
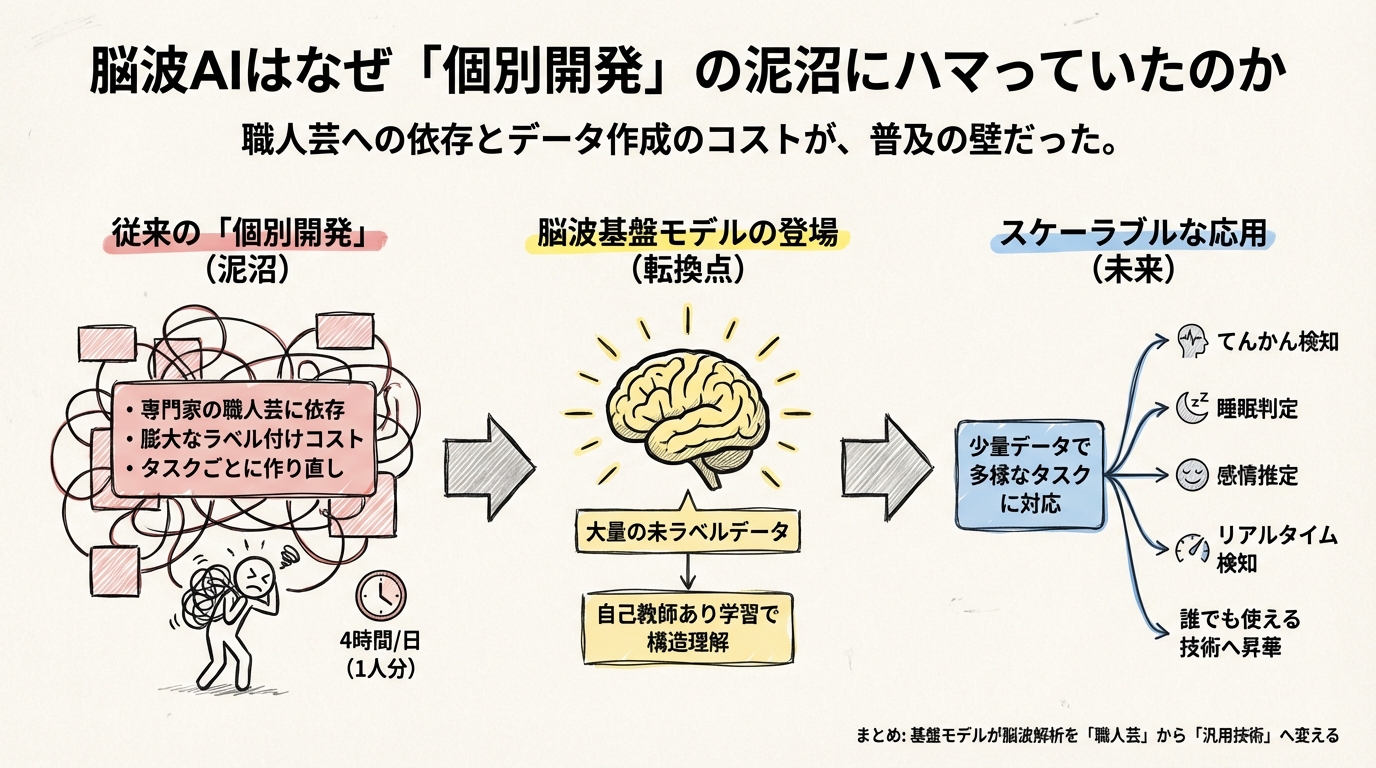
脳波AIはなぜ「個別開発」の泥沼にハマっていたのか
脳波(EEG)という技術には、不思議な魅力があります。頭にセンサーを乗せるだけで、私たちの脳内で起きている電気的な活動を読み取れるのですから、まるでSFの世界です。しかし、これほど可能性に満ちた技術であるにもかかわらず、なぜこれまで医療現場や日常生活で爆発的に普及してこなかったのでしょうか。
どうやら、その原因は技術的な精度というよりも、脳波解析が抱える「職人芸」への過度な依存にあったような気がします。
本記事では、脳波AIにおける最新トレンドである「脳波基盤モデル(EEG Foundation Models)」について、全5セクションにわたって解説していきます。第1セクションは、なぜ今、脳波解析の世界で「基盤モデル」という新しいパラダイムが必要とされているのか、その切実な背景から紐解いていきましょう。
「1日分のデータを見るのに4時間」という絶望的なボトルネック
まず、脳波解析の現場で何が起きているのか、具体的な数字を見てみましょう。
集中治療室(ICU)では、患者の脳の状態を監視するために脳波計が使われます。しかし、現在の医療現場では、すべての患者をリアルタイムで監視し続けることは事実上不可能です。なぜなら、脳波の波形を目で見て異常を見つけるには、高度な専門知識を持った医師が必要だからです。
驚くべきことに、人間が1日分の脳波データを確認するには、約2〜4時間もの時間と専門知識が必要だと言われています。これでは、医師1人が担当できる患者数は限られてしまいますし、どうしても12時間や24時間ごとの「事後レポート」にならざるを得ません。発作や異常が起きているその瞬間に気づくことが難しくなるのです。
この現状を変えようとしているのが、クリーブランド・クリニックと提携したスタートアップのPiramidalです。彼らは、この「人間によるレビューの限界」こそが最大の課題であると見抜き、AIによるリアルタイム検知システムの開発を進めています。彼らの取り組みが示唆しているのは、脳波解析に求められているのは単なる「分析ツール」ではなく、医師の時間を拘束する「労働集約的なワークフロー」からの解放だということです。
「タスクごとに作り直し」が招いた開発の泥沼
では、なぜこれまでAIがその役割を果たせなかったのでしょうか。AI、特にディープラーニングを使えば、波形の異常検知くらい簡単にできそうなものです。
実は、ここ数年の脳波AI研究は「個別開発」の泥沼にハマっていました。
これまでのアプローチは、「特定のタスク」のために「特定のデータ」を使って「専用のモデル」を作るというものでした。例えば、「てんかん発作を見つけるAI」を作ろうと思ったら、専門家が膨大な時間をかけて「ここが発作の波形です」とラベル(正解)を付けたデータセットを用意し、それを学習させます。
しかし、このやり方には致命的な欠点があります。
- アノテーション(正解付け)のコストが高すぎる:
