
「ワールドモデル」って、何を指す言葉でしたっけ?
「ワールドモデル」はAIで最近よく聞くキーワードだけど、研究者間でも「何がワールドモデルか」の定義がバラバラだった。
北京大学・清華大学など8機関が共同で、ワールドモデルの統一定義と推論フレームワーク「OpenWorldLib」を発表した(GitHubで公開済み)。
論文の定義はシンプルで明快。…
— いたる (@itarutomy) April 17, 2026
2026年4月、北京大学・清華大学など中国の8研究機関が「OpenWorldLib」という論文を発表し、ワールドモデルの整理された定義を提案しました。これまで研究者ごとにバラバラだった「ワールドモデル」の意味を、一つの枠組みにまとめ上げた試みです。
2025年を振り返ると、「ワールドモデル」という言葉がAI業界で飛び交っていました。OpenAIの動画生成AI「Sora」が「世界シミュレーター」と宣伝され、MetaのチーフサイエンティストであるYann LeCun氏が「Soraはワールドモデルではない」と反論しました。NVIDIAや騰訊(Tencent)なども次々と「ワールドモデル」を冠する製品や研究を発表していきました。ただ、ずっと気になっていたことがあります。「ワールドモデル」という言葉を使う人はたくさんいたのに、何を指しているのかが人によってまったく違っていたのです。
ある人は「物理法則を理解して動画を生成するAI」と言い、別の人は「ロボットが現実世界とやり取りする仕組み」と言い、さらに別の人は「LLM(大規模言語モデル、ChatGPTのようなテキストベースのAI)の次に来る新しいAIの設計思想」と言いました。どれもそれっぽく聞こえるけれど、同じ言葉で違うものを語っていたわけです。例えるなら、「カレー」と注文したら、お店の人によってインドカレー、スープカレー、レトルトカレーと全然違うものが出てくるようなものです。
私たちのメディアでも前回の記事で、ワールドモデルの3つの主要アプローチを紹介しました。Fei-Fei Li氏が提唱する「空間知能」(3D空間を認識・理解するAIの能力)、LeCun氏の「JEPA」(Joint Embedding Predictive Architecture、動画や画像から物理世界の法則を予測する仕組み)、そしてDeepMindの「シミュレーション生成」(ゲームのような仮想環境を自動で作り出す技術)です。ただ正直なところ、「そもそも何がワールドモデルで、何がワールドモデルじゃないのか」という境界線については、私自身、はっきりと答えられないままでした。
2026年4月に発表されたOpenWorldLibの論文OpenWorldLibは、まさにこの「境界線が引けない」という問題に一つの回答を提示したものです。北京大学、清華大学、香港科技大学など中国の8つの研究機関が共同で、ワールドモデルの「整理された定義」を提案しました。
OpenWorldLibの論文が面白いのは、単に「ワールドモデルとは〜である」と定義しただけではない点です。「何がワールドモデルではないか」も明確に線を引いています。例えばOpenAIのSora。この論文ではワールドモデルではないと判断されています。理由は、視覚だけでなく触覚や聴覚など複数の感覚を統合しておらず、物理世界とのやり取りがないからです。コード生成やWeb検索も除外されています。物理世界の理解を伴わないからです。アバター動画生成も同様で、物理世界を探索・理解することが目的ではないため対象外です。言い換えると「これらはワールドモデルを名乗ってはいけない」という除外リストがあるのです。「何ではないか」まで指定したアプローチが、これまでの論文にはなかった新しい視点だと思います。
ここからは、OpenWorldLibが引いた境界線に沿って話を進めていきます。まずは「なぜ同じ言葉なのに、人によって意味が違っていたのか」という背景から見ていきましょう。
定義がバラバラだった時代 — Soraはワールドモデルか?
