
はじめに:AIの「検索のやり方」が変わるかもしれない
「grep」や「bash」という言葉を聞いたことはありますか。プログラマーが毎日のように使っている、ちょっと地味なコマンドです。
そんな昔からあるシンプルな道具が、いまAIの世界で再評価されています。きっかけは2026年5月に発表されたDCI(Direct Corpus Interaction)論文。タイトルは「Beyond Semantic Similarity: Rethinking Retrieval for Agentic Search via Direct Corpus Interaction」、日本語にすると「意味的な近さの先へ:エージェント型検索のための直接コーパス操作という発想で検索を見直す」といったところでしょうか。
この論文がやっていることを一言で言うと、こうなります。
LLMに、図書館の棚に自分で入って、grepやbashで本文を直接探させてみたら、ベクトル検索よりも精度が上がってコストも下がった。
「え、それだけ?」と思うかもしれません。でも、これが意外と大事件なんです。
最近よく聞く「RAG」という言葉、ご存じでしょうか。Retrieval-Augmented Generationの略で、LLMが質問に答えるときに、関連する文書を検索してから回答を作る仕組みのことです。ChatGPTに社内文書を読み込ませて答えさせる、というような使い方を思い浮かべてもらえれば近いです。
RAGの研究はこれまで、「もっと賢い埋め込みモデルを作る」「rerankerで結果を並び替える」「文書を上手に分割する」といった方向で進んできました。要するに、検索エンジンの中身をどう磨くか、という勝負だったわけです。
DCI論文が問いかけているのはもっと根っこの部分です。「そもそも検索エンジンを通してから読む、という構造自体が、AIエージェントには向いていないんじゃないか」と。
この記事では、この論文の中身を初学者の方にも分かるように丁寧に解説していきます。ちょっと専門的な話も出てきますが、図書館や日常の例えを使いながら進めるので、安心して読み進めてください。途中、ビジネスや今後のトレンドについての話も少しだけ挟みます。
それでは、まず「これまでのRAGの何が問題だったのか」から見ていきましょう。
これまでのRAGがぶつかっていた壁

まず「これまでのRAG」がどう動いていたかを、おさらいさせてください。ここを理解すると、DCIの面白さが立ち上がってきます。
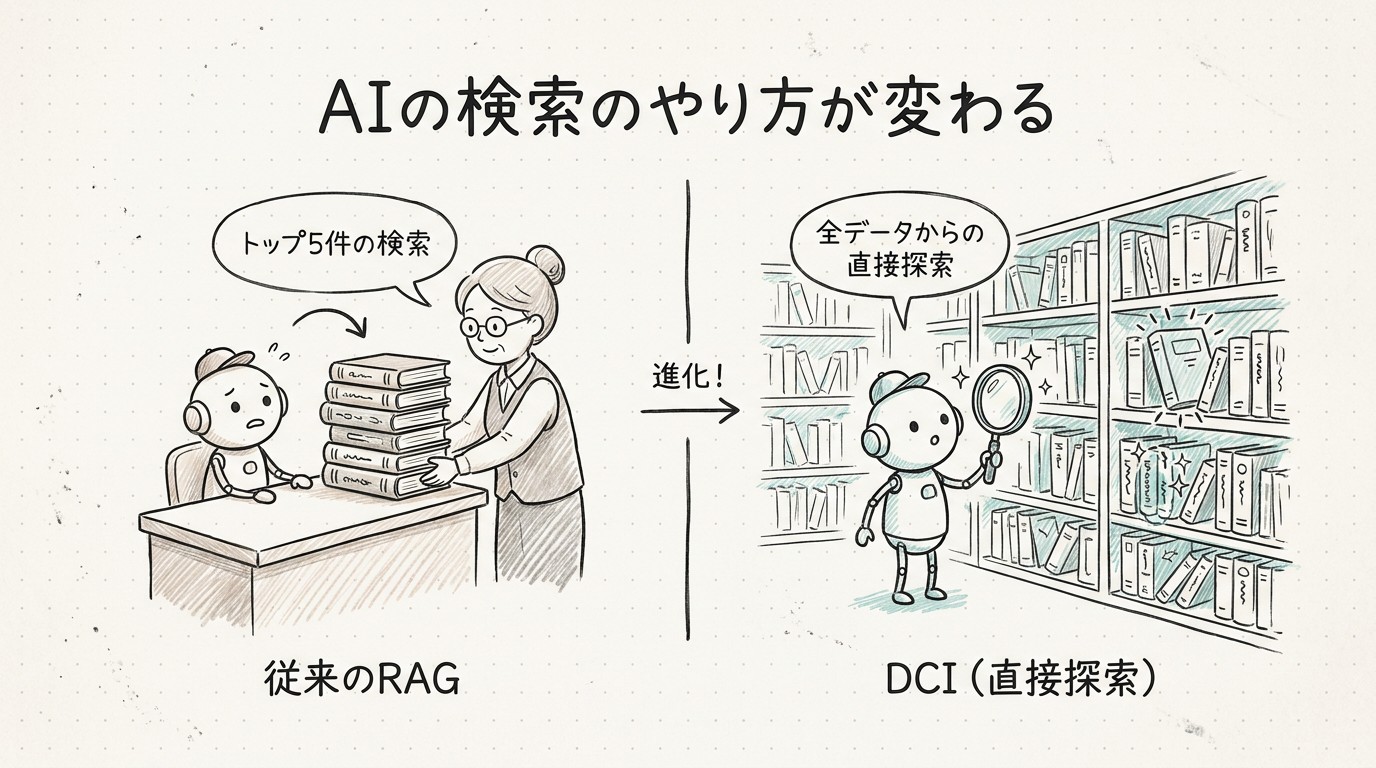
RAGは「司書に質問して、本を5冊持ってきてもらう」仕組み
イメージしやすいよう、図書館で例えてみます。
あなたが「明治時代の鉄道事故について調べたい」と図書館の司書さんに頼んだとします。司書さんは過去の知識を使って「明治時代、鉄道、事故」というキーワードに近そうな本を、たとえば5冊選んで持ってきてくれます。あなたはその5冊を読んで、答えを探す。これが従来のRAGです。
技術的に言うと、こうなります。
- 質問をベクトルという数値の集まりに変換する(「埋め込み」と呼びます。質問の意味を数字の組み合わせで表現したもの、と理解してください)
- あらかじめ作っておいた「全文書の埋め込み一覧」と比較して、意味的に近い順に並べる
- 上位k件(よくあるのは5件とか10件)を取り出して、LLMに渡して読ませる
この「上位k件だけ取る」のを「top-k検索」と呼びます。検索結果を絞らないとLLMに渡せる文字数を超えてしまうので、どこかで切る必要があるんですね。