脳波を正しく読める専門家は非常に少なく、彼らの時間は高価です。AIを学習させるための教師データを作るだけで、莫大なコストと時間がかかってしまいます。
- 応用が利かない:
「てんかん検知AI」を「睡眠段階の判定」に使おうとしても、全く使い物になりません。それどころか、計測する病院や脳波計の機種が変わっただけで、精度がガタ落ちすることも珍しくありません。
その結果、研究者たちは新しいタスクに取り組むたびに、またゼロからデータ集めとモデル構築をやり直すという賽の河原のような作業を強いられていました。これでは、技術が社会に広がるスピードが上がらないのも無理はありません。
「職人芸」から「スケーラブルな技術」へ
この行き詰まりを打破するために登場したのが、「脳波基盤モデル(EEG Foundation Models)」です。
これは、ChatGPTのような大規模言語モデル(LLM)で起きた革命を、脳波の世界にも持ち込もうという試みです。具体的には、ラベル(正解)が付いていない大量の脳波データをAIに読み込ませ、「自己教師あり学習」という手法で脳波の一般的なパターンを学習させます。
こうして作られた「基盤モデル」は、脳波の構造そのものを理解しているため、少量のラベル付きデータを追加学習させるだけで、てんかん検知にも、睡眠判定にも、あるいは感情推定にも応用できるようになります。最近の研究では、LaBraMやBrainWaveといったモデルが、このアプローチで高い性能を示し始めています。
つまり、脳波基盤モデルが登場した本当の理由は、単に「AIの精度を上げたい」からではありません。脳波解析を、専門家しか扱えない「職人芸」から、誰でもどこでも使える「スケーラブル(拡張可能)な技術」へと昇華させたいという、現場の切実なニーズがあったからなのです。
さて、これで脳波AIが抱えていた課題と、基盤モデルへの期待についてはイメージできたかと思います。しかし、ここで一つ疑問が浮かびます。「言葉」や「画像」の基盤モデルが成功したからといって、そのまま「脳波」に当てはめてもうまくいくのでしょうか?
どうやら、脳波データにはテキストや画像とは決定的に異なる、厄介な「方言」のような性質があるようです。次章では、研究者たちがどのようにしてこの「計測の方言」と戦い、脳の言葉を理解しようとしているのか、その技術的な裏側に迫ります。
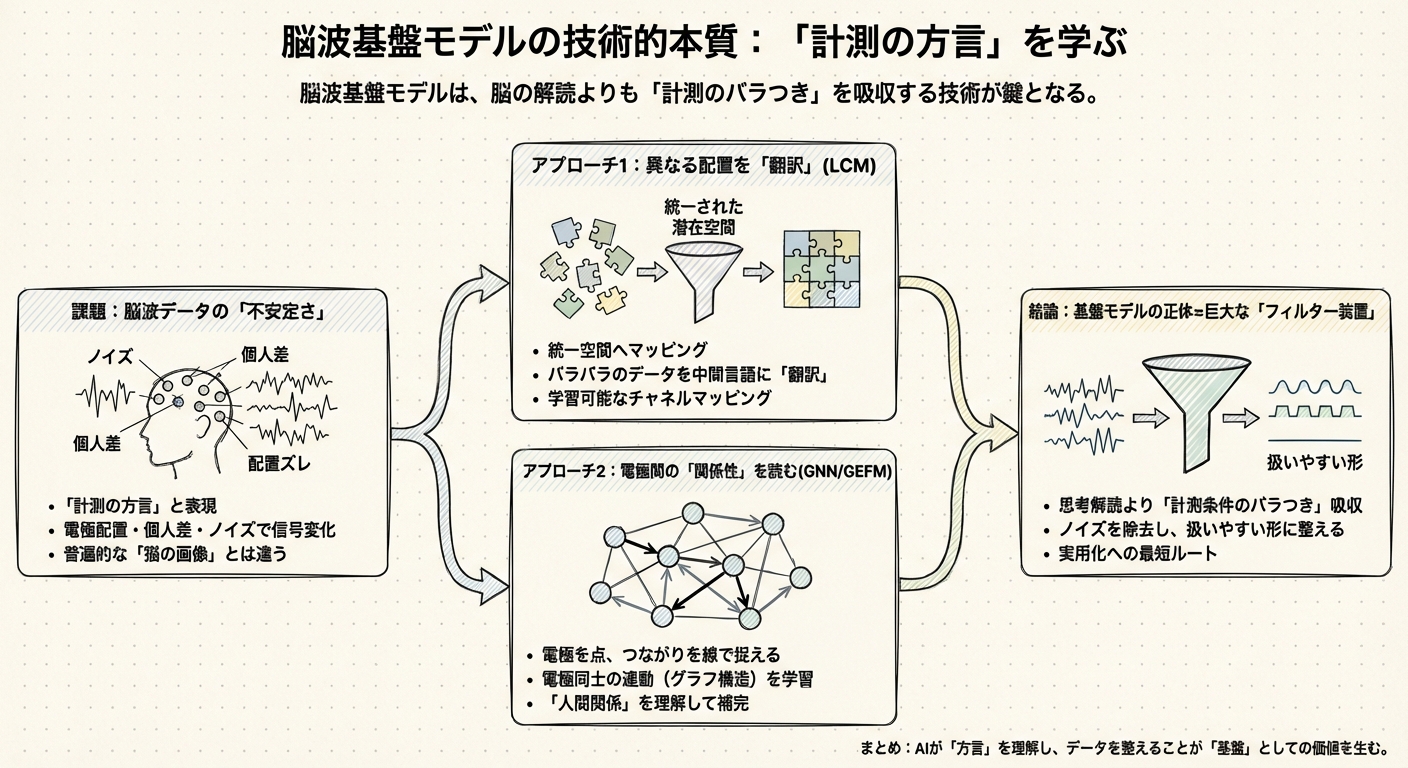
「脳の言葉」以前に「計測の方言」を学ぶ:基盤モデルの技術的本質
前章では、脳波AIがこれまで「タスクごとの個別開発」という泥沼にはまっていた背景をお話ししました。そこで登場したのが「脳波基盤モデル(EEG Foundation Models)」という希望の光です。
しかし、ここで冷静になって考えてみたいことがあります。ChatGPTのような大規模言語モデル(LLM)が成功したからといって、脳波でも同じように「データを大量に読ませれば賢くなる」ものなのでしょうか?
