
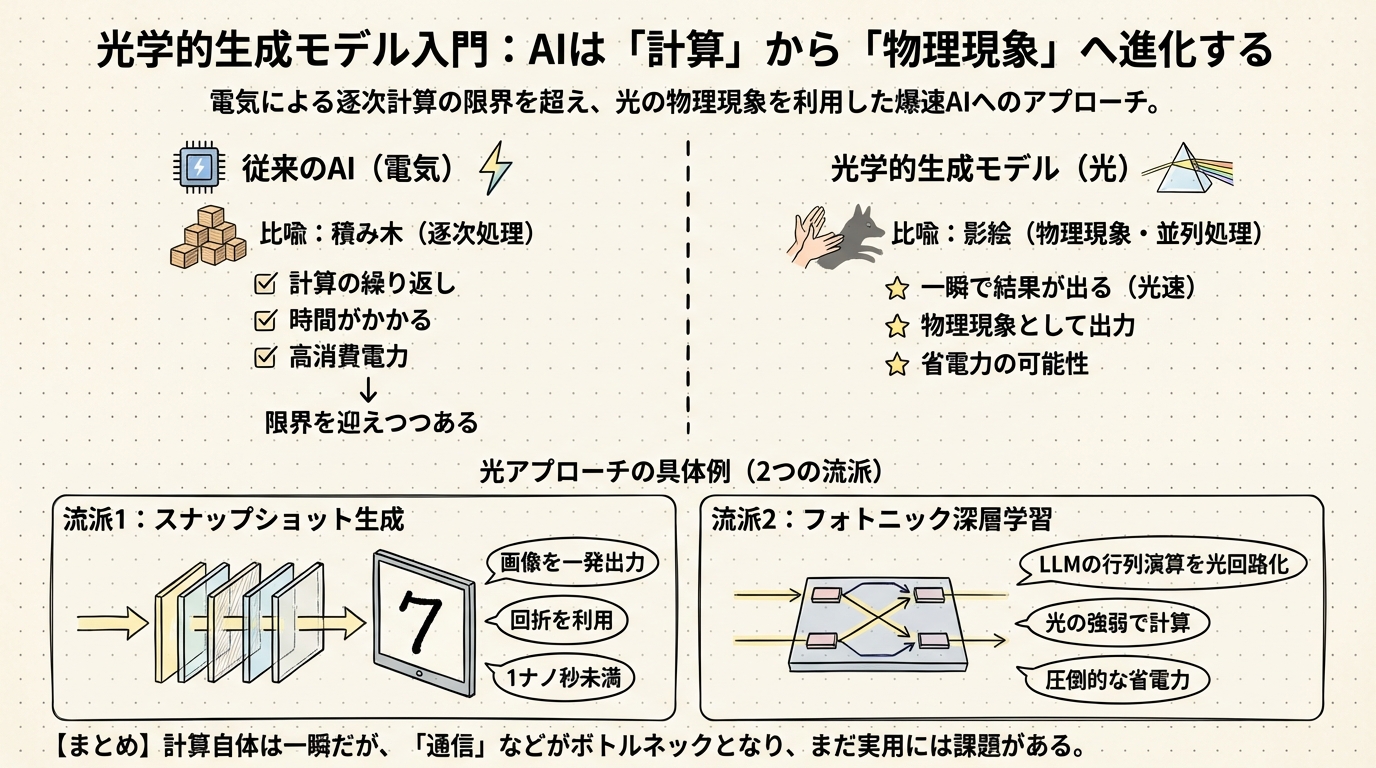
光学的生成モデル入門:AIは「計算」から「物理現象」へ進化する
最近、生成AIを使っていて「もう少し速く答えが返ってこないかな」と感じたことはありませんか? 私たちが普段使っているスマートフォンやPCの中では、電気信号が猛烈な勢いで駆け巡り、膨大な計算をこなしています。しかし、どうやらこの「電気による計算」そのものが、そろそろ限界を迎えつつあるようなのです。
そこで今、世界中の研究者が熱い視線を注いでいるのが「光」です。「光の速さでAIが動く」と聞くと、なんだかSF映画のような話に聞こえるかもしれませんが、これは単なる比喩ではありません。実は、AIの動かし方そのものを根本から変える、非常に物理的なアプローチなのです。
本章では、AIが従来の「計算」から、光という「物理現象」へと進化する過程について、スナップショット生成とフォトニック深層学習という2つの最先端アプローチを整理して解説します。これを読めば、なぜ光を使うとAIが爆発的に速くなる可能性があるのか、その仕組みが直感的にわかるようになるはずです。
「積み木」から「影絵」へ:計算の常識が変わる

まず、従来のコンピュータと、光を使った新しいAIモデル(光学的生成モデル)の決定的な違いについて考えてみましょう。
私たちが普段使っているデジタルのコンピュータは、いわば積み木を一つずつ積んでいくようなやり方で動いています。これを専門的には「逐次処理(ちくじしょり)」と呼びます。どれほど高性能なGPU(画像処理装置)を使っても、基本的には「1たす1は2、次は2かける3は…」と、ものすごい速さで順番に計算を繰り返していることに変わりはありません。
一方で、光学的生成モデルがやろうとしているのは、影絵を一瞬で壁に投影するようなことです。手でキツネの形を作ってライトの前にかざすと、一瞬で壁にキツネの影が映りますよね。このとき、光は「ここが耳で、ここが鼻で…」と計算しているわけではありません。光が手を通り抜けるという「物理現象」が起きた結果、自然と影ができるのです。
この「計算せずに、現象として答えが出る」という性質をAIに応用しようというのが、光学的生成モデルの基本的な考え方です。これを並列処理と呼びますが、デジタル計算の並列処理とは次元が違います。光がレンズやフィルタを通過するその一瞬に、すべての処理が終わってしまうのです。
流派1:スナップショット生成 —— 画像を一発で出力する
この「影絵」のアイデアを極限まで突き詰めたのが、カリフォルニア大学ロサンゼルス校(UCLA)の研究チームが開発したスナップショット光学的生成モデルです。
