
ワールドモデルは、AIの頭の中に「スノードーム」を作る試み
ここ数年、私たちは言葉を操るAI、つまり大規模言語モデル(LLM)の進化に驚かされ続けてきました。まるで魔法のように詩を書き、コードを生成し、複雑な質問に答える姿を見て、「AIはついに知能を持った」と感じた方も多いのではないでしょうか。
しかし、ふとした瞬間に奇妙な脆さを感じることはありませんか?
例えば、非常に流暢に話すAIが、単純な物理現象についてトンチンカンな答えを返したり、少し条件を変えただけの道案内に失敗したりする。どうやら、彼らは「言葉の並び順」は完璧に知っていても、その言葉が指し示す「現実の世界がどう動いているか」までは理解していないようなのです。
実は今、この限界を突破するための新しい概念が、AI研究の最前線で熱を帯びています。それが「ワールドモデル(World Model)」です。
「マンハッタンの地図」が描けないAIたち
LLMが抱える本質的な課題を浮き彫りにする、興味深い事例があります。ハーバード大学とMITの研究者たちが、LLMにニューヨークのマンハッタンでの道案内をさせる実験を行いました。通常の状態であれば、AIはほぼ完璧なルートを提示できます。なにしろ、インターネット上の膨大なテキストデータから、どの通りとどの通りが交差しているかという知識を学習しているからです。
ところが、研究者が「道路の1%をランダムに通行止めにする」というわずかな変更を加えた途端、AIのパフォーマンスは急激に低下してしまいました。
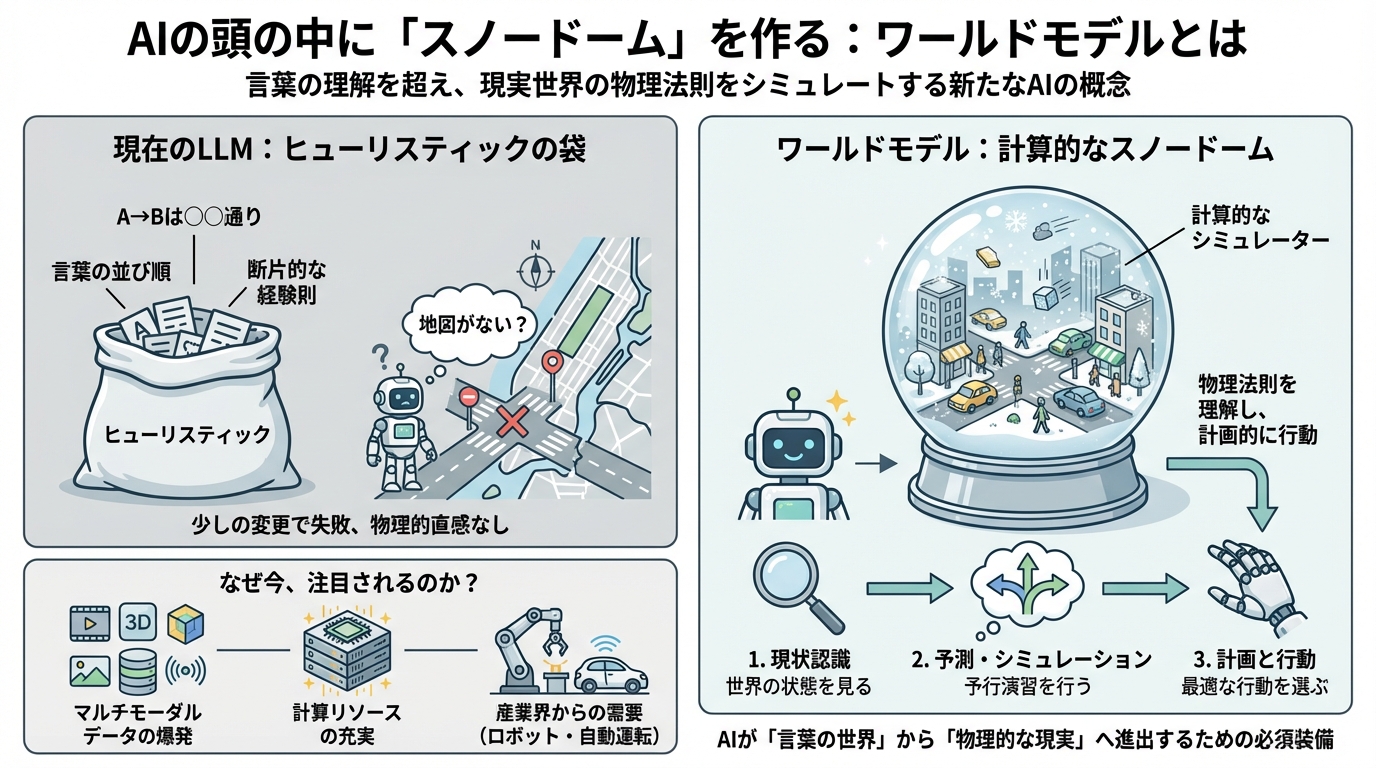
もし私たちが頭の中に「マンハッタンの地図(空間的なイメージ)」を持っていれば、ある道が塞がっていても、「じゃあ一つ隣の通りを北上しよう」と柔軟に迂回ルートを思い描けます。しかし、LLMはどうやら地図を持っているわけではないようです。彼らが持っているのは、膨大なテキストから得た「A地点からB地点へ行くなら、通常は○○通りを通る」という断片的な経験則(ヒューリスティック)の集まりに過ぎません。
Quanta Magazineの記事では、今の生成AIが学習しているのはワールドモデルではなく、いわば「ヒューリスティックの袋」のようなものだと表現されています。一貫した全体像がないため、状況が少し変わっただけで、互いに矛盾する推測をつぎはぎしてしまい、結果として迷子になってしまうのです。
計算的なスノードーム
では、どうすればAIに「地図」や「物理法則」を持たせることができるのでしょうか? そこで登場するのがワールドモデルという考え方です。