Soraはワールドモデルなのか? 2024年時点では、誰もこの問いに明確に答えられませんでした。理由は単純で、OpenAIとYann LeCunが「ワールドモデル」という同じ言葉を使いながら、それぞれ別の定義で議論していたからです。この定義のズレは強化学習、ロボット工学、動画生成など複数の分野にまたがり、2026年4月のOpenWorldLib論文発表まで続きました。
2024年2月、OpenAIが動画生成AI「Sora」を発表したときのことを思い出してみましょう。Soraはテキストから高品質な動画を生成できるモデルで、OpenAIはSoraを「世界シミュレーター」と呼びました。雪の中を走る犬、空中に浮かぶコーヒーカップ、まるで実写のような映像を次々と作り出す様子を見て、私も「これは何かが変わった」と感じた一人です。詳しい経緯はThe Decoderの報道をご覧ください。
ところが、MetaのYann LeCun氏がすぐに異を唱えました。「ピクセルを生成して世界をシミュレートしようとするのは、無駄であり失敗する運命にある」と。LeCun氏はSoraのアプローチを真っ向から否定したのです。チューリング賞(コンピュータ科学分野のノーベル賞のようなもの)の受賞者で、AI研究でも最も影響力のある人物の一人が、OpenAIの看板モデルを一刀両断したわけです。
この対立、いったい何が起きていたのでしょうか。
私はこの議論を追いかけていて、あることに気づきました。OpenAIとLeCun氏は「ワールドモデル」という同じ言葉を使いながら、どうやら全く違うものを指していたようなのです。
OpenAI側の「ワールドモデル」は、次フレーム予測(次の映像のコマをAIが推測する技術)を通じて物理世界の見た目を再現する、という考え方でした。テキストから映像を作る、次のコマを予測する、その繰り返しで動画ができあがる。これで言えば、Soraは確かに「世界をシミュレートしている」と言えなくもありません。映像がリアルなのだから、世界を理解しているじゃないか、と。
一方、LeCun氏側の「ワールドモデル」は、物理法則そのものを内部表現(AIが独自に構築する概念のまとまり)として学習し、行動の結果を予測する能力を指していました。ピクセルの表面的な再現ではなく、「重いものが落ちたら速く加速する」「柔らかいものは凹む」といった因果関係をAIが理解しているかどうか。LeCun氏から見れば、Soraは映像の表面的なパターンを学習しているだけで、背後にある物理法則は理解していないのです。
例えるなら「美しい風景画を描ける画家」と「地形や地質を理解した土木技師」くらい違うものを、同じ言葉で語っていたようなものです。画家は山の形や色を正確に再現できても、なぜその山がそこにあるのかは説明できない。土木技師は地盤の強度や水の流れを計算できても、絵心はない。どちらも「山を知っている」けれど、その「知り方」が根本的に違う。
この「物差しの違い」は、Soraに限った話ではありませんでした。強化学習(試行錯誤で最適な行動を学ぶAIの手法)の世界では、David HaとJürgen Schmidhuberが2018年に発表した論文で、ゲーム画面を圧縮して「脳内世界」だけで学習するエージェントを「ワールドモデル」と呼びました。ロボット工学では、Physical Intelligenceの「pi-0」のようなロボットアーム制御モデルがワールドモデルと呼ばれました。動画生成の世界では、次フレーム予測がワールドモデルと呼ばれました。
全部違うものを、同じ「ワールドモデル」という言葉で語っていたのです。ある研究者は「同じ地図を見ながら、別の場所について話しているようなもの」と表現していました。言葉は通じているように見えて、実は会話が成立していなかった。2026年4月まで、この状態がずっと続いていました。
この平行線の論争に終止符を打ったのが、OpenWorldLibの論文だったというわけです。
OpenWorldLibが引いた境界線 — 4つの能力と「除外リスト」

OpenWorldLibはワールドモデルの3つの必須要素、4つの能力分類、そして「ワールドモデルではない」と除外された技術の基準を明確に定義しています。順番に見ていきましょう。
では、OpenWorldLibは具体的にどんな定義を示したのでしょうか。
ワールドモデルとは「知覚(視覚、音声、触覚などの感覚入力)を中心に、行動に基づくシミュレーションと長期記憶を備え、複雑な世界を理解・予測するモデルやフレームワーク(枠組み)」であると、OpenWorldLibの論文で定義しています。少し長いので、3つの必須要素に整理してみましょう。