でも、必要な本が6冊目に入っていたら?
ここに問題があります。司書さんが選んだ5冊に答えが書いていなかったら、もうゲームオーバーなんです。6冊目に大事な記述があったとしても、あなたはそれを読むチャンスがありません。
DCI論文の著者たちはこれを「検索段階で証拠を落とすと、後から回収できない」と表現しています。後ろに控えているLLMがどれだけ賢くても、読まされていない文書のことは知りようがないわけです。
もっと厄介な「弱い手がかり」問題
もう一つ、これまでのRAGが苦手にしていたパターンがあります。「複数の弱い手がかりを組み合わせないと答えに辿り着けない」ケースです。
たとえばこんな質問を考えてみてください。
1907年に発生し、当時の総理大臣が責任を取って辞任するきっかけになった鉄道事故は何ですか?
この質問に答えるには、「1907年」「総理大臣の辞任」「鉄道事故」という3つの手がかりを組み合わせる必要があります。それぞれの手がかりは弱いので、ベクトル検索で一発で正解の本を引き当てるのは難しい。普通は、まず1907年あたりの事故を一覧して、それから辞任に関わる情報を別途調べて、合致するものを探す、という段階的な作業になります。
ところが従来のRAGは、最初の1回の検索で勝負が決まる仕組みです。途中で「あ、この情報も必要だな」と思っても、検索のやり方を変えながら掘り進む、ということがやりにくい。
検索と読解が「分離」されている
ここで効いてくるのが、専門用語で言う「検索と読解の分離」という概念です。
従来のRAGでは、まず検索エンジン(retriever)が動いて、終わったらLLM(読解担当)にバトンを渡す。検索が終わったら、もう戻れない。一方通行のリレーみたいな構造なんです。
人間の調査行動を思い浮かべてみてください。本を1冊手に取って、最初の章を読んで、「これは違うな」と思って書架に戻し、別の本を探す。あるいは「ここに出てきた人名、別の本で見た気がする」と気付いて、もう一度別の棚に行く。私たちは、検索と読解を行ったり来たりしながら調べ物をします。
従来のRAGは、この行ったり来たりができません。これがagentic search(自律的に探索するAIエージェントによる検索)の文脈では、特に痛い制約だったんです。
DCI論文の中心的な問題提起は、ここにあります。「retrieverを賢くする努力を続けるよりも、そもそも検索のやり方そのものを変えた方がいいんじゃない?」と。
次のセクションでは、その「新しいやり方」であるDCIが、具体的に何をしているのかを見ていきます。
DCIってなに?図書館の棚に自分で入る検索

ここからが本題です。DCI(Direct Corpus Interaction)が具体的に何をしているのか、見ていきましょう。
司書を介さず、自分で棚に入る
さきほどの図書館の例えに戻ります。
- 従来のRAG:司書さんに「明治時代の鉄道事故について」と頼んで、5冊持ってきてもらう
- DCI:自分で書庫に入って、本を引き抜きながら必要な情報を探す
DCIは要するに、AIエージェントを「書庫に放り込む」設計です。司書(retriever)を介さない。インデックスもベクトルDBも使わない。ただ生の文書ファイルがそこにあって、エージェントが自分の手で触りに行く。
「自分の手」にあたるのが、grep、find、bash、ファイル読み込みといった、UNIXに昔からある汎用ツールです。
grepとbashって何をする道具?