想像してみてください。あなたの手元に、現実の世界をミニチュアサイズで再現した「スノードーム」があるとします。このスノードームはただの飾りではありません。振ったり傾けたりすると、中の雪や建物が現実の物理法則に従って動く、精密なシミュレーターなのです。
ワールドモデルとは、まさにAIが頭の中に持つ計算的なスノードームのようなものです。
AIはこの内部モデルを使って、「もし電車に飛び込んだらどうなるか?」といった危険な行動を、現実世界で試すことなくシミュレーションできます。ケネス・クレイグという心理学者が1943年に提唱した「小規模な外界モデル」という概念が、ディープラーニングの力で現代に蘇ったとも言えるでしょう。
これがあれば、AIは次のようなプロセスで思考できるようになります。
- 現状認識: 今、世界はどうなっているか(スノードームの状態を見る)
- 予測(シミュレーション): もし私がこう動いたら、世界はどう変化するか(スノードームの中で予行演習する)
- 計画と行動: 最も良い結果になる行動を選んで、現実世界で実行する
これこそが、単なる「次の単語の予測」を超えて、AIが現実世界で計画的に行動するために不可欠な能力なのです。
なぜ今、LLM(大規模言語モデル)の次に来るのか
正直なところ、「世界をシミュレーションする」というアイデア自体は昔からありました。しかし、なぜ今になって主要な研究者たちがこぞってこの分野に注力しているのでしょうか?
どうやら、必要なピースが揃ったことが大きいようです。これまで不足していた動画や3Dデータ、センサーデータといった「マルチモーダルデータ」が爆発的に増え、それを処理できるだけの計算リソースも整ってきました。NVIDIAの解説によれば、物理AIシステム向けのワールドモデル構築には、ペタバイト規模のデータと数百万時間のシミュレーション映像が必要だとされていますが、現代の技術環境ならそれが可能なのです。
さらに、ロボティクスや自動運転といった産業界からの「待ったなし」の需要も後押ししています。テキストチャットの中だけで完結するならLLMで十分かもしれませんが、工場でロボットを動かしたり、車を自動運転させたりするには、物理的な因果関係の理解が避けて通れません。以前Metaで働いていたYann LeCun氏は、現在のLLMは知識の蓄積には優れていても、物理的な直感や計画能力においては「家猫よりも劣る」とさえ指摘し、ワールドモデルこそが真の知能への道だと主張しています。
こうして見ると、ワールドモデルは単なる技術トレンドの一つではなく、AIが「言葉の世界」から「物理的な現実」へと進出するための、必須の装備だという気がしてきませんか?