まず「複合的な知覚入力」。視覚だけじゃなくて、聴覚、触覚、さらにはロボットの関節角度みたいな身体感覚も含めて世界を捉えます。私たちが目で見て耳で聞いて肌で触れるのと同じように、AIも複数の感覚から情報を受け取る必要があるわけです。
次に「行動に基づくシミュレーション」。自分が何か行動をしたら、その結果として世界がどう変わるかを予測できること。たとえばロボットが「カップを押したら倒れるだろう」と事前に予測して動けるかどうか、という能力です。
最後に「長期記憶」。一度経験したことを覚えておいて、次の行動に活かせること。昨日覚えた道を今日も迷わず歩ける、という人間の記憶と同じ仕組みをAIに求めています。
どうやら、論文では、この3つの要素(知覚・シミュレーション・記憶)をすべて満たすものを「ワールドモデル」と呼んでいます。あくまでこの論文の基準ですが、一つの目安としては分かりやすい枠組みだと思います。特定のタスクや内部構造に縛られない、「知能のレベル」を表す概念だと位置づけています。
ワールドモデルの4つの能力
ここからが面白いんです。OpenWorldLibの定義に基づいて、ワールドモデルが持つべき4つの能力が整理されています。
まず「インタラクティブ動画生成(ユーザーの操作に応じてリアルタイムに次の映像を予測・生成する能力)」。ゲームのプレイ映像をAIがリアルタイムで生成したり、カメラの向きを変えるとそれに合わせて見え方が変わったりする技術がこれに当たります。評価では、騰訊(中国の大手テクノロジー企業)の「Hunyuan-WorldPlay」が視覚品質で高く評価され、NVIDIAの「Cosmos」は物理的リアリズム(物理法則に沿った自然な動きの再現度)で優れているという結果がOpenWorldLibの評価で出ています。
そして「マルチモーダル推論(映像・音声・テキストなど複数の形式の情報を組み合わせて考える能力)」。空間、時間、因果関係を複合的に理解する能力です。これまでのAIはテキストだけで考えるのが主流でしたが、ワールドモデルは映像や音声といった豊かな情報も同時に処理できることがポイントです。言ってみれば「目と耳と頭を同時に使って考える」ようなものです。
3D生成・再構成も重要な能力です。現実の空間を3Dモデルとして構築・復元する技術で、部屋の中を撮影した映像から部屋の3D形状を正確に復元するようなものが当てはまります。OpenWorldLibの論文では「VGGT」や「InfiniteVGGT」などのモデルがこの分野に含まれます。
最後に「VLA(Vision-Language-Action:視覚と言語を行動に変換する技術)」。カメラで見た映像と言語の指示を組み合わせて、ロボットの具体的な動作を生成する能力です。ロボットアーム操作や自動運転システムが対象で、Physical Intelligence(ロボット向けAIを開発するスタートアップ企業)の「pi-0」や「pi-0.5」がOpenWorldLibの具体例として挙げられています。
ワールドモデルから除外された技術
ここまで読むと「いろんな技術がワールドモデルに入っているんだな」と思うかもしれません。ですが、私がOpenWorldLibの定義で本質だと思うのは「何を除外したか」の方なんです。
Sora(OpenAIの映像生成AI)はワールドモデルではありません。なぜかというと、Soraはテキストから映像を作るだけで、複数の感覚を統合したり物理世界とやり取りしたりする仕組みがないからです。いくら映像がリアルでも、映像を「生成」することと世界を「理解」することは別の問題なんです。
コード生成やWeb検索もワールドモデルではありません。これらの技術はワールドモデルの「長期的な相互作用」の仕組みを部分的に借りているものの、物理世界の理解を伴わないからです。プログラムのコードを書いたりWeb上の情報を検索したりする行為は、デジタルなテキストの世界の中で完結しています。
アバター動画生成も除外されています。複数の感覚を使った長期的なやり取りがあっても、OpenWorldLibの定義では物理世界の探索や理解が目的ではないため、除外されています。アバターが会話する映像は見た目が高度でも、その背後で物理法則をシミュレーションしているわけではありません。
この線引きを見ていて、一つの問いが浮かんできました。テキストの世界で優秀なだけでは不十分で、物理的な世界を知覚し、相互作用し、記憶する能力こそが「真の知能」に必要なのではないか、と。私たちが普段「このAI賢いな」と感じるとき、その裏で何が起きているのか、少し考えてみたくありませんか?