現在主流の画像生成AI(拡散モデルなど)は、ノイズ(砂嵐のような画像)から徐々にきれいな画像を作り出すために、何百回、何千回もの計算ステップを必要とします。デジタルで積み木を積む作業は、高品質な画像を作ろうとすればするほど時間がかかり、大量の電力を消費します。
しかし、UCLAのアプローチは全く異なります。彼らは、光が障害物の裏側に回り込む「回折(かいせつ)」という現象を利用しました。具体的には、何層もの薄い板(回折層)を並べ、そこに光を通すのです。
- まず、ランダムな光のパターン(種)を用意します。
- その光を、特殊な設計をした板に通します。
- 光は板を通るたびに複雑に曲がったり混ざったり(干渉)します。
- すべての板を通り抜けた瞬間、向こう側のスクリーンには「手書きの数字」や「ファッションアイテム」の画像が現れます。
驚くべきことに、この光が板を通り抜ける時間は1ナノ秒(10億分の1秒)未満です。UCLAの研究によると、この手法で生成された画像は、従来のデジタル計算で数百ステップかけて作ったものと統計的に同等の品質を持つことが示されています。
つまり、これまで一生懸命計算して作っていた画像を、物理現象として「一発」で出力してしまうのです。これはまさに、AIの歴史における「魔法」のような出来事ではないでしょうか。
流派2:フォトニック深層学習 —— LLMの脳みそを光にする
もう一つの流派は、もっと汎用的に「今のAIの計算を光に置き換えよう」とするアプローチです。これをフォトニック深層学習と呼びます。
ChatGPTのような大規模言語モデル(LLM)が言葉を紡ぐとき、その裏側では「行列演算」と呼ばれる巨大な掛け算と足し算の嵐が吹き荒れています。この行列演算こそが、現代のAIが最もエネルギーを使っている部分です。
「SLiM(スリム)」と呼ばれる新しい光チップの研究や、Lightmatter社のような企業の取り組みは、この行列演算を光の回路で肩代わりさせようとしています。
光の明るさや波の強さを数値に見立て、光を合流させることで「足し算」、フィルターを通すことで「掛け算」を行います。電気で計算するのではなく、光の回路の中にデータを流し込むだけで、出口から計算結果が出てくるのです。
例えば、SLiM(単層光計算チップ)の研究では、テキスト生成を行うLLM(大規模言語モデル)の一部を光回路で動かすことに成功しています。報告によると、3.45億パラメータ規模のモデルでテキスト生成タスクを行い、理想的なシミュレーションに近い精度で動作したとされています。
また、Lightmatter社が開発するプロセッサ「Envise」も、この分野の先駆けです。彼らの技術は、従来の電子チップに比べて圧倒的に低い電力で、AIの重い計算処理を実行できる可能性を示しています。
なぜ私たちはまだ「待たされる」のか?