さて、ここで一つの疑問が浮かびます。AIの頭の中に世界を作るとして、それは具体的にどうやって作るのでしょうか? 視覚的な3D空間として再現するのか、それとももっと抽象的な計算式として保持するのか。
実はこの「作り方」を巡って、AI界の巨匠たちの間でも意見が分かれているようなのです。次章では、彼らがそれぞれの哲学を賭けて挑む、異なるアプローチについて見ていきましょう。
巨匠たちの賭け:空間知能か、抽象的な予測か
前章で、AIが賢く振る舞うためには、頭の中に「計算的なスノードーム(ワールドモデル)」を持つ必要があるとお話ししました。これがあれば、AIは現実世界で失敗する前に、脳内で予行演習ができるようになります。
しかし、ここで面白い問題が浮上します。「そのスノードーム、具体的にどうやって作るの?」 という点において、世界トップレベルの研究者たちの意見が真っ二つ、いや三つに割れているようなのです。
どうやら、AI界の巨匠たちは、それぞれ全く異なるアプローチで「世界」を記述しようと賭けに出ているようです。このセクションでは、彼らが描く未来の地図を広げてみましょう。これを知っておくことは、単なる技術談義ではなく、今後AIが「空間認識」に強くなるのか、「計画」に強くなるのか、それとも「シミュレーション」自体を作り出すのか、ビジネスや実生活での使いどころを見極めるための羅針盤になるはずです。
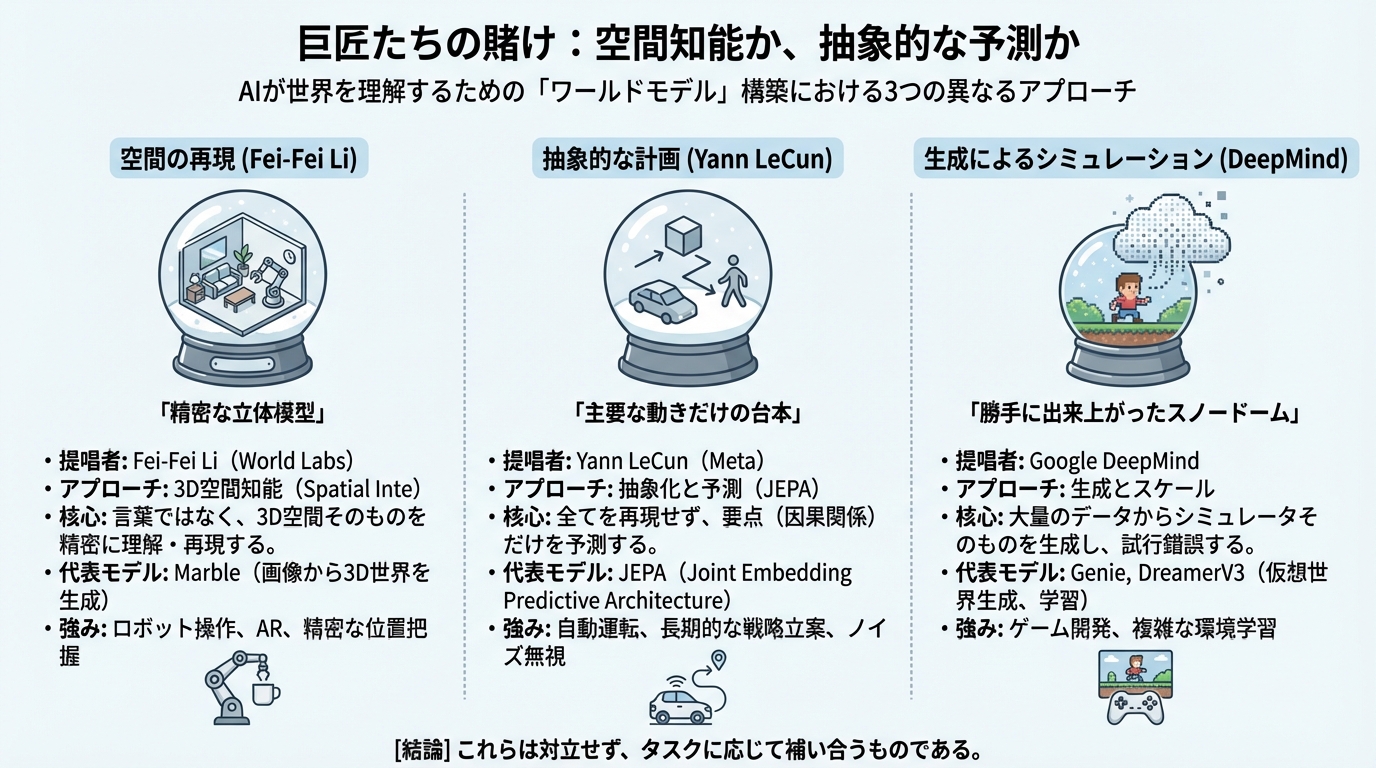
「言葉」を捨て、3Dの空間へ(Fei-Fei Liの空間知能)
まず一人目の巨匠は、「AIの目」を進化させてきたスタンフォード大学のフェイフェイ・リー(Fei-Fei Li)氏です。彼女のアプローチは非常に直感的で、「言葉ではなく、空間そのものを理解させよう」 というものです。
リー氏は、「言語は自然界に存在するものではない」と断言します。確かに、私たちは言葉を覚えるずっと前から、コップを掴んだり、障害物を避けたりして物理世界と関わっていますよね。彼女は、現在のAIブームを牽引する大規模言語モデル(LLM)が言葉に依存しすぎていることに限界を感じているようです。
そこで彼女が立ち上げたWorld Labsでは、AIを2Dの画像認識から「3Dの空間知能(Spatial Intelligence)」 へと引き上げることに注力しています。
これはどういうことでしょうか。例えば、一枚の写真を見せたとき、これまでのAIは「猫がいます」と答えるのが精一杯でした。しかし、空間知能を持つAIは、その写真から「その部屋の奥行きはどうなっていて、裏側には何がありそうか」 という3D世界全体を想像し、生成しようとします。実際にWorld Labsが開発するMarbleというモデルは、画像などから3D世界全体を作り出すことを目指しています。
これは、スノードームの中身を「言葉の説明書き」で作るのではなく、「精密な立体模型」 として作り込むアプローチと言えるでしょう。ロボットに家事をさせたり、AR(拡張現実)で新しい体験を作ったりする場合、この「空間的な理解」が圧倒的な強みになる気がします。
全部は見ない。「要点」だけを予測する(Yann LeCunの抽象化)
一方、Meta社のAIトップであるヤン・ルカン(Yann LeCun)氏は、全く別の角度から攻めています。彼のアプローチを一言で言えば、「全てを再現する必要はない、要点だけを予測しろ」 というものです。