LeCunの2026年 — Meta退社とJEPAの最新動向
OpenWorldLibの定義提案を語る上で、どうしても外せない人物がいます。Yann LeCun氏です。
2026年1月にMetaを退社し、AMI Labsという新しい研究所を設立したLeCun氏は、LLMに代わるアーキテクチャとして「JEPA」を提唱し続けてきました。2026年4月にはV-JEPA 2.1も発表され、ワールドモデルの研究が大きく動いています。
そもそもLeCun氏は、なぜLLMに批判的なのでしょうか。長年、LLM(大規模言語モデル)の限界を指摘し続けてきました。「LLMは次の単語を予測するだけの仕組みであり、物理世界を理解する能力はない」というのが彼の一貫した主張です。The Decoderの報道によれば、その代わりとしてLeCun氏が提唱してきたのが「JEPA(Joint Embedding Predictive Architecture)」というアーキテクチャでした。
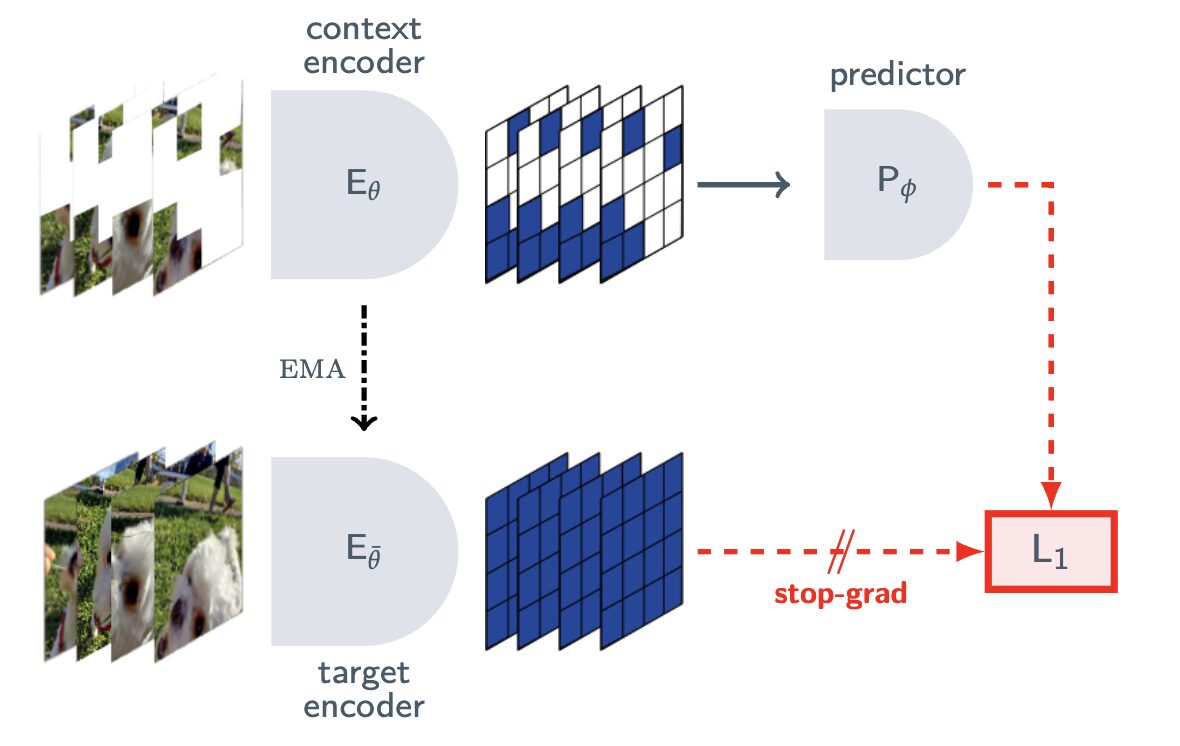
JEPAの考え方はシンプルです。ピクセルをそのまま生成して世界を理解しようとするのは無駄だ、という出発点に立ちます。たとえば、草が風に揺れる様子や、水滴が跳ねる様子は映像としては重要でも、物理法則を理解するうえではノイズ(邪魔な情報)にすぎません。AIがこのノイズまで再現しようとすると、計算リソースを細部に浪費してしまい、「物が落ちるのは重力があるから」といった本質的なルールの学習がおぼつかなくなります。
そこでJEPAは、ピクセルそのものではなく「何が起きているか」という抽象的な特徴空間で予測を行います。映像をそのまま処理するのではなく、映像から「物体の位置」「動きの方向」「物体間の関係」のような抽象的な特徴を抽出し、その特徴が次にどう変化するかを予測する仕組みです。これは人間の認知に近いアプローチだと思います。私たちは目の前の光景をピクセル単位で記憶しているわけではなく、「犬が走っている」「車が止まった」のような抽象的な概念として捉えていますよね。JEPAはこれと似たやり方で世界を理解しようとするわけです。
このJEPAの考え方は、OpenWorldLibの定義の中でどう位置づくのでしょうか。
OpenWorldLibが定義する4つの能力のうち、JEPAは主に「マルチモーダル推論」に貢献するアーキテクチャとして位置づけられます。抽象的な特徴空間で世界を予測することで、物理世界の因果関係や法則を理解する能力を高める、という方向性です。
2026年に入ってからLeCun氏の周りで起きた出来事を整理すると、大きく2つあります。
1つ目は、2026年1月にLeCun氏がMetaを退社し、新しい研究機関「AMI Labs」を設立しました。AMI Labsは「Advanced Machine Intelligence(高度な機械知能)」の実現を目指す研究所で、LeCun氏が長年構想してきたワールドモデルの研究を本格的に推進する場です。
LeCun氏がMetaを退社した理由について、本人は詳しく語っていません。しかし、LLM中心の開発方針を持つ巨大企業の中で、ワールドモデルという別の方向性を追求するには、独立した環境が必要だったのではないかと私は推測しています。巨大な組織の中で「主流とは違う道」を歩くのは、案外難しいものです。
2つ目は、V-JEPA 2.1がLeCun氏のLinkedInで発表されたのが2026年4月のことです。V-JEPA 2.1は階層的な特徴学習を導入し、セマンティックセグメンテーション(画像中の各ピクセルが「車」「道路」「空」のどれに属するかを判定する技術)などの密な視覚タスクで、従来のV-JEPA 2より高い性能を示しました。着実にJEPAの線が伸びている印象です。