ちょっとここでgrepとbashの説明をしておきます。すでにご存じの方は読み飛ばしてください。
grepは、ファイルの中から特定の文字列を探すコマンドです。「このフォルダの中の全テキストファイルから『鉄道事故』という言葉を含む行を探して」と頼むと、該当する行をズラッと並べてくれます。プログラマーなら毎日使う基本ツールですね。
bashは、コマンドを組み合わせて実行できる「対話的なシェル」と呼ばれる環境のことです。「grepの結果をさらにソートして、上位10件だけ出して」みたいな複合的な操作を、|(パイプ)という記号で繋いで実行できます。
findは、条件に合うファイルを探すコマンドです。「2024年以降に更新されたMarkdownファイルだけ」みたいな絞り込みができます。
これらを組み合わせると、人間が書庫を探し回るような作業を、コマンドベースで一気にやれます。
DCIの探索プロセスを具体例で
さっきの「1907年の鉄道事故と総理大臣の辞任」の質問を、DCI型のエージェントがどう探すか、想像してみましょう。
- まず
grep "1907年" *.txtで、1907年に言及している全ファイルを洗い出す - 出てきた候補を眺めて、「鉄道事故」「列車衝突」あたりの言葉が一緒に出てきているファイルを絞り込む
- その中で総理大臣の名前らしき固有名詞をいくつか拾う
- 拾った人名で再度grepし、辞任に言及している箇所を探す
- 該当しそうな段落を局所的に読んで、答えを確定させる
これ、人間がやっていることそのものですよね。検索と読解と仮説の組み立てを、行ったり来たりしながら進めています。
「retrieval interface resolution」という考え方
論文の著者たちは、この発想を「retrieval interface resolution(検索インターフェースの解像度)」という言葉で説明しています。
ちょっと難しい言葉ですが、こう言い換えると伝わりやすいかもしれません。
LLMが資料に「どれくらい細かく触れるか」が、検索性能を決める。
従来のRAGでは、LLMの触り方は「クエリを投げる→top-kの文書をまるごと読む」という粗い単位に固定されていました。一方DCIでは、「文字列を直接検索する」「特定の行だけ読む」「正規表現で絞り込む」「結果をパイプで加工する」など、もっと細かい操作ができます。この「細かさ」が「解像度」というわけです。
Claude Codeと同じ発想
ここで一つ気付くことがあります。DCIがやっていることは、Claude CodeやCursorのようなコーディングエージェントが、コードベースを探るときの動きそのものなんです。
開発者がIDEで作業するとき、こんなことを日常的にやっていると思います。
- 関数名を全文検索する
- 定義にジャンプする
- 呼び出し元を一覧する
- ファイル間を行ったり来たりする
- 必要な箇所だけ読む
これをLLM自身がやれるようになったのが、ここ数年のコーディングエージェントの進化です。DCI論文は、その同じ発想を「文書検索」や「リサーチタスク」に持ち込んだ、と読むと分かりやすい気がします。
事前準備が要らないという利点
もう一つ、DCIには地味だけど大きな利点があります。事前に何も準備しなくていいんです。
従来のRAGを動かすには、まず全文書を読み込んで埋め込みを計算して、ベクトルDBに保存して……という「下ごしらえ」が必要でした。文書が増えたり更新されたりするたびに、この作業をやり直さないといけません。
DCIは違います。文書がただファイルとして置いてあれば、そのまま探索を始められます。新しい文書を追加したい?フォルダに放り込むだけ。古い文書を消したい?削除するだけ。「ローカルで変化するコーパス」と相性が良いと論文が言っているのは、この性質のことです。