先程述べた通り、ルカン氏は現在の生成AIについて、知識はあっても物理的な直感がないため「家猫よりも劣る」と手厳しい評価を下しています。彼が提唱するのは、JEPA(Joint Embedding Predictive Architecture) と呼ばれる新しいアーキテクチャです。
少し難しそうな名前ですが、考え方は私たちの日常感覚に近いです。例えば、あなたが車を運転しているとします。目の前のトラックがどう動くかは真剣に予測しますよね? でも、道端の街路樹の葉っぱが風でどう揺れるかまで、いちいち予測しているでしょうか? おそらくしていないはずです。
ルカン氏が批判するのは、現在の画像生成AIが「葉っぱの揺れ(ピクセル単位の詳細)」まで予測しようとして計算リソースを浪費している点です。そうではなく、「トラックが止まるか動くか」といった抽象的な意味(表現)だけを予測すればいい。そうすれば、AIは余計な情報に惑わされず、より遠い未来まで計画を立てられるようになるはずだ、というのが彼の主張です。
これはスノードームの例で言えば、中身を精密に作るのではなく、「主要な登場人物の動きだけが書かれた台本」 を持たせるようなものでしょうか。詳細な見た目は省く代わりに、物語の展開(因果関係)を正確に捉えようとする試みです。
夢の中で練習する(DeepMindの生成とスケール)
そして三つ目の勢力が、Google DeepMindなどが進める「圧倒的な計算量と生成」 によるアプローチです。彼らは、とにかく大量のデータを読み込ませて、「スノードーム(シミュレータ)そのものを生成してしまえばいい」 と考えている節があります。
象徴的なのが、DeepMindが発表したGenieというモデルです。これはスーパーマリオのようなゲーム画面を学習させることで、「操作可能な仮想世界」を丸ごと生成してしまいます。単に映像を作るだけでなく、コントローラーでキャラクターを動かすことまでできるのです。
また、彼らの開発したDreamerV3というAIは、Minecraftの世界で「ダイヤを掘る」という難題をクリアしました。興味深いのは、AIが「夢(内部シミュレーション)」の中で何百万回もトライ&エラーを繰り返し、現実(ゲーム内)での成功率を高めたという点です。
これは、スノードームを一つ一つ手作りするのではなく、「大量のビデオを見せたら、勝手にスノードームが出来上がっていた」 というような、ある種の創発に賭けるアプローチです。データさえあれば何でもシミュレーションできるようになる可能性がありますが、同時に膨大な計算リソースを必要とします。
私たちは何に賭けるべきか
さて、三者三様の「賭け」を見てきましたが、これらは必ずしも対立するものではなく、互いに補い合うものだと私は考えています。
- 空間の再現(Fei-Fei Li): ロボット操作やARなど、精密な位置把握が必要なタスクに不可欠。
- 抽象的な計画(Yann LeCun): 自動運転や長期的な戦略立案など、ノイズを無視して本質を捉えるタスクに有効。
- 生成によるシミュレーション(DeepMind): ゲーム開発や、試行錯誤が必要な複雑な環境の学習に強力。
私たちユーザーとしては、AIを導入する際に「このタスクにはどのタイプの“世界理解”が必要か?」を見極める視点を持つことが重要ではないでしょうか。