ここまで読んで、「光ってすごい! すぐにでもスマホが爆速になるのでは?」と思われたかもしれません。確かに、光の物理現象そのものは一瞬です。UCLAの事例のように、光が素子を通過する時間は人間には知覚できないほどの速さです。
しかし、ここで一つ冷静な問いを投げかける必要があります。「じゃあ、なぜ今のChatGPTは光速で返事をくれないのでしょうか?」
実は、AIが光の速さを手に入れるためには、単に計算部分を光にするだけでは解決できない、もっと根深い問題があるようなのです。次章では、この「一瞬」を阻んでいる意外な壁と、それを突破するための現実的な解決策について深掘りしていきましょう。どうやら、鍵を握っているのは「計算」ではなく「通信」にあるようです。
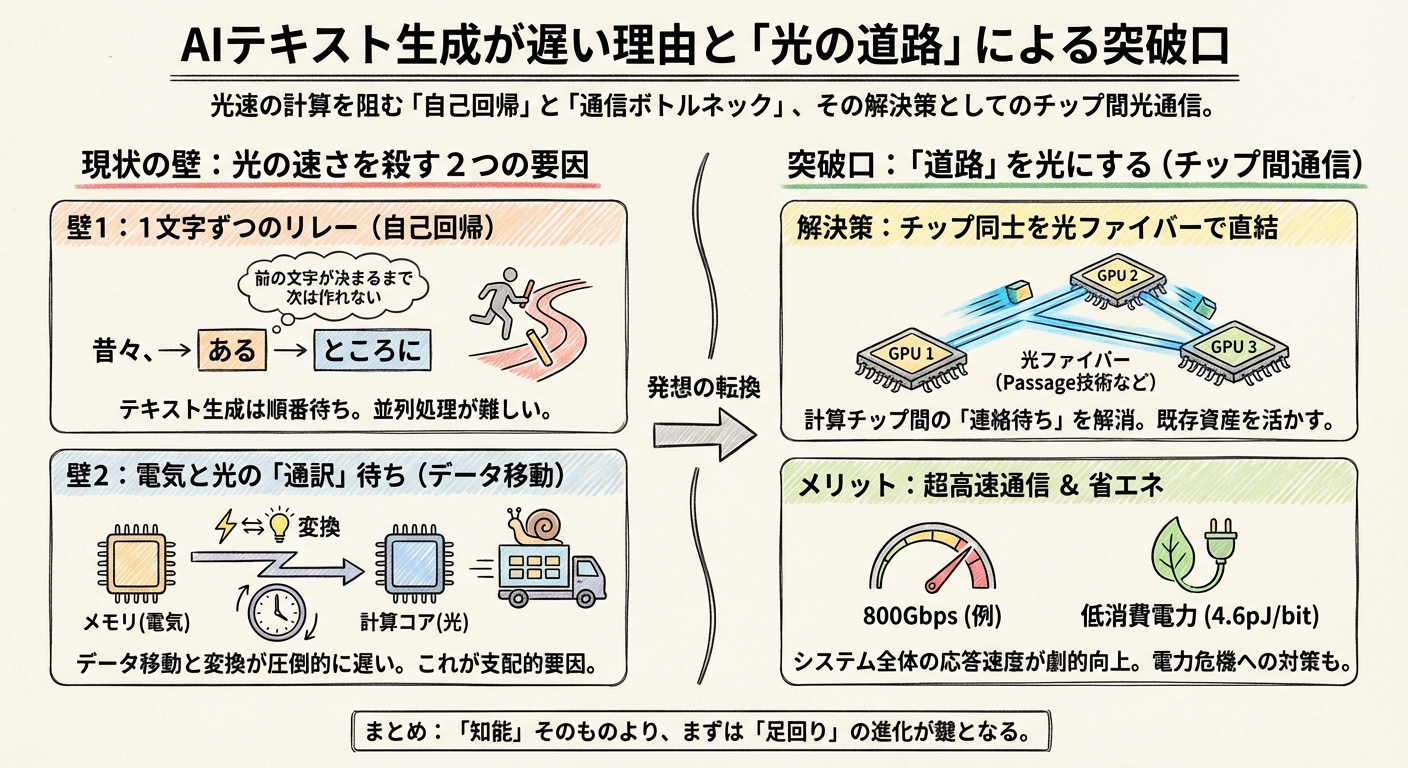
「一瞬」を阻む壁と突破口:なぜテキスト生成はまだ待たされるのか
前の章で、光が素子を通り抜ける時間はほんの1ナノ秒未満だとお話ししました。1ナノ秒といえば、10億分の1秒です。もしAIが本当にこの速度で動いているなら、私たちが「質問を入力してエンターキーを押した瞬間」には、すでに画面いっぱいに答えが表示されていてもおかしくないはずです。
でも、現実はそうではありません。カーソルは点滅し、文字はポツポツと順番に表示されます。私たちは依然として待たされています。
物理現象としては一瞬なのに、体験としては一瞬にならない。どうやら、このギャップにこそ、これからのAI開発における最大の課題と、それを突破するためのヒントが隠されているような気がしてきました。ここでは、光の速さを殺してしまう2つの「壁」と、意外な「突破口」について見ていきましょう。
壁1:テキスト生成の宿命「1文字ずつのリレー」
まず根本的な原因は、私たちが求めているものが「テキスト」だという点にあります。
UCLAの研究チームが開発した光学的生成モデルが素晴らしいのは、画像を「スナップショット」として一発で出力できる点でした。画像は、画面上のすべてのピクセルを同時に決めてしまっても成立します。だから、光の「並列処理(同時に全部照らす能力)」と相性が抜群なのです。
しかし、テキストはそうはいきません。「昔々、あるところに」という文章を作る時、AIは「昔々、」という言葉が決まって初めて、次に「ある」が来る確率を計算できます。これを専門用語で自己回帰(Autoregression)と呼びます。