これは中小企業や個人にとって、特にありがたい話かもしれません。ベクトルDBの運用コストや、埋め込みの再計算コストが要らない。手元のフォルダ構造をそのまま「AIが触る場所」にできるわけです。
次のセクションでは、このDCIが実際にどれくらいの実力を見せたのか、論文の数字を見ていきましょう。
数字で見るDCIの実力:精度もコストも良くなった
ここまで「DCIってこういう仕組みです」という話をしてきました。でも肝心なのは、本当に効くのか、というところです。論文はいくつかのベンチマークで実験をしているので、代表的な数字を見ていきましょう。
一番分かりやすい結果:BrowseComp-Plus
BrowseComp-Plusというのは、Webブラウジングを含む複雑な調査タスクを評価するベンチマークです。複数の情報源を辿って答えに行き着く力が問われます。
ここで、こんな結果が出ました。
| 構成 | 正答率 | コスト |
|---|---|---|
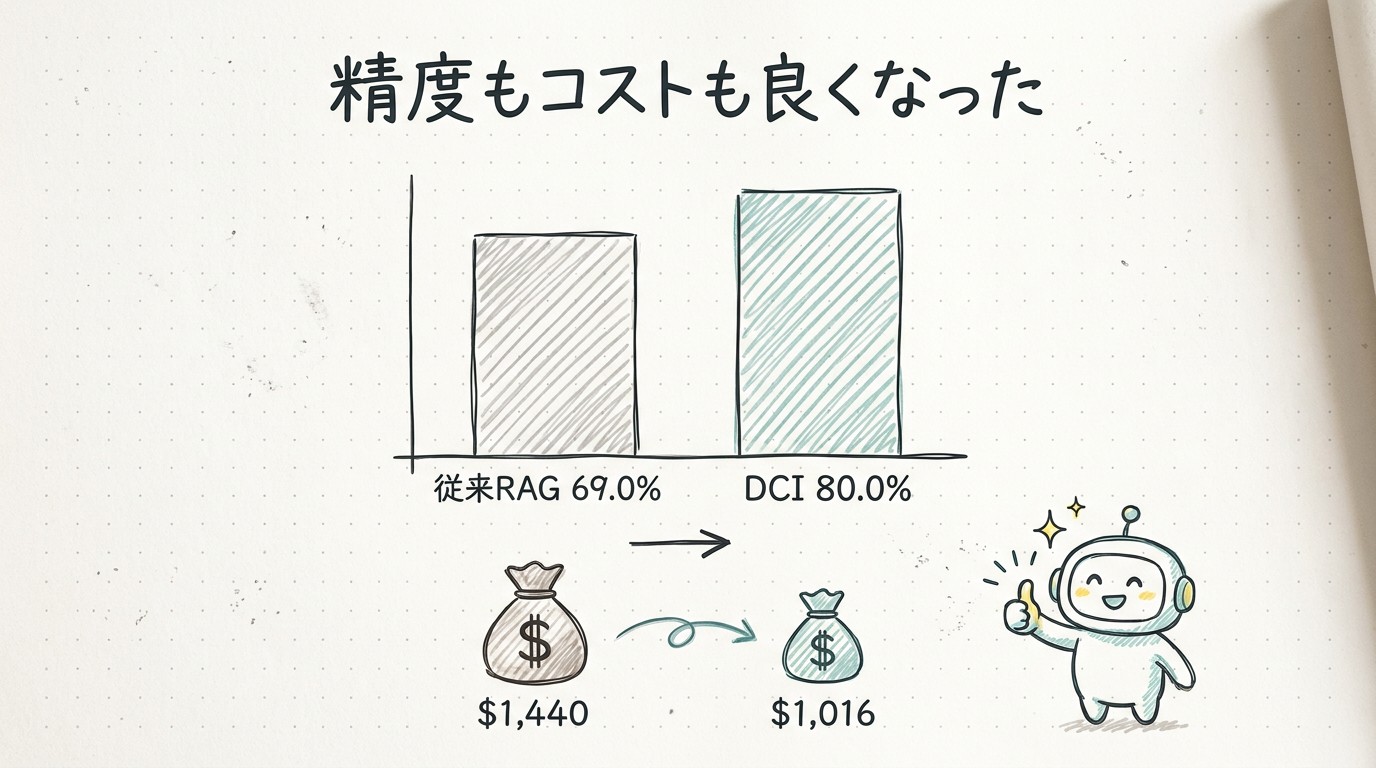
| Claude Sonnet 4.6 + 従来retriever | 69.0% | $1,440 |
| Claude Sonnet 4.6 + DCI | 80.0% | $1,016 |
| DCI-Agent-Lite(GPT-5.4 nano) | 62.9% | $93 |
注目してほしいのは、上の2行の比較です。同じClaude Sonnet 4.6を使っているのに、検索の仕組みを従来型からDCIに変えるだけで、正答率が69.0%から80.0%に上がっています。さらに、コストも$1,440から$1,016に下がっている。
ふつう、精度を上げようとするとお金がかかります。良い埋め込みモデルを使えば計算コストが増えるし、rerankerを噛ませれば余計な推論が必要になる。それなのに、DCIは精度を上げながらコストを下げている。これは普通じゃない話です。
なぜコストが下がるのか。一つの解釈はこうです。従来型は「広く拾ってからLLMに大量の文書を読ませる」ので、入力トークン数が膨らみがちでした。DCIは「必要な部分だけピンポイントで読む」ので、LLMに渡す情報量を小さく保てる。結果として、精度が上がってコストが下がるという、一見矛盾した現象が起きているわけです。
軽量版が見せた可能性
もう一つ面白いのが、3行目のDCI-Agent-Liteです。これはGPT-5.4 nanoという小型モデルを使ったDCI構成。それでも62.9%を達成しています。しかもコストは$93。
これは何を意味するでしょうか。
これまで「ハイエンドな検索性能が必要なら、Claude SonnetやGPT-5級のフラッグシップモデルを使うしかない」と思われていました。でも、検索の仕組みをDCIに変えれば、軽量モデルでも実用的な性能が出る可能性がある。
中小規模の社内文書検索や、コスト制約の厳しい用途で、これは大きなニュースになりそうです。
multi-hop QAでの圧倒的な差
multi-hop QA(マルチホップ質問応答)というのは、「複数の文書を辿って情報を組み合わせないと答えられない質問」を評価するタスクです。さきほどの「1907年の鉄道事故と総理大臣の辞任」みたいな質問を想像してください。
ここでDCIは、平均83.0%という成績を出しました。比較対象の中で最強だったretrieval-agent baselineを、30.7ポイント上回っています。30.7ポイントというのは、研究の世界では「桁違いに勝った」と表現してもいいレベルの差です。
なぜここまで差がつくのか。マルチホップQAは、まさにDCIが得意とする「弱い手がかりを段階的に組み合わせる」タスクだからです。1回のクエリで答えが出るような単純な質問ではなく、検索しながら仮説を更新し続ける必要がある。この行動を一発検索のRAGに押し込めるのは、構造的に無理がある、ということなのでしょう。