しかし、ここで一つ注意が必要です。「世界をシミュレーションできる」ことと、「きれいでリアルな動画を作れる」ことは、似ているようで全くの別物なのです。次章では、多くの人が陥りがちなこの罠――「きれいな動画」と「正しい理解」の決定的な溝について、具体的に見ていきましょう。
「きれいな動画」と「正しい理解」の決定的な溝

前章では、研究者たちがそれぞれの賭けに出ている様子を見てきました。ここで私たちは、少し立ち止まって冷静になる必要がありそうです。なぜなら、最近のAIが見せる「圧倒的にリアルな映像」に、私たちの目が眩まされそうになっている気がするからです。
OpenAIのSoraが生成した動画を初めて見たとき、その美しさに息を呑んだ方も多いのではないでしょうか。水面の反射、街の喧騒、すべてが本物のように見えます。これを見れば「AIはもう物理法則を完全に理解した」と思いたくもなります。しかし、どうやら「映像がきれいであること」と「世界を正しく理解していること」の間には、私たちが思う以上に深く、決定的な溝があるようなのです。
「物理法則」を知らない高画質な夢
少し意地悪な見方をしてみましょう。Soraのような動画生成AIは、確かに驚くほどリアルな映像を作ります。しかし、研究者たちが詳しく調べると、そこには奇妙な綻びが見つかることがあります。
例えば、コップがテーブルから落ちたのに割れなかったり、液体が不思議な動きをしたりする。あるいは、人が歩いているのに足跡がつかない、といった現象です。ある調査論文では、こうしたモデルが物理法則の一貫性において限界を抱えていると指摘されています。
これはなぜでしょうか。極端な言い方をすれば、動画生成AIは「世界がどう動くか(物理)」を計算しているのではなく、「次に来そうなピクセルの色(統計)」を計算しているだけかもしれないからです。
それはまるで、物理学を全く知らない天才画家が、何千時間ものビデオを見て「ここでは水しぶきがこう飛び散るはずだ」と絵を描き続けているようなものです。見た目は完璧に近いのですが、裏側にある「重力」や「摩擦」といったルール(因果関係)を計算式として持っているわけではありません。だから、ふとした瞬間に「物理的にありえない動き」 を平気で描いてしまう。これでは、失敗が許されないロボットの制御や自動運転のシミュレーションには怖くて使えませんよね。
触れる世界、操作できる世界
では、本当の意味で「世界を理解した」とはどういう状態を指すのでしょうか。そのヒントは、「操作できるかどうか(Interactivity)」 にあるような気がします。
Google DeepMindが発表したGenieというモデルは、この点で非常に示唆的です。Genieは、たった一枚の画像から、スーパーマリオのような「実際にプレイできるゲーム」 を生成してしまいます。
ただ映像を流すだけではありません。ユーザーが「右へ行け」「ジャンプしろ」と指示を出せば、キャラクターはその通りに動き、背景もそれに合わせて変化します。これは、AIが「ジャンプしたら重力で落ちてくる」「壁にぶつかったら止まる」という因果関係のルールを、ある程度理解していなければ不可能な芸当です。
「見るだけの映画」と「操作できるゲーム」。この違いこそが、動画生成AIとワールドモデルの分かれ目ではないでしょうか。もし私たちがビジネスでAIを使おうとするなら、求めているのは「美しいプレゼン動画」なのか、それとも「施策を試せるシミュレーター」なのかを区別する必要があります。
