそのものに寄り添う、適応型の家庭教師のような存在です。
ROIの本質は「何を作るか」を決めるコスト
こうして見てくると、人間基盤モデルの本当の価値(ROI:投資対効果)は、単なる作業の自動化やコスト削減だけではないことが分かってきます。
ビジネスにおいて最も高くつくコストとは何でしょうか。
それは、作る作業そのものではなく、「何を作るべきか」「どう売るべきか」を迷っている時間、そして「誰も欲しがらないものを作ってしまう」という失敗のコストではないでしょうか。
人間基盤モデルは、この意思決定の精度(打率)を劇的に高めてくれる可能性があります。
Neptuneのレポートでも、AI導入の成功は技術的なスペックよりも「ビジネスの中核目標にいかに集中するか」にかかっていると指摘されています。
どうやら、私たちはAIを使って「答え」を作るだけでなく、「問い」の質を高める段階に来ているようです。
では、実際にこの技術を自社に導入しようとしたとき、私たちは何から始めればいいのでしょうか。次のセクションでは、導入の際に多くの人が陥りがちな「モデル選び」の罠と、本当に重要な「評価定規」の話をして、このシリーズを締めくくりたいと思います。
導入のカギは「モデル」ではなく「評価定規」にある
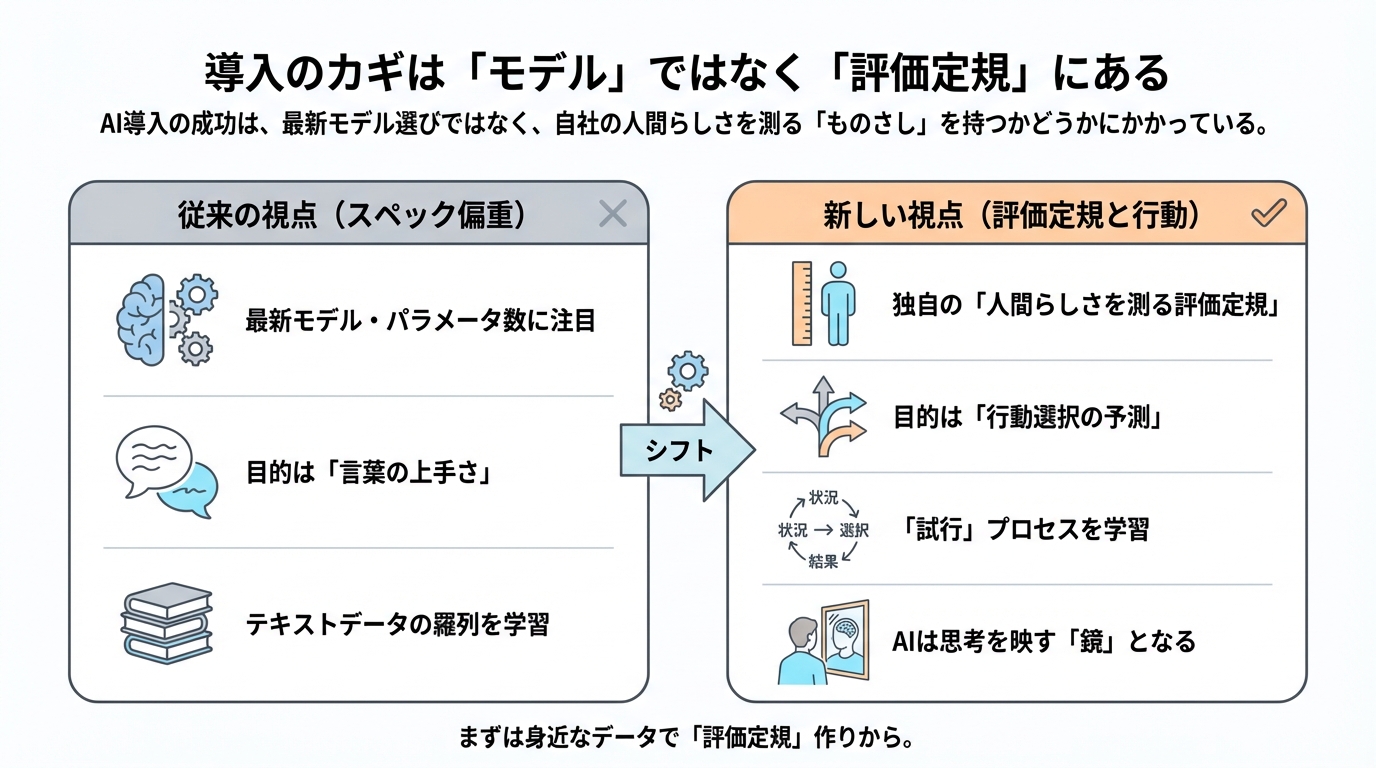
ここまで、人間基盤モデルが私たちのビジネスにどのような変化をもたらすかを見てきました。では、実際に「よし、うちの会社でも導入してみよう」となったとき、私たちはまず何から手を付けるべきでしょうか。
多くの人は、まず「どの最新モデルを使えばいいのか」や「パラメータ数(AIの脳の大きさ)はどれくらい必要か」といった、AIのスペックに目を向けがちです。しかし、色々な調査結果を見ていると、どうやらそれが最大の落とし穴になりそうな気がしてきました。
実は、この技術を使いこなすための競争力の源泉は、巨大なモデルを手に入れることではなく、もっと地味で泥臭い、「人間らしさを測る定規(ものさし)」を持っているかどうかにあるようなのです。
「言葉の上手さ」に騙されないために
なぜ、モデルの性能よりも「測り方」が重要なのでしょうか。
それは、人間基盤モデルの目的が「もっともらしい文章を書くこと」ではなく、「人間がどう選択するかを当てること」だからです。
今の汎用的な生成AI(ChatGPTなど)は、非常になめらかな文章を書きます。しかし、前のセクションでも触れたように、言葉の上手さと、実際の行動予測の正確さは別物です。
例えば、AI開発の現場では、モデルの性能を測るために「下流タスクの評価スイート」と呼ばれるテストセットを作ることが推奨されています。これは、いわばAIに対する「抜き打ち実力テスト」のようなものです。
もしあなたがECサイトの運営者なら、「過去にこの商品をカートに入れたユーザーが、次にクリックしたのはAとBのどちらか?」という自社の実際のデータを使って、AIにクイズを出してみるのです。汎用の巨大モデルが自信満々に間違える一方で、小さくても行動データで調整されたモデルの方が、驚くほど正確に正解することに気づくかもしれません。
成功している企業は、モデルを大きくすることよりも、この「自社の顧客の行動を再現できているか」を確認する評価指標(ベンチマーク)を磨くことに時間を使っているようです。つまり、自分たちだけの「評価定規」を持つことが、他社との差別化になるのです。
魔法は「テキスト」ではなく「試行」に宿る
もう一つ、導入の際に知っておくべき重要なポイントがあります。それはデータの「食べさせ方」です。
Centaurというモデルの研究で面白いことが分かりました。このモデルは、単に心理学の教科書を読ませたのではなく、「状況 → 選択 → 結果」という一連の「試行(トライアル)」のデータを徹底的に学習させました。