IR rankingでもしっかり強い
IR ranking(情報検索のランキング評価)は、もっと伝統的な「正解文書を上位に並べられたか」を評価するタスクです。ここでDCIは平均NDCG@10で68.5を達成しました。
NDCG(Normalized Discounted Cumulative Gain)というのは、検索結果の並び方の良さを0から1の間で評価する指標です。0.685はかなり良い数字で、従来の手法を上回っています。
つまりDCIは、「複雑なエージェント型タスクで強い」だけじゃなくて、「シンプルなランキング評価でも従来法を上回れる」ということです。一発検索だけの世界でも、ちゃんと戦える。
数字を眺めて見えてくること
ここまでの数字をまとめると、こんな印象になります。
- 精度:BrowseComp-Plusで+11pt、multi-hop QAで+30.7pt、IR rankingでも上回り
- コスト:従来比で約29%の削減($1,440→$1,016)
- 軽量モデルでも実用域に届く
「精度向上とコスト削減を同時に達成」という結果は、技術選定の判断を大きく揺さぶります。これまで「精度を取るならお金がかかる」「コストを抑えるなら精度を諦める」というトレードオフの中で設計してきた人にとって、DCIはその前提を崩す存在になりそうです。
ただし、ここまで読んで「DCIが万能なんだ」と思うのは早とちりです。実は、もっと面白い分析結果があります。次のセクションでは、「なぜDCIが強いのか」という勝因の中身に踏み込んでいきます。
なぜ強いのか:勝因は「広く拾う」ではなく「深く掘る」

ここがこの論文で一番面白いところだと、個人的には思っています。普通に考えれば「DCIが強いのは、もっとたくさんの正解文書を見つけられるからだろう」と思いますよね。ところが、論文の分析を読むと、そうじゃないんです。
意外な事実:文書カバレッジでは負けている
論文がBrowseComp-Plusで詳しく調べたところ、こんな結果が出ました。
文書カバレッジは、ベクトル検索の方が高い。DCIはむしろ低い。
「文書カバレッジ」というのは、質問に答えるための正解文書のうち、検索結果に何件含まれているかを示す指標です。要するに「正解の取りこぼしの少なさ」みたいなものですね。
これだけ見ると、DCIは負けています。正解文書を取ってくる量では、ベクトル検索の方が上手い。なのに、最終的なend-to-endの正答率ではDCIが勝っている。
これ、面白くないですか。
鍵は「localization」、つまり証拠を絞り込む力
種明かしをすると、DCIの勝因は「localization」と呼ばれる能力にありました。
localizationを日本語にすると「局所化」とか「位置特定」になりますが、ここでは「見つけた文書の中で、必要な証拠を小さなスパンに絞り込む力」と理解してください。
ベクトル検索は、関連しそうな文書を10冊持ってきてくれます。でも、その10冊それぞれが分厚かったら、LLMはどこを読めばいいか分からない。結果、無関係な部分も含めて読まされて、ノイズに惑わされる。
DCIは、5冊しか持ってこなくても、それぞれの本の中で「ここの段落」「この行」までピンポイントで指し示せる。grepで該当行だけ抜き出せるし、ファイルの特定箇所だけ読める。だから、少ない情報量でも答えに辿り着ける。
「広く拾う検索」から「深く掘る探索」へ
これは検索研究にとって、けっこう大きなパラダイム転換だと思っています。
これまで検索の評価軸は、「recall(取りこぼしの少なさ)」と「precision(無駄のなさ)」が中心でした。「いかに広く正解を拾えるか」が勝負だったわけです。