画質が悪くても「賢い」ことはある
「世界を正しく理解する」という点において、もっと極端な例があります。それが、同じくDeepMindが開発したDreamerV3です。
このAIが挑戦したのは、Minecraft(マインクラフト)の世界でダイヤモンドを手に入れることでした。ご存知の方も多いと思いますが、マインクラフトの世界はカクカクしたブロックでできており、映像としてのリアリティはSoraに遠く及びません。
しかし、DreamerV3がやっていることは驚異的です。ダイヤモンドを手に入れるには、「木を切る」→「作業台を作る」→「木のツルハシを作る」→「石を掘る」……といった具合に、長く複雑な手順を踏む必要があります。AIは現実世界(ゲーム画面)からのフィードバックを受け取りながら、自分の頭の中にあるワールドモデルで「夢(シミュレーション)」 を見続けました。「こうすれば石が取れるはずだ」「次はこれを作ろう」と、何百万回もの予行演習を脳内で行ったのです。
その結果、人間のデータを一切使わずに、ゼロからダイヤモンド採掘という高度なタスクを達成しました。
ここからわかるのは、AIの賢さにとって「画質の良さ」は必須ではないということです。むしろ、余計な情報を削ぎ落としたシンプルな世界(抽象化された表現)の方が、因果関係を捉えやすく、遠い未来まで見通す計画(プランニング)には有利な場合さえあります。
私たちは何を選ぶべきか
こうして見ると、私たちが「ワールドモデル」という言葉に抱く期待には、二つの異なる方向性があることに気づきます。
- 視覚的なリアリティ: Soraのように、現実と見紛うような映像を作る能力。エンターテインメントや広告、クリエイティブな用途ではこれが正義です。
- 因果的な正しさ: DreamerV3のように、見た目は粗くても「AをすればBになる」というルールを正確に把握し、計画を立てる能力。ロボティクスや経営シミュレーションなど、失敗できない実務ではこちらが重要です。
今のところ、この二つを完璧に両立した「究極のモデル」はまだ存在しないようです。だからこそ、最新のAIニュースを見るときは、「これは絵が上手いAIなのか、それとも理屈が分かっているAIなのか?」 という視点を持つと、本質が見えてくる気がしませんか?
さて、ここで一つ現実的な問題にぶつかります。「理屈が分かっているAI」を作るには、ロボットを何万回も転ばせたり、車を何度もぶつけたりして「失敗のデータ」を集める必要があります。しかし、現実世界でそんなことをしたら大変なことになりますよね。
そこで登場するのが、「データがなければ、AI自身に作らせればいい」 という、ちょっと常識外れな発想です。次章では、この逆転の発想がどのようにビジネスや開発の現場を変えつつあるのか、具体的な実用化の道筋と共に見ていきましょう。
データ不足をモデルで補う「逆転」と実用化の道

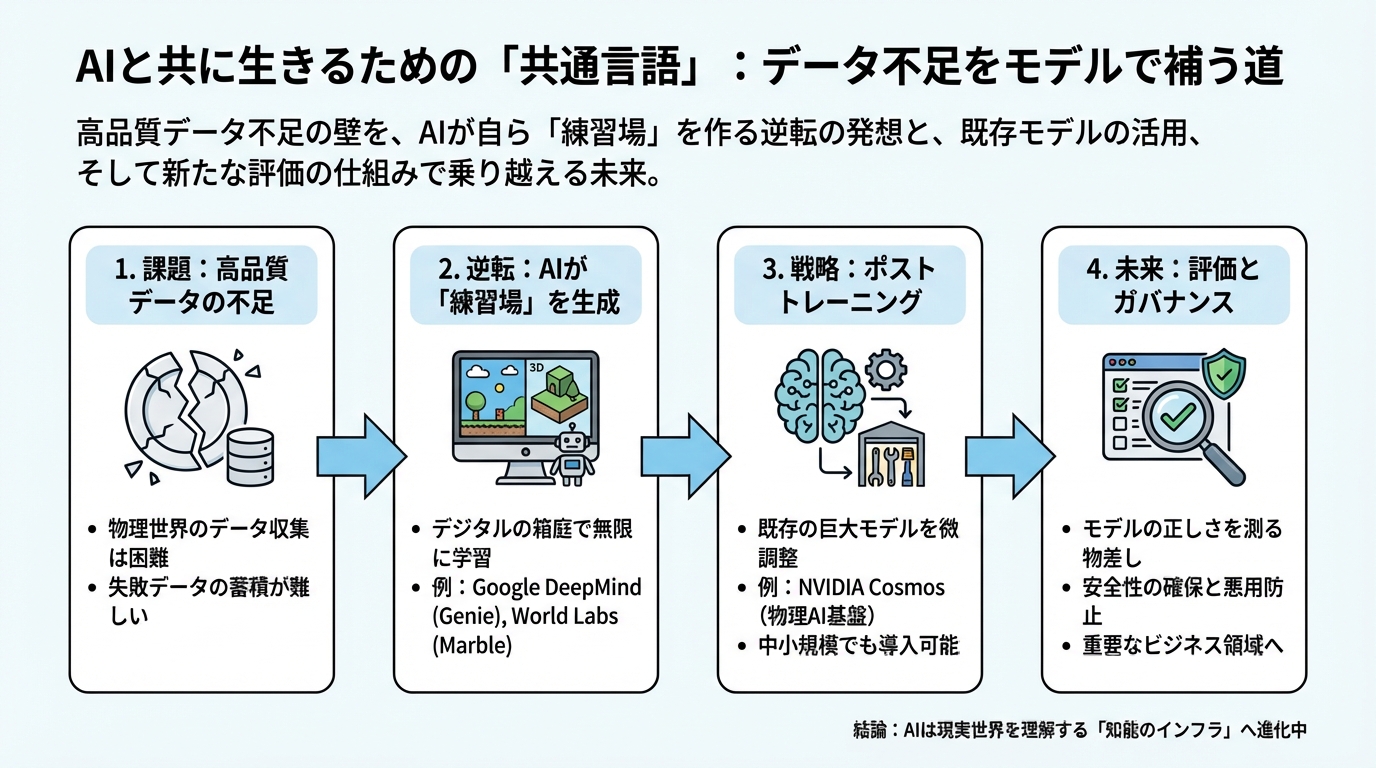
前章の最後で、私たちは「失敗のデータ」を集めることの難しさに触れました。ロボットに家事を教えるために、お皿を何千枚も割らせるわけにはいきませんよね。ここで、多くの研究者や企業が直面しているのが「高品質な学習データが圧倒的に足りない」という壁です。