つまり、どんなに計算速度が速くなっても、「前の文字が決まるまで、次の文字は作れない」というルールがある限り、一瞬で全文を出すことは原理的に難しいのです。これは、時速1000キロで走れるスーパーカー(光)を持っているのに、1メートル進むたびに必ず一時停止しなければならない状況に似ています。これでは、光の速さを活かしきれません。
壁2:光とデジタルの「通訳」待ち
もう一つの、そしてより深刻な壁は、計算そのものではなく「データの移動」にあります。
私たちが使っているデータ(文章や知識)は、今のところすべて「電気信号(デジタル)」としてメモリに保存されています。光で計算するためには、この電気信号を一度「光」に変換し、計算が終わったらまた「電気」に戻してメモリに書き込む必要があります。
実は、この電気と光の変換(I/O)や、メモリからデータを運んでくる時間が、光が計算する時間よりも圧倒的に長いのです。ある研究レビューでは、光コンピューティングにおいても、このメモリデータ移動こそが消費電力と速度の支配的な要因になっていると指摘されています。
料理に例えるなら、シェフ(光演算回路)は0.1秒で野菜を切れる神業を持っているのに、冷蔵庫(メモリ)から野菜を取ってくるのに10秒かかっているような状態です。これでは、いくらシェフの腕を磨いても、料理は早く出てきません。
突破口:計算ではなく「道路」を光にする
では、私たちはまだしばらく待たされ続けるのでしょうか? 正直なところ、AIの脳みそ(計算コア)をすべて光にして超高速化するのは、もう少し先の未来になりそうです。
しかし、ここに来て非常に面白い、現実的な「近道」が見つかりました。それは、計算チップそのものではなく、チップ同士をつなぐ「道路」を光にするというアプローチです。
現在のAI、特に巨大なLLM(大規模言語モデル)は、たった一つのチップで動いているわけではありません。何千、何万というGPU(計算装置)が連携して動いています。ここで起きているのが、GPU同士の猛烈な「連絡待ち」です。あるGPUが計算を終えても、隣のGPUからのデータが届くまで待機する時間が大量に発生しているのです。