DCIが示しているのは、「広く拾えなくても、拾った後を深く掘れれば勝てる」という新しい価値観です。検索の質を、文書単位ではなく、もっと小さなスパン単位で評価し直す必要があるかもしれません。
アブレーション分析が語ること
論文では、DCIが使えるツールを制限して、どれがどれくらい貢献しているかも調べています。これを「アブレーション分析」と呼びます。
結果はこうでした。
| 構成 | 従来baselineからの改善 |
|---|---|
| read+grep のみ | +16ポイント |
| read+grep+bash | +28ポイント(+12ポイント追加) |
最低限readとgrepだけ与えても、すでに従来法を16ポイント上回ります。さらにbashを解放してパイプ処理や複雑な絞り込みができるようにすると、もう12ポイント伸びる。
ここから読み取れるのは、DCIの本質が「全文を片っ端から読むパワー」ではなく、「局所検索と操作を組み合わせる柔軟性」にあるということです。検索行動の多くは、grepやbashのパイプ処理、正規表現、局所読み取りで構成されていて、全文読みには依存していません。
「組み合わせる力」が効いている
もう一つの解釈として、こんな見方もできます。
grep単体だと、文字列マッチしかできない。でもbashと組み合わせると、grepの結果をさらに絞ったり、別のコマンドで加工したり、条件を重ねたりできます。これは「操作の合成可能性(compositionality)」と呼ばれる性質で、プログラミングの基本的な強みです。
DCIは、この「操作を組み合わせる力」をLLMに与えています。retrieval APIだと、できることは「クエリを投げてtop-kを返す」だけ。組み合わせの自由度がほぼゼロです。ところがgrepとbashの世界では、組み合わせ方が無限にある。
LLMが推論能力を持つようになった今、「与えられた候補を選ぶ」より「自分で組み合わせを考えて操作する」方が、本領を発揮できる場面が増えてきた、と読めるかもしれません。
人間の調査行動との重なり
ここまで読んできて、「これって人間の調べ方そのものでは?」と感じた方も多いと思います。
優秀なリサーチャーが本を1冊読むとき、最初のページから順番に読むことは少ないですよね。目次を見て、関係ありそうな章を絞って、その中でキーワード検索して、引っかかった段落の前後を読む。手がかりが見つかれば、別の文献に飛んで、同じ言葉で検索し直す。
DCIは、この行動パターンをLLMにやらせている、と言えます。「広く拾って全部読む」のは、人間にはコストが高すぎて続かない。だから人間は「ピンポイントで探して、必要なところだけ深く読む」戦略を取ります。DCIは、それと同じ戦略がLLMにも有効だということを示したわけです。
ここまでDCIの良いところばかり語ってきました。でも、論文はDCIの弱点も正直に書いています。次のセクションでは、その弱点と、これからのトレンドやビジネスへの影響について見ていきましょう。
弱点と、これからのトレンド・ビジネス展望
最後のセクションです。DCIは魅力的な手法ですが、何でも解決する魔法の杖ではありません。論文が正直に書いている限界を見たうえで、これからの見通しを考えていきましょう。
弱点1:大規模コーパスで性能が落ちる
論文がはっきり認めている弱点があります。コーパスの規模が20万文書を超えると、性能が13.6ポイント低下するんです。
なぜでしょうか。考えてみると当たり前で、文書が大量にあると、最初の「当たり文書」を見つけるコストが急増します。grepで全ファイルを舐めるのにも時間がかかるし、見つかった候補が多すぎると、エージェントが「次にどれを読むか」を決められなくなる。
ここは依然として、埋め込みベースのベクトル検索の方が強い領域です。20万件の文書から「とりあえず関係ありそうな100件」を高速に絞り込むタスクは、ベクトル検索の十八番ですから。