テキストデータならインターネット上に山ほどありますが、物理法則や空間の奥行きを含んだ「世界のデータ」は、そう簡単には手に入りません。スタンフォード大学のFei-Fei Li氏も、空間知能に関するデータは言語データのように何世紀もかけて蓄積されたものではないため、データの整備が大きな課題だと指摘しています。
しかし、どうやら研究者たちは、この壁を乗り越えるために驚くべき「逆転」の発想にたどり着いたようです。
AIがAIのための「練習場」を作る
その発想とは、「データがないなら、AI自身に学習用の世界を作らせてしまえばいい」 というものです。現実世界でデータを集めるのが大変なら、デジタルの世界の中にリアルな「箱庭」を作り、そこでAIを育てればいいじゃないか、というわけです。
例えば、Google DeepMindが開発したGenieというモデルを見てみましょう。これは1枚の画像やテキストから、操作可能な2Dのゲーム世界(プラットフォーマーゲームのような環境)を生成します。重要なのは、人間が遊ぶためではなく、AIエージェント(動作するAI)を訓練するための「無限の練習場」を自動で作れるという点です。これなら、何回失敗しても、何回ゲームオーバーになっても、現実世界には何の影響もありません。
さらに、Fei-Fei Li氏が率いるWorld LabsはMarbleというモデルを発表しました。これは写真などの静的なデータから、中に入って歩き回れるような「3D世界全体」を作り出します。これを使えば、例えば自動運転車に「見たことのない街」を走らせる練習を、机上のシミュレーションだけで延々と繰り返すことができるようになるかもしれません。
このように、「世界を学ぶためのモデル」が、いつの間にか「学ぶための世界を提供する装置」へと役割を変え始めているのです。これはAI開発におけるエコシステムの大きな転換点ではないでしょうか。
巨人の肩に乗る「ポストトレーニング」戦略
さて、ここで皆さんはこう思うかもしれません。「そんな高度な世界モデル、GoogleやNVIDIAのような巨大企業にしか作れないんじゃないの?」と。
正直なところ、ゼロからワールドモデルを作るには、ペタバイト級のデータと数百万ドル規模のGPUコストがかかると言われており、膨大な投資が必要です。私たち一般の企業や開発者が、いきなりこれに挑むのは無謀でしょう。
では、どうすればいいのでしょうか? どうやら現実的な解は、「既存のすごいモデルを借りてきて、自分の仕事に合わせて微調整する」 という戦略にあるようです。これを専門用語で「ポストトレーニング(事後学習)」 と呼びます。
NVIDIAが発表したCosmosというプラットフォームは、まさにこのために用意されました。彼らは「物理AIのための基盤」となる巨大なワールドモデルをあらかじめ用意してくれています。
例えば、あなたが「倉庫で荷物を運ぶロボット」を開発したいとします。ゼロから物理法則を教える必要はありません。Cosmosのような基盤モデル(物理の常識を知っているAI)を持ってきて、そこにあなたの倉庫のデータや、特有の作業ルールを追加で教え込む(ポストトレーニングする)だけで済むのです。これは、既製品の高性能なスーツを買ってきて、自分の体型に合わせて裾上げをするようなものでしょうか。これなら、中小規模のプロジェクトでもワールドモデルの恩恵を受けられそうです。
「作る」よりも「測る」がビジネスになる?