この問題を解決しようとしているのが、Lightmatter社の「Passage」という技術です。彼らは、チップ間の通信を電気配線ではなく、光ファイバーで直結させる技術を開発しました。
その性能は驚異的です。彼らの技術解説によると、たった1本のファイバーで800Gbps(ギガビット毎秒)という速度でデータを送受信できます。しかも、消費エネルギーは1ビットあたりわずか4.6ピコジュール。これは従来の電気通信に比べて劇的な効率化です。
つまり、「計算(シェフ)」を速くするのは難しいから、先に「食材の運搬(道路)」を光速にしてしまおうというわけです。これなら、既存のGPUを使いながら、システム全体としての応答速度を劇的に上げることができます。どうやら、私たちが体験する「瞬時」への第一歩は、AIの知能そのものではなく、その足回りの進化から始まりそうです。
背景にあるのは「電力」の危機
なぜ今、ここまでして「効率」や「通信」にこだわるのでしょうか。それは単に私たちを待たせないためだけではありません。もっと切実な、エネルギーの壁があるからです。
AIモデルが賢くなればなるほど、データセンターの電力消費は爆発的に増えています。ある予測では、世界のデータセンターの電力消費量は2030年までに倍増する可能性が高いとされています。もし今の非効率な電気通信のままでAIを拡大し続ければ、地球の電力が足りなくなってしまうかもしれません。
光を使う最大のメリットは、実は「速さ」以上に、この「省エネ」にあるのかもしれません。熱を出さずに情報を運べる光の特性は、持続可能なAI社会を実現するための必須条件と言えるでしょう。
さて、技術的な壁と、それを迂回する賢い突破口が見えてきました。では、こうした技術はいつ頃、どのような形で私たちの手元に届くのでしょうか? 次の章では、データセンターの裏側から、私たちが身につけるメガネまで、光学的生成モデルが実装されていく未来のロードマップを描いてみたいと思います。
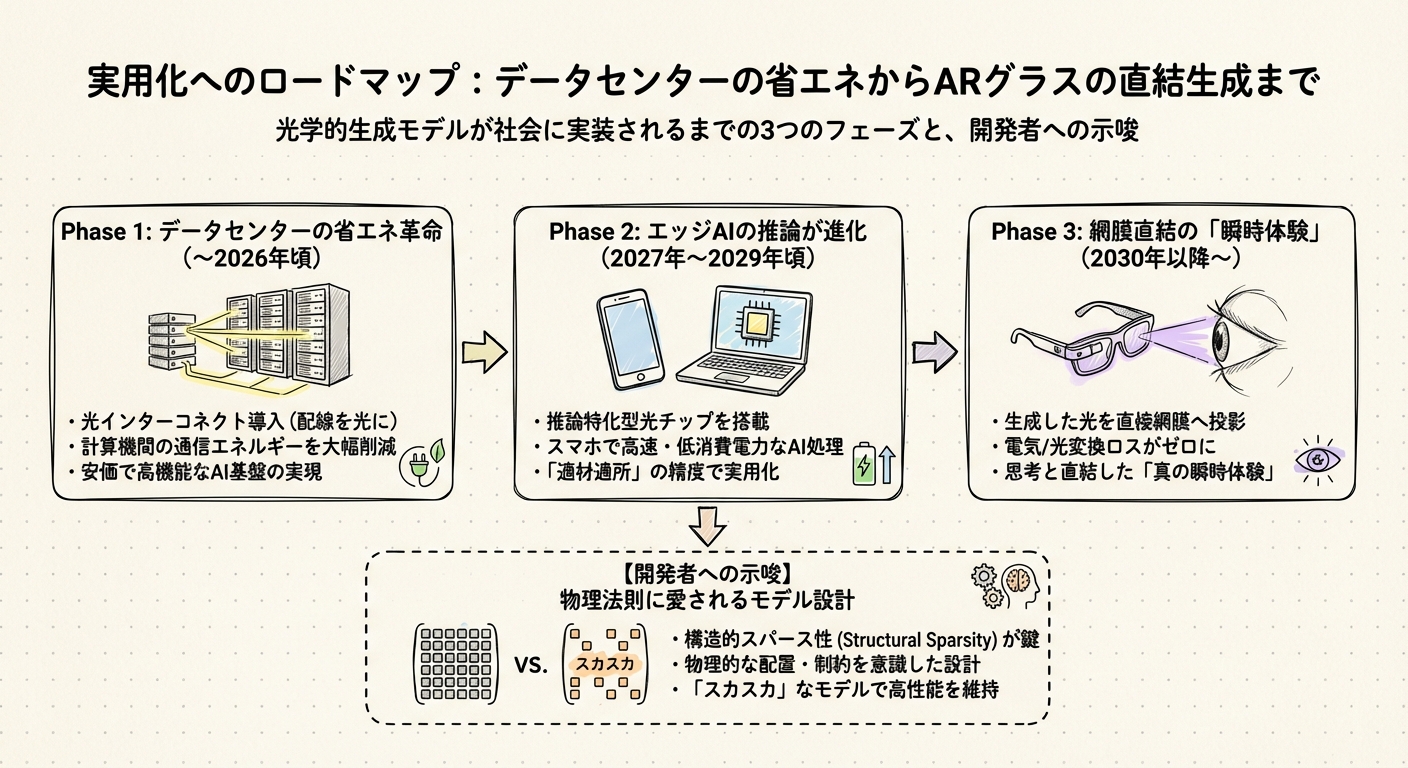
実用化へのロードマップ:データセンターの省エネからARグラスの直結生成まで
ここまで、光学的生成モデルの可能性と、それを阻む壁について考えてきました。どうやら、「明日からすべてのAIが光になって、何もかもが一瞬になる」という魔法のような未来は、すぐには訪れないようです。