LeCun氏はかねてより「10年以内にLLMは置き換わる」と発言しています。AMI Labsの設立とV-JEPA 2.1の発表は、この発言に向けた具体的な一歩なのだと思います。そしてOpenWorldLibが提示した定義は、LeCun氏が目指す「LLMの先」の方向性とぴったり重なっています。
LeCun氏が「LLMは終わる」と断言する一方で、実際の産業界ではLLMが猛スピードで進化し続けています。この対立構造の先には何が待っているのでしょうか。
この定義は、何の目安になるのか
OpenWorldLibは一つの論文に過ぎません。公式な規格ではなく、業界全体が合意したものでもない。ですが、ワールドモデルが何を指すのかを整理した最初の真面目な試みとして、多くの研究者の目に留まったのだと思います。
この定義が目安として使えるのは、次の3つのポイントです。企業が「ワールドモデルです」と言うときの判定基準が明確になったこと。技術を評価するテストが共通化されたこと。そして研究者同士が話を合わせやすくなったこと。何より、読者である私たちがAIニュースを深く読めるようになるのではないかと私は思っています。
企業にとって何が変わるのか
これまで、どんな技術でも「ワールドモデル」と名乗れば、なんとなく説得力がありました。動画生成AIを作っている企業も、ロボット制御のシステムを作っている企業も、同じ「ワールドモデル」という言葉を使っていた。いわば、商品のパッケージに「オーガニック」と書くようなもので、中身が何であれそれっぽく響いてしまう状況でした。
OpenWorldLibの定義が示された今、「これはワールドモデルです」と主張するには、3つの要素を満たしているかどうかが判断基準になります。視覚や言語などの複合的な知覚入力を処理できるか。物理世界に対してアクションを起こして結果を受け取れるか。過去の経験を蓄積して将来の予測に活かせる長期記憶を持っているか。この3つの条件をクリアしているかどうかで、自称ワールドモデルが本当にその名に値するのかが判断できるようになりました。「オーガニック」に代わる厳格な認証ラベルができた、とでも言えばいいでしょうか。
評価ベンチマークの共通化
OpenWorldLibは単なる論文ではなく、統合推論フレームワーク(複数の推論タスクを統一的に評価できるソフトウェア基盤)としてのコードベースをOpenWorldLibのGitHubリポジトリで公開しています。4つの能力を同じ基準で評価できる仕組みが用意されたわけです。
ひとつめはインタラクティブ動画生成、ユーザーの入力に応じて動画を生成し変更できる能力です。ふたつめはマルチモーダル推論、画像・テキスト・音声など複数の形式のデータを組み合わせて推論する能力。みっつめは3D生成、3次元の空間や物体を生成する能力。そしてよっつめはVLA(Vision-Language-Action)、視覚と言語の理解を行動に変換する能力です。これら4つを共通の基準で測れるようになりました。
これまでは各企業や研究グループが「うちの基準では一番です」と主張するような状態でした。それが共通の物差しで比較できるようになる。百メートル走で言えば、ようやくスタートラインとゴールラインが揃ったようなものかもしれません。
研究者間コミュニケーションの改善
これまでは「ワールドモデル」と言っただけで、相手が何を想像しているのか分からない。例えば、OpenAIが動画生成AIのSoraを発表したとき、「Soraはワールドモデルと言えるのか?」という議論が研究者の間で起きました。この「Sora論争」と呼ばれる議論は、結局のところ「言葉の不一致」が原因で平行線に終わりました。
一つの定義があれば、少なくとも「OpenWorldLibの定義におけるワールドモデル」という共通の土台で議論できる。スポーツのルールブックが初めて策定されたときと似ている気がします。ルールがなければ試合にならないけれど、ルールができた途端に本格的な対戦が始まる。