最後に、少し視点を変えてみましょう。これからのワールドモデル時代において、実は「モデルを作ること」以上に重要な、そして大きなビジネスチャンスになり得る領域があるような気がしています。
それは、「そのモデルが本当に正しいか?」を評価し、安全を守る仕組み(ガバナンス) です。
前章でも触れましたが、動画生成AIはもっともらしい嘘(物理的な間違い)をつくことがあります。しかし、現在の技術界には、ワールドモデルが「どれくらい正しく因果関係を理解しているか」を測る標準的な物差し(ベンチマーク)がまだ十分にありません。「見た目がきれいだからOK」では、怖くてロボットには使えませんよね。
また、リアルなシミュレーションができるということは、悪意のある人間が「犯罪の計画」や「危険な実験」のシミュレーションに使ってしまうリスクも孕んでいます。そのため、安全性の確保や悪用の防止といったガバナンスの領域は、今後、技術開発と同じくらい、あるいはそれ以上に重要なテーマになっていくでしょう。
結論:AIと共に生きるための「共通言語」
ここまで、4つの章にわたってワールドモデルの現在地を見てきました。
- 言葉だけでなく「世界の仕組み」を理解しようとするAIの進化
- 研究者たちの異なるアプローチ(視覚か、予測か、生成か)
- 「きれいな映像」と「正しい理解」の間の深い溝
- そして、AI自身が練習場を作り出し、私たちがそれを使いこなす未来
ワールドモデルは、単に「リアルな動画が作れるツール」ではありません。それは、AIが私たちの住む物理世界を理解し、私たちのパートナーとして現実社会で活動するための「知能のインフラ」 なのではないでしょうか。
私たちが「コップを落としたら割れる」と直感でわかるように、AIも同じ感覚(内部モデル)を持つことができれば、言葉を尽くして指示しなくても、あうんの呼吸で動いてくれる日が来るかもしれません。もちろん、そのためにはデータの壁や評価の難しさといった課題を一つずつクリアしていく必要があります。
さて、あなたの目の前にあるビジネスや生活の課題に、この「世界を知るAI」はどう役立ちそうでしょうか? 画面の中だけのAIから、現実世界へ飛び出すAIへ。その物語は、まだ始まったばかりです。
調査手法について
こちらの記事はデスクリサーチAIツール/エージェントのDeskrex.AIを使って作られています。DeskRexは市場調査のテーマに応じた幅広い項目のオートリサーチや、レポート生成ができるAIデスクリサーチツールです。
調査したいテーマの入力に応じて、AIが深堀りすべきキーワードや、広げるべき調査項目をレコメンドしながら、自動でリサーチを進めることができます。

また、ワンボタンで最新の100個以上のソースと20個以上の詳細な情報を調べもらい、レポートを生成してEmailに通知してくれる機能もあります。
ご利用をされたい方はこちらからお問い合わせください。
また、生成AI活用におけるLLMアプリ開発や新規事業のリサーチとコンサルティングも受け付けていますので、お困りの方はぜひお気軽にご相談ください。
市場調査やデスクリサーチの生成AIエージェントを作っています 仲間探し中 / Founder of AI Desk Research Agent @deskrex , https://deskrex.ai


コメント