どうやら、話はそう単純ではないようです。私が様々な論文や研究事例を調べていくうちに気づいたのは、脳波データがテキストや画像とは決定的に異なる、極めて厄介な「不安定さ」を抱えているという事実でした。
脳波データは「猫の画像」とは違う
画像認識AIを想像してみてください。インターネット上の「猫の画像」は、誰がどのカメラで撮ろうと、そこに写っているのは「猫」という普遍的な対象です。多少画質が悪くても、猫の形は猫のままです。
ところが、脳波(EEG)はそうはいきません。
脳波は「脳活動そのもの」というより、「頭皮上の電極で計測された電気信号」に過ぎません。ここが非常に重要なポイントです。この信号は、計測する環境によってまるで別物のように変化してしまうのです。
- 電極の配置が違う: 病院Aでは19個の電極を使い、研究所Bでは64個使うかもしれません。配置場所が数センチずれるだけで、波形は変わります。
- 個人差が大きい: 頭の形、皮膚の厚さ、髪の毛の量によって、電気の伝わり方は人それぞれです。
- ノイズだらけ: 瞬きや歯ぎしり、あるいは近くのコンセントからの電気ノイズさえも拾ってしまいます。
言ってみれば、脳波データは標準語で書かれたテキストではなく、地域や話者によって文法さえ変わってしまう「方言」のようなものではないでしょうか。
これまでのAI研究がうまくいかなかったのは、この「計測の方言」を無視して、いきなり「脳の意味」を理解しようとしていたからかもしれません。最新の基盤モデル研究を見ていると、どうやら彼らはアプローチを変え、まずこの「方言(計測条件のバラつき)」を吸収することに全力を注ぎ始めたようです。
異なる電極配置を「翻訳」する技術
では、研究者たちは具体的にどうやってこのバラつきを乗り越えようとしているのでしょうか。ここで、非常に興味深いアプローチを2つ紹介します。
一つ目は、「Learnable Channel Mapping(学習可能なチャネルマッピング)」という技術です。
これは、Large Cognition Model (LCM)という基盤モデルで採用されている手法なのですが、発想が秀逸です。通常、電極の配置(モンタージュと言います)が違うデータ同士は、そのままでは混ぜて学習させることができません。入力の形が違うからです。
そこでLCMは、バラバラの電極配置から得られたデータを、一度「統一された潜在空間」へとマッピング(変換)する仕組みを導入しました。
例えるなら、津軽弁や鹿児島弁で話された言葉を、AIがいったん「意味の通じる中間言語」に翻訳してから理解するようなものです。LCMはこの「翻訳機」の部分も含めて学習することで、異なるデータセットを横断して特徴を抽出できるようになりました。その結果、運動想起(MI)などのタスクにおいて、既存のモデルを上回る性能を叩き出しています。
電極同士の「人間関係」を読む
もう一つのアプローチは、「グラフニューラルネットワーク(GNN)」の活用です。
これは東京大学の鈴村研究室などが取り組んでいるGEFM (Graph-Enhanced EEG Foundation Model)という研究で見られる手法です。
従来の脳波AI(Transformerベースのもの)は、主に「時間の流れ(時系列)」に注目して学習していました。「さっき波が上がったから、次は下がるだろう」という予測です。しかし、脳波には「空間的なつながり」も重要です。「前頭葉の電極が反応したら、次は後頭葉が反応する」といった関係性です。
GEFMのアプローチは、電極を「点(ノード)」、電極間のつながりを「線(エッジ)」として捉え、電極同士の関係性(グラフ構造)を学習します。
これは、「電極同士の人間関係」を学んでいると言えるかもしれません。「この電極さんは、あの電極さんと仲が良い(連動しやすい)」という関係性を知っていれば、仮に一部の電極がノイズで使えなくなっても、周りの反応から「たぶんこう動いているはずだ」と推測できます。実際、GNNを組み込むことで、従来のモデル(BENDR)よりも分類性能が向上したと報告されています。
「基盤モデル」の正体は、巨大な「ノイズ除去装置」かもしれない
こうして最新技術を紐解いていくと、ある一つの仮説が浮かび上がってきます。
私たちが「脳波基盤モデル」と呼んでいるものは、実は「脳の思考を解読する知能」というよりも、「計測条件の無限のバラつきを吸収し、扱いやすい形に整える巨大なフィルター装置」なのではないでしょうか。
レビュー論文でも指摘されている通り、脳波モデルを単に巨大化(スケーリング)させるだけでは、必ずしも性能向上につながらないという課題があります。これは、データの質や計測条件の不一致(方言)がボトルネックになっているからだと考えられます。
だからこそ、LCMやGEFMのような「計測の方言」を吸収する技術こそが、実用化への最短ルートになる気がしてなりません。
脳波AIが「方言」を理解し、どんな病院のどんな装置で測ったデータでも文句を言わずに処理できるようになったとき、初めて「基盤」としての価値が生まれます。例えば、MIRepNetというモデルは、少ないデータでも新しいタスクに素早く適応できることを示しましたが、これこそ現場が求めている能力です。
さて、技術的な「基盤」の正体が見えてきたところで、次はもっと具体的な話に移りましょう。これらの技術は、研究室を出て実際の現場でどう使われているのでしょうか?