読者のAIニュースの読み方
読者にとっても「AIニュースの読み方」が変わるのではないかと思います。
今後、AI企業が「ワールドモデル」を冠する新製品を発表したとき、「この製品は4つの能力のうちどれを満たしているのか」「除外リストに該当しないか」という視点で読み解けるようになります。除外リストとは、OpenWorldLibが「ワールドモデルではない」と明示的に除外したもののことです。ChatGPTのような単なる言語モデルや、従来の動画生成モデルなどが該当します。この視点を持つだけで、プレスリリースの表面的な文句の背後にあるものが見えてきます。
例えば、ある企業が「ワールドモデルでゲームを自動生成する」と発表したとします。OpenWorldLibの枠組みで見れば、これは「インタラクティブ動画生成」の能力に当たります。ユーザーの操作に反応するだけでなく、物理法則を理解し、長期記憶も備えているかどうか。その基準で評価することで、「本物のワールドモデルなのか、それとも動画生成AIに毛が生えたものなのか」が見えてくるはずです。
定義の統一は、地味な作業に見えるかもしれません。でも「共通の言葉」がなければ、どんなに技術が進歩しても、研究者も企業も読者も、互いに違う方向を見つめながら同じ言葉を口にし続けることになります。OpenWorldLibが引いた境界線は、その状況を変える最初の一歩なのだと思います。さて、この定義を踏まえて、私たちはAIニュースをどう読み解いていけばいいのでしょうか。
まとめ
ワールドモデルという言葉がAI業界で使われ始めてから、ずっと気になっていたことがありました。「結局、何をワールドモデルと呼べばいいのか」という問いです。議論が盛り上がるたびに、なんだか人によって言っていることが違う気がして、モヤモヤしていたんですよね。
2026年4月のOpenWorldLib論文は、私のこの問いに、一つの明確な答えを出してくれました。ワールドモデルとは、特定の技術や製品の名前ではなく、「見聞きした情報をもとに、行動をシミュレーションし、長期的に記憶しながら、複雑な世界を理解・予測する」能力のことです。そしてこの能力は4つの具体的な能力で確かめられ、Soraやコード生成のような「ワールドモデルではないもの」にも明確に線が引かれました。
4つの能力とは何か。インタラクティブ動画生成は、ユーザーの指示に応じてリアルタイムに動画を生成・操作できる能力です。マルチモーダル推論は、画像・音声・テキストなど複数の種類の情報を組み合わせて考える能力です。3D生成・再構成は、2Dの画像や映像から立体的な3D空間を作り出す能力です。そしてVLA(Vision-Language-Action)は、目で見た情報と言葉の理解を、ロボットの実際の動きに変換できる能力です。
この定義が提示されたことで、現場の空気が変わりつつあります。企業は「ワールドモデル」を名乗るために、先ほどの4つの能力のうち少なくとも一部を満たす必要が出てきました。動画生成AIを作れば「ワールドモデルです」と言えた状況に、少しずつ歯止めがかかりそうです。研究者側も共通の定義に基づいて議論できるようになり、複数のモデルを同じテストで評価するベンチマークの標準化も進んでいます。
LeCun氏(Yann LeCun:ディープラーニングの先駆者の一人でチューリング賞受賞者)が設立したAMI Labsと、同氏が提唱するV-JEPA 2.1(動画を直接学習して、世界の物理法則を理解するモデル)の発表も、同じ文脈で読める出来事だと思います。LLM(ChatGPTやClaudeのようなテキスト中心のAI)がテキストの理解と生成に特化しているのに対し、ワールドモデルは物理的な世界そのものを理解することを目指しています。この方向性が、LeCun氏個人の主張から研究コミュニティ全体の取り組みへと広がってきているように見えます。
