
TurboQuantから入る導入:この技術は何を変えるのか
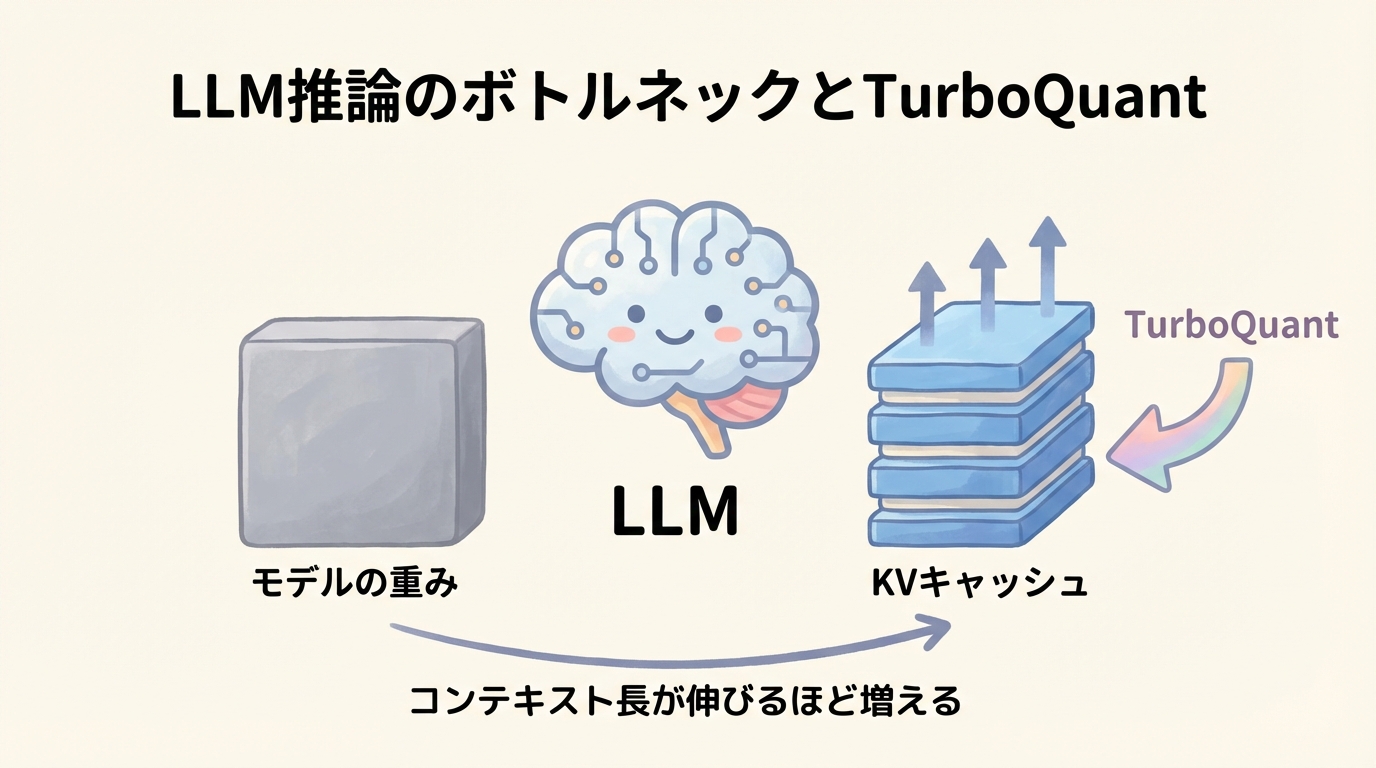
この記事ではGoogle ResearchのTurboQuantを軸に、LLM推論のボトルネックがどこに移ってきたのか、そしてそれをどう崩そうとしているのかを整理していきます。KVキャッシュ(Key-Value Cache:推論中に過去トークンの中間表現を一時保存する領域)の圧縮という少し地味なテーマですが、読み進めると「なぜここが今の生成AI競争で直接効いてくるのか」がわかるはずです。
TurboQuantは、Google Researchが公開した極低ビットの圧縮手法であり、長文脈LLMで急速に深刻化しているKVキャッシュのメモリ問題に、かなり正面から切り込んだ技術です。Googleはこの手法を、精度を損なわずに高い圧縮率を実現する方式として位置づけ、KVキャッシュ圧縮とベクトル検索の両方に適すると説明しています。ここで重要なのは、TurboQuantが単なる「軽量化技術」ではなく、LLM推論の制約そのものをずらし得る点にある、というところです。
これまで大規模言語モデルの効率化というと、重みの量子化や蒸留、あるいは推論サーバの並列化に注目が集まりやすかった側面があります。しかし実運用では、モデル本体の重みだけでなく、会話や長文入力の途中で蓄積されるKVキャッシュが巨大化し、メモリ容量とメモリ帯域の両方を圧迫します。特にコンテキスト長が伸びるほど、このキャッシュは線形に増え、長文要約、RAG(Retrieval-Augmented Generation:外部文書を検索して回答に組み込む手法)、コード補完、エージェント型ワークフローのようなユースケースでは、推論コストの中心が「計算」から「保持と転送」に移りやすくなっています。TurboQuantはまさにこの転換点を狙った技術であり、従来の量子化が抱えていた量子化定数の保存コスト、つまり余分なメモリ負担まで問題化している点が新しいところです。
何がそんなに新しいのか