次章では、ICUでの異常検知や、ALS患者が思考で家電を操作するBCIなど、「精度」競争の先にある「ワークフローの変革」に挑む実例を見ていきます。そこには、私たちが想像する「AI活用」とは少し違う、リアリスティックな景色が広がっていました。
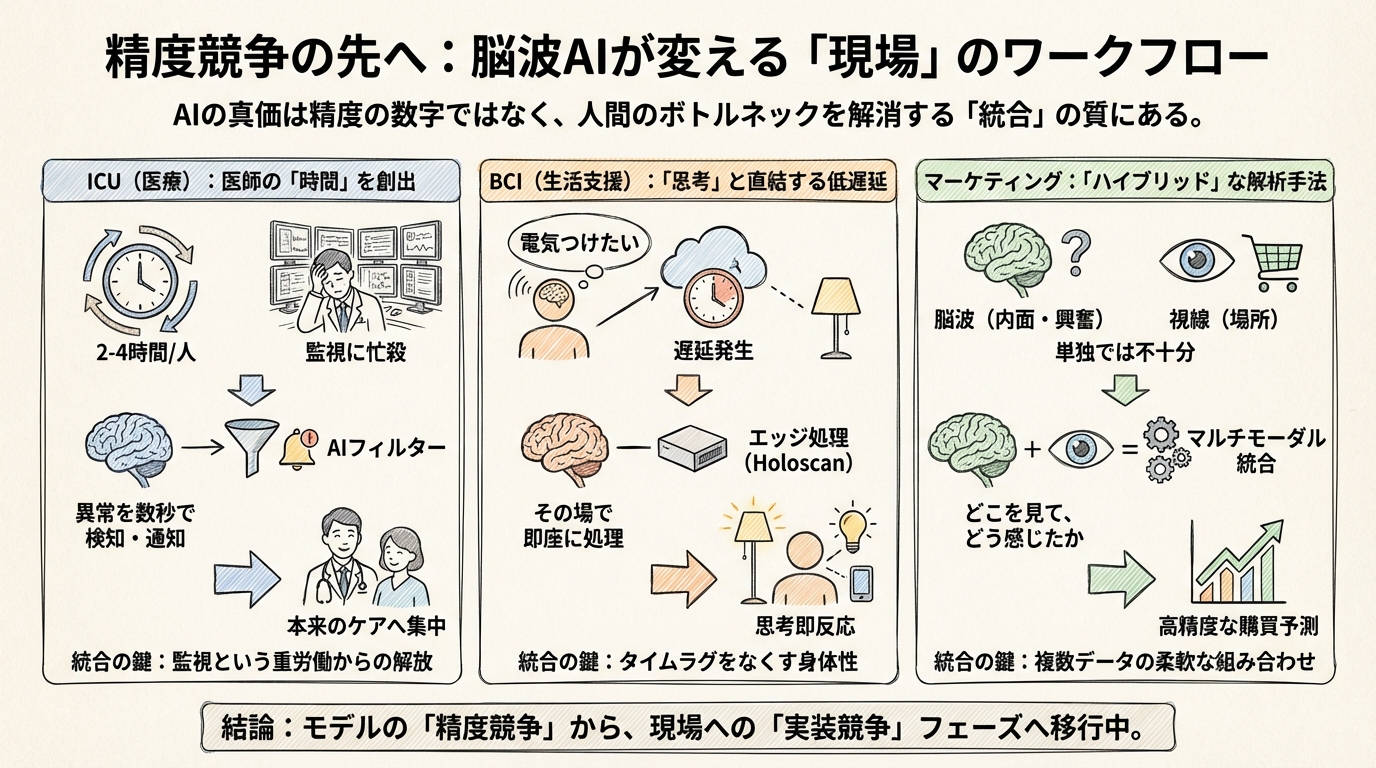
精度競争の先へ:ICU、BCI、マーケティングを変える「ワークフロー統合」の実例
前章で見たように、最新の脳波基盤モデルは、脳波データの厄介な「方言(計測条件のばらつき)」を翻訳する技術として進化してきました。では、この翻訳機が実用レベルになった先に、一体どんな景色が待っているのでしょうか。
多くの人は、SF映画のようにAIが心を読み取り、魔法のように世界を操る未来を想像するかもしれません。しかし、実際に最前線の事例を調べてみると、そこで起きていたのはもっと泥臭く、しかし強烈な「既存ワークフローの破壊と再構築」でした。
どうやら、現場で問われているのは「モデルの正解率が何%上がったか」という研究室レベルの数字ではないようです。それよりも、AIが人間の時間や生活にどう溶け込み、ボトルネックを解消できるかという「統合」の質こそが、勝負の分かれ目になっている気がします。
ここでは、医療、生活支援、そしてマーケティングという異なる3つの現場で、AIがどのように現実を変えつつあるのかを見ていきましょう。
医師の「時間」を取り戻すフィルター装置
まず注目したいのが、救急医療の現場です。集中治療室(ICU)では、発作の兆候を見逃さないために脳波モニタリングが不可欠ですが、ここには致命的な問題がありました。
それは、人間がデータを見るのに時間がかかりすぎることです。
クリーブランド・クリニックの医師によると、患者1人分の24時間の脳波データを確認し、レポートを作成するのに、なんと2〜4時間もかかるそうです。これでは、医師は患者の治療よりもモニターの監視に忙殺されてしまいます。
ここで登場するのが、Piramidal社が開発している脳波基盤モデルです。このAIは、数万人の患者から得た膨大なデータで訓練されており、ICUの脳波を常時監視して、異常があれば数秒以内に検知して通知してくれます。
私がこの事例で面白いと感じたのは、彼らが目指しているのが「医師を超える診断」ではない点です。むしろ、膨大な正常データの中から異常だけを即座に拾い上げる「高度なフィルター」としてAIを使おうとしています。
このシステムが現場に統合されれば、医師はモニターに張り付く必要がなくなり、本来の業務である「患者のケア」に時間を使えるようになります。つまり、ここでのAIの価値は精度の高さそのものよりも、医師のワークフローから「監視」という重労働を引き剥がした点にあるのではないでしょうか。
もちろん、誤報(偽陽性)が多すぎれば医師はAIを無視するようになります。だからこそ彼らは、いきなり全展開するのではなく、段階的に導入範囲を広げながら精度を調整する計画を立てています。技術の実装とは、こうした地道な運用設計そのものなのかもしれません。
「思考」と「家電」を直結する低遅延の魔法
次に、生活の質(QoL)を劇的に変えるブレイン・コンピュータ・インターフェース(BCI)の事例を見てみましょう。
Synchron社とNVIDIAが開発しているChiral™というシステムは、ALS(筋萎縮性側索硬化症)などの患者さんが、思考だけでデジタル機器を操作できるようにする技術です。
実際に公開されたデモでは、Rodney氏という患者さんが、手を使わずにApple Vision Proを介して、自宅の照明や音楽、空調をコントロールしている様子が映し出されていました。