つまりDCIは、「数百〜数万ファイル規模のローカルコーパス」では強いけれど、「Web全体のような巨大で静的な集合」ではまだ厳しい。これは正直に押さえておくべきポイントです。
弱点2:コンテキスト管理が難しい
もう一つの弱点として、論文は「コンテキスト管理が非単調」だと書いています。
これは何かというと、エージェントの作業履歴をどう保持するかの問題です。grepの結果を全部覚えていたら、すぐにLLMのコンテキストウィンドウが溢れてしまう。かといって、過去の結果をどんどん捨てると、何を調べたか忘れて同じ検索を繰り返してしまう。
論文の実験では、「適度に忘れながら探索を続ける」設定が一番性能が良かったそうです。つまり、何を覚えて何を忘れるかの匙加減が難しい。これは今後の研究で大きな課題として残っていきます。
弱点3:人間と同じ「迷子」になりやすい
これは私の解釈ですが、DCIは要するに「人間と同じ手つきで探す」ので、人間と同じように「迷子になる」リスクもあります。
ベクトル検索なら、関係ない文書を返すことはあっても「探索が無限ループに入る」ことはありません。一方DCIは、「ここを掘っても出てこないから別の方向に行こう」と方針転換する判断を、エージェント自身がやる必要があります。判断を間違えれば、永遠に正解に辿り着けません。
このあたりは、エージェントの推論能力が上がれば自然に解決していく問題かもしれませんが、現時点では運用上の難しさとして残っています。
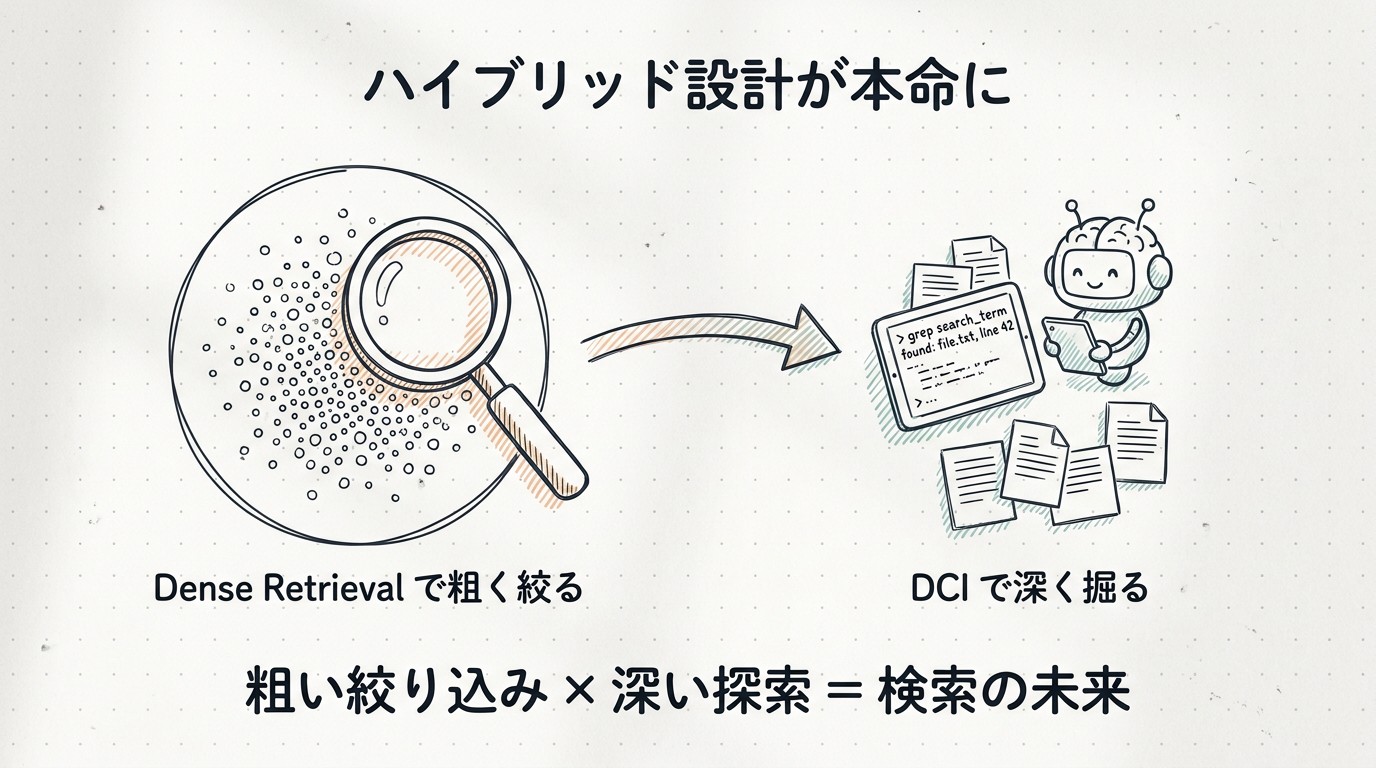
これからのトレンド:ハイブリッド設計が本命に
ここから先は私見も交じります。論文の事実と限界を踏まえて、これからの展開を考えてみます。
一番ありそうな未来は、「ハイブリッド設計」が主流になることです。
具体的には、こういう二段構えになると思っています。まず、dense retrievalやhybrid検索で、巨大なコーパスから数百件まで粗く絞ります。次に、絞り込んだ候補に対して、DCI的なraw interactionで深く掘っていく。
「最初の絞り込みはベクトル検索の方が速い、でもその先の精密な掘り下げはDCIの方が上手い」という棲み分けです。これは論文が示した結果と、ベクトル検索の強みの両方を素直に受け入れた設計になります。
私が知る範囲では、すでに一部の検索プロダクトはこの方向に動き始めているように見えます。たとえば、ベクトル検索で候補を集めてから、agentが個別文書を「読み込み直す」アーキテクチャは増えてきました。DCI論文は、その流れに理論的な裏付けを与えた格好です。
ファイルシステムが「AIの作業環境」として再評価される
もう一つ、見えてきた大きな流れがあります。「ファイルシステムをAIが触る場所として設計する」という発想です。
これまで、ファイルシステムは単なる「データの置き場」でした。フォルダがあって、その中にファイルが入っているだけ。アクセスは人間がすることを前提に設計されてきました。
DCIが示しているのは、ファイルシステムが「AIエージェントの作業環境」になりうる、ということです。フォルダ構造、ファイル命名規則、メタデータの持たせ方が、AIの性能を左右する設計要素になってきます。
これは「AI-readableなファイル設計」とでも呼べる、新しいデザインの領域です。社内ナレッジを整理するとき、議事録のファイル名にいつ・誰が・何の会議かを含めるだけで、grepで一発で引けるようになる。そういう「AIが探しやすい構造」を意識した情報設計が、これから重要になっていきそうです。
ビジネスへの影響:相性が良さそうな領域
DCIの強みが活きそうなビジネス領域を、いくつか挙げてみます。
- 企業内文書検索(契約書、議事録、社内Wikiなど、変化するローカルコーパスとの相性が良い)