人間は、文章の羅列として生きているわけではありません。「こういう状況で、これを選んだら、こうなった」という経験の積み重ねで生きています。AIにも同じように、テキストの海を泳がせるのではなく、「選択の場面」を追体験させる形式でデータを学ばせる。そうすることで、AIは初めて「人間の迷い方」や「学習のクセ」を身につけることができるのです。
驚くべきことに、このように行動データで調整されたモデルは、脳活動(fMRI)のパターンまで人間と似てくるという報告もありますCentaur。どうやら、データの形式を人間に合わせることで、AIの中身も人間の認知プロセスに近づいていくのかもしれません。
明日から使える実践的導入ステップ
では、私たちは具体的にどう動き出せばいいのでしょうか。いきなり大規模なシステムを作る必要はありません。まずは小さな概念実証(PoC)から始めるのが良さそうです。
1.目的を「行動」で定義する
「顧客を理解したい」といった曖昧な言葉ではなく、「価格をAとBにしたとき、それぞれ選ばれる確率を予測したい」のように、具体的な行動と数値で目的を決めます。
2.独自の「評価定規」を作る
ここが一番の頑張りどころです。自社に眠っている「過去の失敗事例」や「意外な売れ方をした事例」のデータを引っ張り出してきて、AIへのテスト問題を作ります。「あの時の予測不能な顧客の動き」を当てられるかが、採用の基準になります。
3.ガバナンス(監視体制)を最初に組み込む
ここを後回しにしてはいけません。人間の行動を高精度に予測できるということは、裏を返せば「人間を操作できる」ということでもあります。Corvic AIのような企業は、AIがどう判断したかの監査ログを残す仕組みを最初から組み込んでいます。また、Stanford HAIも指摘するように、倫理的なバイアスがないか、プライバシーは守られているかを監視する仕組みは、技術の一部として必須になります。
AIは私たちの「鏡」になる
最後に、この人間基盤モデルという技術は、私たちに何を問いかけているのでしょうか。
これまでのAIは、私たちが面倒な作業を押し付ける「道具」でした。しかし、人間基盤モデルは、私たちの思考や行動のクセを映し出す「鏡」のような存在になる気がします。
この鏡を使えば、自分たちが作ろうとしているサービスが、本当にユーザーのためになるのか、それとも独りよがりなのかを、客観的に見つめ直すことができます。それは、「答え」を教えてくれるというよりは、私たちがより良い「問い」を見つけるのを手助けしてくれるパートナーと言えるかもしれません。
あなたの会社には、まだ活用されていない「人間の行動ログ」が眠っていないでしょうか?
もしかすると、そのゴミだと思っていたデータこそが、AIという鏡を磨き上げ、次のビジネスチャンスを映し出すための、最も重要な資源になるのかもしれません。
まずは、身近なデータを集めて、あなただけの「評価定規」を作るところから始めてみてはいかがでしょうか。
調査手法について
こちらの記事はデスクリサーチAIツール/エージェントのDeskrex.AIを使って作られています。DeskRexは市場調査のテーマに応じた幅広い項目のオートリサーチや、レポート生成ができるAIデスクリサーチツールです。
調査したいテーマの入力に応じて、AIが深堀りすべきキーワードや、広げるべき調査項目をレコメンドしながら、自動でリサーチを進めることができます。

また、ワンボタンで最新の100個以上のソースと20個以上の詳細な情報を調べもらい、レポートを生成してEmailに通知してくれる機能もあります。
ご利用をされたい方はこちらからお問い合わせください。
また、生成AI活用におけるLLMアプリ開発や新規事業のリサーチとコンサルティングも受け付けていますので、お困りの方はぜひお気軽にご相談ください。
市場調査やデスクリサーチの生成AIエージェントを作っています 仲間探し中 / Founder of AI Desk Research Agent @deskrex , https://deskrex.ai


コメント