この事例が示唆的なのは、単に「脳波が読める」だけでは不十分だということです。考えてみてください。「電気をつけたい」と思ってから実際に電気がつくまでに数秒もかかったら、それは使い物になりません。
そこで彼らが重視したのは、NVIDIA Holoscanというプラットフォームを使った「極低遅延のエッジ処理」です。脳波データをクラウドに送って解析するのではなく、その場(エッジ)で即座に処理することで、思考と結果のタイムラグを極限までなくす。これにより、自分の体の一部のように家電を操る感覚が生まれます。
さらに、このシステムは将来的には、物理シミュレーション技術(Omniverse)と連携し、ユーザーがいる「環境(文脈)」まで理解することを目指しています。
つまり、成功するBCIとは、脳波解析の精度だけでなく、「低遅延な反応」と「環境への理解」がセットになって初めて成立するもののようです。ここでもやはり、AI単体ではなく、システム全体としての統合力が問われています。
脳波だけで戦わない「ハイブリッド」な戦略
最後に、ビジネスの世界、特にニューロマーケティングの分野での興味深いアプローチを紹介します。
消費者が商品を見て「買いたい」と思う瞬間を捉える研究において、最近のトレンドはどうやら「脳波一本足打法」からの脱却にあるようです。
ある研究では、スーパーマーケットのデジタルパンフレットを見ている消費者の購買意図を分類するために、脳波だけでなく、視線計測(アイトラッキング)を組み合わせたハイブリッドな解析手法を採用しています。
脳波は「内面の反応(興奮や関心)」を捉えるのは得意ですが、「具体的に何を見ているか」を知るのは苦手です。一方で、アイトラッキングは「見ている場所」はわかりますが、「どう感じているか」まではわかりません。
この2つを組み合わせることで、「どの商品を(視線)、どう感じて(脳波)、買おうとしたか」を高精度に予測できるようになります。実際、このハイブリッド手法は、それぞれ単独で解析するよりも高い分類性能(F1スコア)を記録しました。
これは私たちに、「脳波AIは万能でなくてもいい」という重要な事実を教えてくれます。足りない情報は、視線や音声など他のデータで補えばいい。実務的な「勝ち筋」は、脳波モデルの精度をカリカリにチューニングすることよりも、こうして複数のデータを組み合わせる柔軟な設計にある気がしてきます。
精度よりも「どう使うか」が問われるフェーズへ
ICUでの医師の負荷軽減、BCIによる身体性の拡張、そしてマーケティングでのマルチモーダル解析。
これら実例を見てきて共通するのは、「脳波基盤モデル」はあくまで部品の一つに過ぎないという点です。それが現場のワークフローや、他の技術(エッジ処理や視線計測)と巧みに統合されたとき初めて、人間にとって意味のある価値が生まれています。
どうやら私たちは、モデルのスペックを競う「精度競争」の時代を終え、それをどう現実に組み込むかという「実装競争」のフェーズに入ったようです。
しかし、こうしてAIが私たちの身体データや生活空間に深く入り込んでくると、新たな不安も頭をもたげます。思考や生体データという「究極のプライバシー」は、本当に守られるのでしょうか?
次章では、技術的な実装と同じくらい、あるいはそれ以上にビジネスの成否を握ることになる「倫理と規制(ニューロライツ)」という、避けては通れないテーマについて考えていきます。これは単なる守りのルールではなく、これからの時代の生存戦略そのものと言えるかもしれません。