- 法務・コンプライアンス(厳密な文言一致が重要な場面で、grepの正確さが効く)
- リサーチ業務(仮説検証型で証拠を辿る必要がある、調査会社やシンクタンクの業務)
- カスタマーサポート(問い合わせ履歴やナレッジベースを横断的に探索する用途)
- 開発業務(コードベース調査は、DCI型エージェントがすでに主流になりつつある)
特に中小企業にとっては、ベクトルDBの運用コストや埋め込みの再計算コストがゼロになるのは大きいです。「手元のSharePointやGoogle Driveのフォルダをそのまま検索対象にできる」シンプルさは、導入のハードルを大きく下げます。
一方で、Web全体検索のような超大規模で静的な領域では、引き続きGoogleやBingのような既存検索エンジンが主役のままでしょう。DCIは万能ではなく、得意領域があるツールだと理解しておくのが正解です。
まとめ:検索は「アルゴリズム」から「環境設計」へ
DCI論文の本当の貢献は、「どのretrieverが強いか」というレースから、「エージェントが知識にどう触るべきか」というインターフェース設計論へ、議論の土俵を広げたことにあります。
検索研究はこれまで、いい埋め込みモデルを作る、いいrerankerを作る、いいchunking戦略を作る、と「アルゴリズム」の改善で進んできました。DCIはそこに「環境設計」という新しい軸を持ち込んでいます。
LLMに何ができるかは、モデルの賢さだけじゃない。LLMが触れる環境の解像度にも依存する。
この発想は、検索だけでなく、エージェント設計全般に効いてくると思っています。「ツールをいくつ持たせるか」「どんな粒度で操作させるか」「どの抽象度の環境を与えるか」。これらの設計選択が、これからのAI製品の競争力を左右する要素になっていくはずです。
grepとbashという、1970年代から存在する地味なコマンドが、2026年のAI研究で再評価される。技術の世界では、こういう「枯れた道具の再発見」が時々起こります。DCIはその最新の事例として、これからしばらく検索研究の重要な参照点になっていくでしょう。
これから自社で検索やナレッジ管理の設計をする方は、「retrieverを賢くする」という一方向だけでなく、「エージェントがファイルに触れる環境をどう作るか」という視点も、ぜひ持っておいてみてください。きっとDCIのアイデアが、設計の選択肢を広げてくれるはずです。
調査手法について
こちらの記事はグラフAIリサーチプラットフォームのSnorbeを使って作られています。Snorbeは研究開発・新規事業向けの調査テーマに応じた幅広い項目のオートリサーチや、ナレッジグラフの構築、構造化レポートの生成ができるAIリサーチツールです。
Screenshot
調査したいテーマを入力するだけで、AIが深堀りすべき観点や広げるべき調査項目をレコメンドしながら、自動でリサーチを進めます。収集した情報はナレッジグラフとして蓄積され、未調査領域(ホワイトスペース)を可視化しながら調査の網羅性を高めていけます。
また、観点マトリクスを30秒・構造化レポートを10分で自動生成する機能があり、出典付きのレポートをMarkdown/PDF形式でエクスポートできます。調査の元データも保存されるため、ファクトチェックや社内共有も容易です。
ご利用をご希望の方は、こちらよりお申し込みください。
また、グラフAIを活用した社内ナレッジ管理や、研究開発・新規事業のリサーチ支援、セルフホスト導入のご相談も受け付けています。お困りの方はお気軽にご連絡ください。
市場調査やデスクリサーチの生成AIエージェントを作っています 仲間探し中 / Founder of AI Desk Research Agent @deskrex , https://deskrex.ai


コメント