しかし、がっかりする必要はありません。技術の進歩は、私たちが気づかない「裏側」から静かに、でも確実に始まっています。このセクションでは、光学的生成モデルが今後どのように社会に実装されていくのか、具体的なロードマップを私なりに描いてみたいと思います。
フェーズ1:見えない場所での「省エネ革命」(〜2026年頃)
まず最初に変化が起きるのは、私たちの手元ではなく、遠く離れたデータセンターの中でしょう。前の章でも触れた「通信の壁」を壊す動きです。
皆さんがChatGPTやGeminiを使っているとき、その裏側では膨大な電力が消費されています。国際エネルギー機関(IEA)の推計によると、2024年の世界のデータセンター電力消費は約415TWhでしたが、2030年にはこれが倍増する可能性があると予測されています。AIが賢くなればなるほど、地球への負荷は重くなる一方なのです。
ここで、光技術が「救世主」として登場します。計算そのものではなく、計算機同士をつなぐ「配線」を光に置き換える光インターコネクトです。Lightmatter社の技術などは、まさにここをターゲットにしています。彼らのシステムは、従来の電気配線に比べて圧倒的に少ないエネルギーでデータを運ぶことができます。
私たちユーザーにとって、これはどういう意味を持つのでしょうか? おそらく、AIの回答速度が少し速くなる(待ち時間が減る)だけでなく、「より安く、より高機能なAI」が使い続けられるという形で恩恵を受けるはずです。電力コストが下がれば、AIサービスの利用料も抑えられるからです。この段階では、私たちは「光を使っている」と意識することすらないでしょうが、社会インフラとしてのAIを支える最も重要な基盤になるはずです。
フェーズ2:スマホやPCでの「推論」が変わる(2027年〜2029年頃)
データセンターの足回りが固まった後、次は私たちの身近なデバイスに光技術が降りてきます。
現在、多くのAI処理はクラウド(データセンター)で行われていますが、プライバシーや速度の観点から、スマホやPCの中で処理する「エッジAI」への需要が高まっています。しかし、電池持ちが課題です。
ここで期待されるのが、推論(AIが答えを出す作業)に特化した光チップの導入です。光学的生成モデルの研究レビューでも指摘されているように、光チップ市場は2034年に30億ドル規模に達すると予測されており、その多くは特定の計算を効率よく処理するアクセラレータとして普及するでしょう。