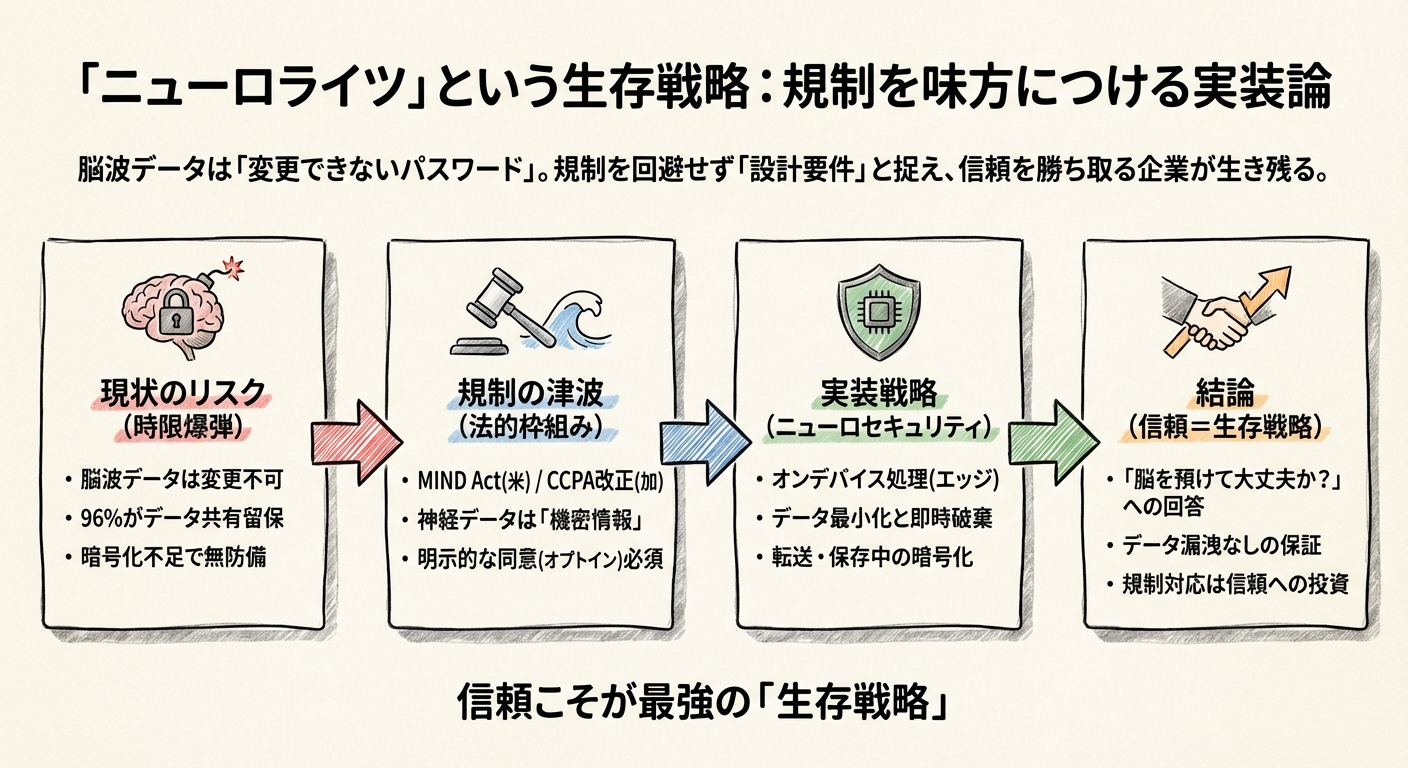
「ニューロライツ」という生存戦略:規制を味方につける実装論
前章では、脳波AIが現場のワークフローにいかに統合されるかを見てきました。しかし、私たちの脳波がインターネットや企業のサーバーにつながるようになったとき、どうしても無視できない不都合な事実があります。
それは、脳波データは「変更できないパスワード」のようなものだということです。
もしクレジットカード番号が漏洩したら、番号を変えれば済みます。しかし、私たちの脳活動パターン、そこから読み取れる感情や疾患のリスク、あるいは思考の癖といったデータが一度流出してしまったら、私たちは「脳を取り替える」わけにはいきません。
この不可逆的なリスクに対して、世界はいま「ニューロライツ(神経権)」という新しい人権概念を盾に、急速に規制の壁を築き始めています。どうやら、これからの脳波ビジネスにおいて、「倫理」は単なる努力目標ではなく、企業の生存を左右する最大の変数になりそうなのです。
96%の企業が抱える「時限爆弾」
現状、市場に出回っている消費者向け脳波デバイス(ヘッドセットなど)の多くは、驚くほど無防備な状態で運営されています。
ニューロライツ財団(Neurorights Foundation)が実施した30社の消費者向けニューロテック企業の監査によると、実に96.7%の企業がユーザーの神経データを第三者と共有する権利を留保していました。さらに驚くべきことに、データの暗号化について明記していた企業は全体の20%未満しかありませんでした。
多くのユーザーは「利用規約」を読まずに同意ボタンを押してしまいますが、実はその瞬間、自分の脳内データが広告業者やデータブローカーに売られる許可を出しているかもしれないのです。
これは、いつ爆発してもおかしくない「時限爆弾」のような状態です。ひとたび大規模な漏洩や悪用が起きれば、その企業だけでなく、業界全体の信頼が一瞬で崩壊しかねません。
世界中で始まる「規制の津波」
こうした現状に待ったをかけるべく、各国で強力な法的枠組みが動き出しています。
米国では2025年、上院議員らがMIND Act(個人神経データ管理法)という法案を提出しました。これは、これまで規制の及ばなかった消費者向けデバイスの神経データに対し、連邦取引委員会(FTC)による保護と監視を求めるものです。
さらにビジネスへの影響が直撃しそうなのが、カリフォルニア州の動きです。同州のCCPA(カリフォルニア州消費者プライバシー法)の2026年改正において、神経データは明確に「機密性の高い個人情報(Sensitive Personal Information)」として分類されることになりました。
これが何を意味するかというと、企業はデータを集める前に、ユーザーから「オプトイン(明示的な同意)」を得なければならなくなるのです。「デフォルトでON」にしておいて、嫌なら設定でOFFにしてね、という手法(オプトアウト方式)は通用しなくなります。
また、南米のチリでは世界に先駆けて、憲法を改正して「精神の完全性」を保護する権利を盛り込みました。実際に、元上院議員の脳データを違法に保持していた企業に対し、最高裁がデータの削除を命じるという画期的な判決も出ています。
これらはもはや「対岸の火事」ではありません。国連やUNESCOも、神経データを「特権的な機密情報」として扱う国際的な倫理枠組みの構築を急いでいます。
「ニューロセキュリティ」という実装競争
では、これから脳波AIを開発・導入しようとする私たちは、どうすればよいのでしょうか?