OpenWorldLibの評価用プログラムがGitHubで公開されているため、4つの能力を同じ基準で測る仕組みはすでに動き始めています。どのAIモデルが本当にワールドモデルの要件を満たしているのか、共通のテストで比較できる時代が近づいているかもしれません。
今後AIニュースで「ワールドモデル」という言葉を見かけたら、「このAIは4つの能力のどれを満たしているのだろう」「論文が『ワールドモデルではない』と明記した対象に該当していないか」と考えてみてください。この判定軸を持っているだけで、PR記事と実態の差が見えてくるはずです。
前回の記事で紹介した3つのアプローチと、今回のOpenWorldLibの定義。この2つを合わせて読むことで、ワールドモデルという分野の全体像がより鮮明に見えてくるのではないでしょうか。
ワールドモデルについてのよくある質問
Q: ワールドモデルとLLMの違いは何ですか?
A: LLM(大規模言語モデル)はテキストの理解と生成に特化したAIです。ChatGPTやClaudeがこれに該当します。ワールドモデルは画像・音声・テキストなど複数の種類の情報を組み合わせ、物理的な世界を理解・予測する能力を指します。テキストだけではなく、視覚や行動も含めて世界をモデル化する点が根本的に異なります。
Q: Soraはワールドモデルではありませんか?
A: OpenWorldLib論文の定義では、Soraは「ワールドモデルではない」と分類されています。Soraはテキストから高品質な動画を生成する能力に優れていますが、生成した映像の世界を理解・予測したり、ユーザーの指示に応じて動画をリアルタイムに操作したりする能力という観点では、要件を満たしていないと判断されました。
Q: ワールドモデルの4つの能力とは何ですか?
A: インタラクティブ動画生成(リアルタイムに動画を生成・操作できる)、マルチモーダル推論(画像・音声・テキストなどを組み合わせて推論できる)、3D生成・再構成(2D画像から3D空間を復元できる)、VLA(視覚と言語の理解を物理的な行動に変換できる)の4つです。これらを基準に、ワールドモデルと名乗ってよいかどうかを判断します。
Q: ワールドモデルの評価基準はどこで確認できますか?
A: OpenWorldLibの評価用プログラムがGitHubで公開されており、4つの能力を同じ基準で測るテストがすでに利用可能です。自分のAIモデルがワールドモデルと言えるかどうかを確認したい場合は、公開されているプログラムを使って判定できます。
調査手法について
こちらの記事はグラフAIリサーチプラットフォームのSnorbeを使って作られています。Snorbeは研究開発・新規事業向けの調査テーマに応じた幅広い項目のオートリサーチや、ナレッジグラフの構築、構造化レポートの生成ができるAIリサーチツールです。
Screenshot
調査したいテーマを入力するだけで、AIが深堀りすべき観点や広げるべき調査項目をレコメンドしながら、自動でリサーチを進めます。収集した情報はナレッジグラフとして蓄積され、未調査領域(ホワイトスペース)を可視化しながら調査の網羅性を高めていけます。
また、観点マトリクスを30秒・構造化レポートを10分で自動生成する機能があり、出典付きのレポートをMarkdown/PDF形式でエクスポートできます。調査の元データも保存されるため、ファクトチェックや社内共有も容易です。
ご利用をご希望の方は、こちらよりお申し込みください。
また、グラフAIを活用した社内ナレッジ管理や、研究開発・新規事業のリサーチ支援、セルフホスト導入のご相談も受け付けています。お困りの方はお気軽にご連絡ください。
市場調査やデスクリサーチの生成AIエージェントを作っています 仲間探し中 / Founder of AI Desk Research Agent @deskrex , https://deskrex.ai


コメント