例えば、翻訳や要約といったタスクなら、必ずしも最高の計算精度(64bitなど)は必要ありません。光演算が得意とする少し粗い精度(4〜8bit程度)でも十分実用になることが分かっています。この「適材適所」が進めば、スマホのバッテリーを気にせず、常にAIアシスタントと会話できる日が来るかもしれません。
フェーズ3:光をそのまま網膜へ「直結体験」(2030年以降〜)
そして、私が最もワクワクしているのがこの未来です。UCLAの研究チームが描いているシナリオは、単なる計算の高速化を超えた、新しい体験の提案です。
今のコンピュータは、せっかく光で計算しても、それをわざわざ「電気信号」に戻してディスプレイに表示しています。しかし、もし私たちがAR(拡張現実)グラスをかけているとしたらどうでしょう?
UCLAの論文では、生成された光をデジタルに戻さず、そのままアナログの光としてユーザーの目に届ける可能性について触れられています1。例えば、ARグラスの中で「森の風景」を生成するとき、AIが作った光の波をそのまま網膜に投影するのです。
こうなれば、情報の変換ロスはゼロ。「変換待ち」の時間もゼロ。私たちが何かを思い浮かべた瞬間、目の前にその景色が広がっている――そんな「真の瞬時体験」が実現するかもしれません。これこそが、光学的生成モデルが目指す究極のゴールではないでしょうか。
開発者への示唆:AIモデルを「スカスカ」にする勇気
最後に、これからAI開発に関わる方へ、少し技術的な視点からの示唆を共有したいと思います。
これまでのAI開発は、「とにかくモデルを大きく、密に(ぎっしり詰まった行列で)作る」ことが正義でした。しかし、光チップという物理的な制約のあるハードウェアを使う場合、この常識は通用しません。光の回路をチップ上に配置するには場所をとるため、無駄な計算回路を置くスペースがないのです。
そこで重要になるのが、構造的スパース性(Structural Sparsity)という考え方です。ある研究では、モデルの中身をあえて「スカスカ(局所疎やブロック対角)」に設計することで、光回路の部品数(MZI数)を約98.7%削減しつつ、性能を維持できることが示されています。