答えはシンプルです。規制を「回避すべき障害」ではなく、「プロダクトの設計要件」として最初から組み込んでしまうことです。これを専門用語で「プライバシー・バイ・デザイン」と呼びますが、脳波の文脈では「ニューロセキュリティ」と呼ぶべきかもしれません。
具体的には、以下のような技術的実装が、精度の高さ以上に重要な差別化要因になってくると考えられます。
- オンデバイス処理(エッジコンピューティング):
前章で紹介したSynchron社のChiralのように、データをクラウドに送らず、デバイス内(エッジ)で処理して完結させること。これにより、生データ流出のリスクを物理的に遮断できます。遅延を減らすための技術が、結果的にプライバシー保護の切り札にもなるわけです。
- データ最小化と「捨てる」勇気:
「とりあえずデータを全部取っておこう」という発想は、リスクでしかありません。必要な特徴量だけを抽出し、元の生データは即座に破棄する設計が求められます。
- 暗号化とアクセス制御:
TrustArcのガイドラインでも指摘されている通り、転送中・保存中の暗号化は必須です。しかし現状、これすらできていない企業が多いのが実情です。
信頼こそが最強の「生存戦略」
脳波基盤モデルは、私たちの内面を可視化する強力なツールです。だからこそ、ユーザーは本能的に警戒します。「この会社に自分の脳を預けて大丈夫か?」という問いに対し、技術と法務の両面で誠実に答えられる企業だけが、生き残ることができます。
逆に言えば、「私たちのデバイスは、あなたの思考データを外部に漏らしません」と胸を張って言えることは、どんなに高精度なAIモデルを持つことよりも、強力なマーケティングメッセージになり得ます。
規制への対応をコストと捉えるか、それとも信頼を勝ち取るための投資と捉えるか。脳波ビジネスの勝者は、間違いなく後者の視点を持っているはずです。
さて、ここまで技術、実装、そして倫理と規制について見てきました。しかし、いざ「自分の現場で導入しよう」と思ったとき、具体的に何から始めればいいのでしょうか? 最終章では、初学者がモデル選びの前にまず考えるべき、現場視点の指標(KPI)について解説し、この連載を締めくくりたいと思います。
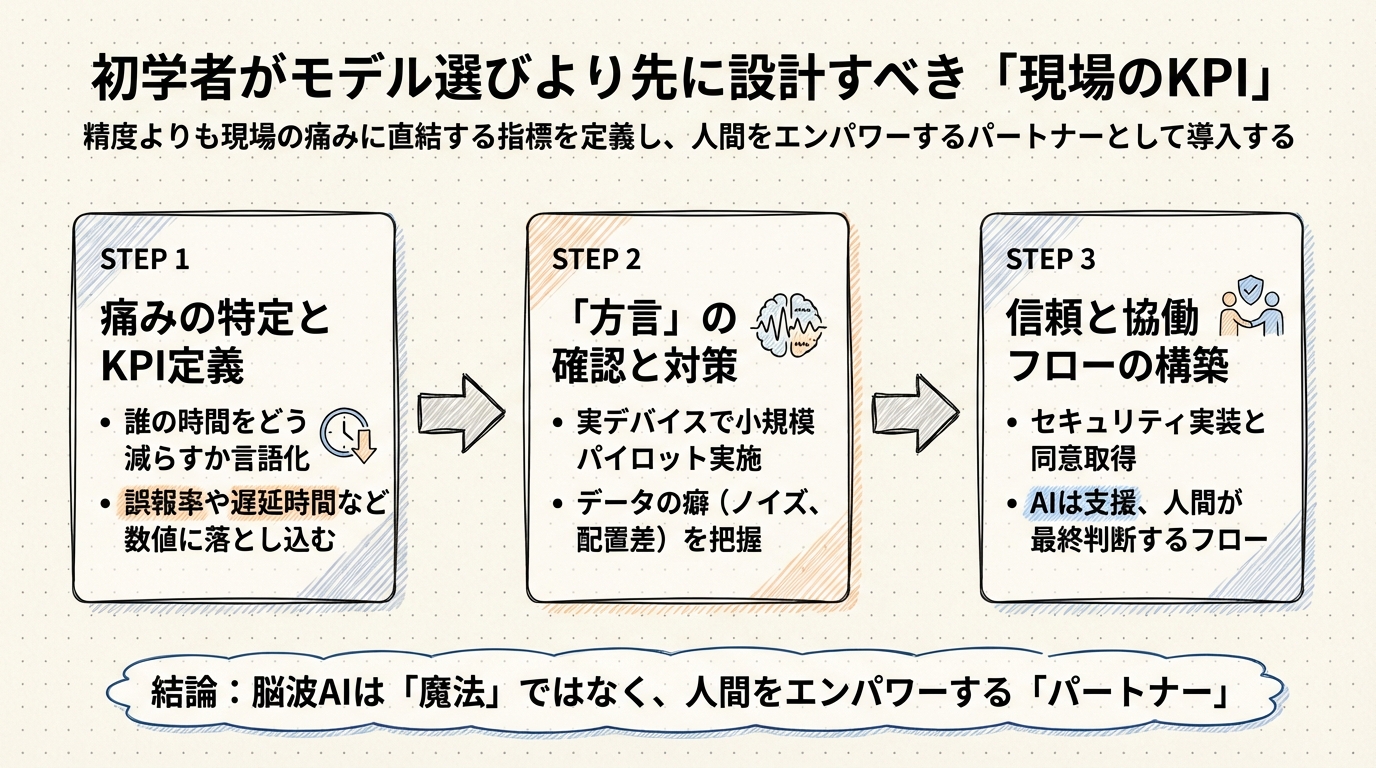
初学者が「モデル選び」より先に設計すべき現場のKPI

ここまで、脳波基盤モデル(EEG-FMs)の技術的背景から実用例、そして避けて通れない規制の壁までを旅してきました。もしあなたが「よし、うちでも脳波AIを導入してみよう」と考えたとき、最初に何をするでしょうか?
多くの方は、まず最新のモデルを検索し始めるかもしれません。「LaBraMのパラメータ数はこれくらいか」「NeuroLMの精度が高いらしい」といったスペック比較です。しかし、どうやらそれは、家を建てる前にカーテンの柄を選んでいるようなものかもしれません。
モデルの性能(Accuracy)は重要ですが、実務においては「90%の正解率」よりもはるかに深刻な問題が存在します。最終章では、モデル選びの迷路に入り込む前に、まず真っ先に定義すべき「現場のKPI(重要業績評価指標)」について考えてみたいと思います。
「99%の精度」でも現場で使われない理由
AI開発において、私たちはつい「正解率(Accuracy)」を追い求めがちです。しかし、脳波AIが活躍する現場において、正解率は必ずしも最優先事項ではありません。
例えば、医療現場を想像してみてください。クリーブランド・クリニックとPiramidalが進めているICUでの脳波監視の事例が、非常に良いヒントを与えてくれます。
彼らが挑んでいるのは、医師が1日分の脳波データを確認するのに「2〜4時間」もかかっているという、圧倒的な時間不足の解消です。ここでAIに求められる最も重要なKPIは、実は「発作を100%見つけること」以上に、「誤報(偽陽性)を出さないこと」にあるのではないでしょうか。
もしAIが高性能であっても、1時間に何度も「発作かも!」と誤ったアラートを鳴らせば、忙殺されている医師たちはすぐに通知を切ってしまうでしょう。いわゆる「オオカミ少年」状態です。この現場における真の損失関数(失敗のコスト)は、「医師の業務を妨害すること」なのです。
したがって、最初に設計すべきKPIは「モデルの予測精度」ではなく、「1時間あたりの許容誤報回数」や「医師の確認時間を何分短縮できたか」という、現場の痛みに直結した指標になります。
「遅延」は「誤り」よりも罪深い?
一方で、ALS(筋萎縮性側索硬化症)の患者さんが思考で家電を操作するような、ブレイン・コンピュータ・インターフェース(BCI)の現場ではどうでしょうか。
Synchron社がNVIDIAと組んで開発を進める「Chiral」のロードマップを見ると、彼らが何より優先しているのは「低遅延(レイテンシ)」であることが分かります。
もしあなたが「電気をつけたい」と念じてから、AIが完璧に意図を理解するのに3秒かかるとしたらどうでしょう? おそらくストレスで使い物になりません。ここでは、多少の精度のブレよりも、「思考に対して即座に反応が返ってくること」のほうが、体験としての価値が高いのです。
つまり、BCIにおける最重要KPIは、「思考から実行までのミリ秒数」になります。どれだけ賢い基盤モデルでも、反応が遅ければ、それは「使えない道具」になってしまうのです。
「計測の方言」という落とし穴
現場のKPIを定めたら、次に直面するのが「データの壁」です。第2章でも触れましたが、脳波データは画像やテキストのように安定していません。
デバイスが変われば電極の位置が数ミリずれ、それだけで信号の波形(方言)が変わってしまいます。ここで、いきなり高価な基盤モデルを導入しても、学習データと現場データの「方言」が違えば、期待した性能は出ません。
ここで役立つのが、LCM(Large Cognition Model)のような、電極配置の違いを吸収する技術(Learnable Channel Mapping)です。初学者がまずやるべきは、自社の現場で使うデバイスがどの程度のノイズを含み、既存のモデルとどのくらい「方言」が違うのかを、小規模なデータ収集で確かめることです。
また、ニューロマーケティングの分野では、EEGと視線計測(アイトラッキング)を組み合わせることで、購買意図の予測精度を高めるアプローチが成功しています。脳波一本槍で戦うのではなく、「他のデータと組み合わせることで弱点を補えないか」と考える柔軟さも、現場の実装力を高める鍵となります。
実践的ロードマップ:小さく始めて、信頼を育てる
これから脳波AIプロジェクトを始めるなら、以下のようなステップで進めるのが、最もリスクの少ない「勝ち筋」ではないでしょうか。
- 「痛み」の特定とKPI定義:
モデルを選ぶ前に、「誰の、どんな時間を減らしたいのか」「どんな体験を作りたいのか」を言語化し、それを数値(誤報率や遅延時間)に落とし込む。
- 「方言」の確認(小規模パイロット):
手持ちのデバイスで実際にデータを採り、既存の基盤モデル(LaBraMなど)に入れてみる。どれくらい精度が出ないか(=方言の壁)を肌感覚で知る。
- ニューロセキュリティの実装:
本格導入の前に、データの同意取得フロー(オプトイン)や暗号化を設計する。これはMIND Actなどの規制に対応するだけでなく、ユーザーの信頼を得るための必須条件です。
- 人間との協働フローの構築:
AIはあくまで「支援」です。ICUなら「AIが検知し、医師が最終判断する」フローを、BCIなら「AIが提案し、ユーザーが承認する」インターフェースを磨き込む。
むすびに:脳波AIは「魔法」ではなく「パートナー」
脳波基盤モデルは、これまで「職人芸」だった脳波解析を、誰もが使える技術へと民主化する大きな可能性を秘めています。しかし、それは決して「何でも叶えてくれる魔法の杖」ではありません。
重要なのは、その技術を使って「人間をどうエンパワーするか」という視点です。
医師が雑務から解放され、患者と向き合う時間が増えること。
身体の自由を奪われた人が、再び世界とつながれること。
私たちが自分の内面をより深く理解し、健やかに暮らせること。
そうした未来を実現するために、モデルのスペック表から一度目を離し、目の前の「現場」と「人間」に向き合うことから始めてみてはいかがでしょうか。脳波AIという新しいパートナーとの旅は、まだ始まったばかりなのですから。
調査手法について
こちらの記事はデスクリサーチAIツール/エージェントのDeskrex.AIを使って作られています。DeskRexは市場調査のテーマに応じた幅広い項目のオートリサーチや、レポート生成ができるAIデスクリサーチツールです。
調査したいテーマの入力に応じて、AIが深堀りすべきキーワードや、広げるべき調査項目をレコメンドしながら、自動でリサーチを進めることができます。

また、ワンボタンで最新の100個以上のソースと20個以上の詳細な情報を調べもらい、レポートを生成してEmailに通知してくれる機能もあります。
ご利用をされたい方はこちらからお問い合わせください。
また、生成AI活用におけるLLMアプリ開発や新規事業のリサーチとコンサルティングも受け付けていますので、お困りの方はぜひお気軽にご相談ください。
市場調査やデスクリサーチの生成AIエージェントを作っています 仲間探し中 / Founder of AI Desk Research Agent @deskrex , https://deskrex.ai


コメント