つまり、これからのAIエンジニアには、単にソフトウェアのロジックを組むだけでなく、「このモデルは物理的にどう配置されるのか?」というハードウェアの視点を持って設計する力が求められるようになる気がします。「物理法則に愛されるモデル」を作れる人が、次の時代のイノベーターになるのかもしれません。
光学的生成モデルは、まだよちよち歩きの技術です。しかし、そのポテンシャルは計り知れません。それは単に計算が速くなるという話ではなく、エネルギー問題という地球規模の課題を解決し、私たちとコンピュータの関わり方を「デジタル」から「物理現象そのもの」へと進化させる可能性を秘めています。
私たちが生きている間に、思考と直結したようなAI体験ができる日はきっと来るでしょう。その時、光は単なる照明ではなく、知性そのものを運ぶ媒体になっているはずです。
調査手法について
こちらの記事はデスクリサーチAIツール/エージェントのDeskrex.AIを使って作られています。DeskRexは市場調査のテーマに応じた幅広い項目のオートリサーチや、レポート生成ができるAIデスクリサーチツールです。
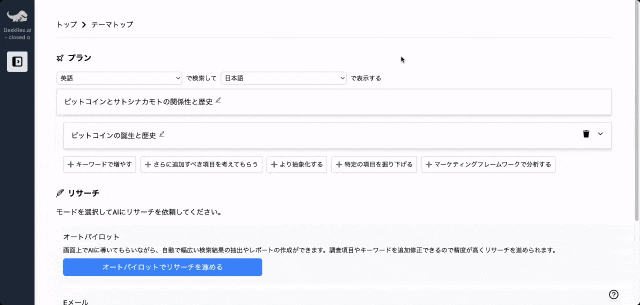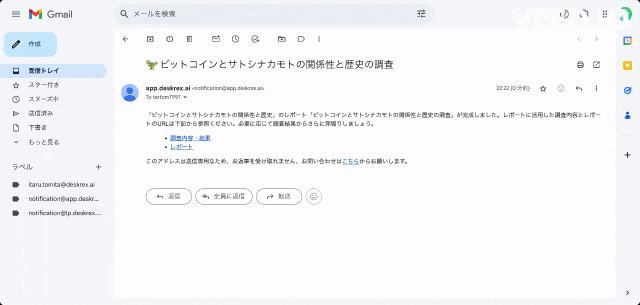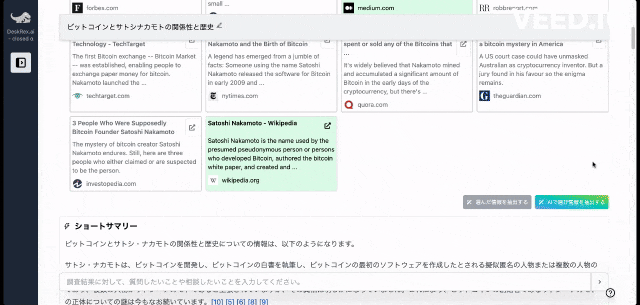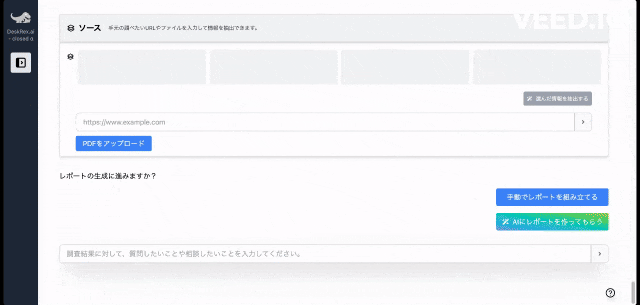
調査したいテーマの入力に応じて、AIが深堀りすべきキーワードや、広げるべき調査項目をレコメンドしながら、自動でリサーチを進めることができます。

また、ワンボタンで最新の100個以上のソースと20個以上の詳細な情報を調べもらい、レポートを生成してEmailに通知してくれる機能もあります。
ご利用をされたい方はこちらからお問い合わせください。
また、生成AI活用におけるLLMアプリ開発や新規事業のリサーチとコンサルティングも受け付けていますので、お困りの方はぜひお気軽にご相談ください。
市場調査やデスクリサーチの生成AIエージェントを作っています 仲間探し中 / Founder of AI Desk Research Agent @deskrex , https://deskrex.ai


コメント