Googleの説明によれば、TurboQuantは二段構成で動きます。第1段でPolarQuantを使ってベクトルを高品質に圧縮し、第2段でQJL(Quantized Johnson-Lindenstrauss:圧縮後の内積計算における誤差の偏りを1ビットで補正する手法)を使い、残差由来のバイアスを打ち消します。初学者向けに言えば、まず大半の情報をうまく小さく畳み、そのあと少ない追加情報で「圧縮によるズレ」を補正する発想です。この設計によって、圧縮率だけでなく、注意スコア(各トークンが互いにどれだけ関連するかを示す値)の計算精度を保ちやすくなっています。
この点は、従来の「低ビット化するとメモリは減るが、精度か速度のどちらかで妥協が必要」という発想と少し違います。TurboQuantは、圧縮そのものの情報理論的な効率を高めつつ、実際の推論処理で必要な内積計算の歪みを抑えようとしています。MarkTechPostが紹介する実験要約では、TurboQuantのMSE(平均二乗誤差:予測値と実際の値のズレを示す指標)歪みは理論下界に対して約2.7倍の範囲に収まるとされており、単なる経験則ベースではなく理論保証を伴うのが特徴です。推論最適化の世界では「実装すると速い」だけでは長続きせず、なぜその性能が出るのかを説明できる方式のほうが、後続の標準化やフレームワーク統合に乗りやすいからです。
実務インパクトは、メモリ削減よりも広い
TurboQuantの価値を数字で見ると、その意味がさらに明確になります。Googleの一次情報では、4ビット設定でH100 GPU上において、未量子化の32ビット形式と比べて注意スコア計算を最大8倍高速化するとされています。また外部報道では、KVキャッシュのメモリ使用量を少なくとも6倍削減しつつ、非圧縮モデルと同等の精度を保ったと報じられています。VentureBeatの解説でも推論コストを最大50%削減できる可能性が強調されています。
ここで見落としてはいけないのは、6倍のメモリ削減がそのまま6倍のコスト削減になるわけではない一方で、現場ではそれ以上の意味を持つ場合があることです。たとえば同じGPUメモリ上で、より長いコンテキストを扱えるようになります。同じコンテキスト長でも同時バッチ数を増やせますし、高価なGPUを使わずにより安価な環境へ推論を移すことも可能になります。つまりTurboQuantは、1回あたりの推論コスト削減だけでなく、提供可能なプロダクト体験の上限を押し上げる技術と言えるでしょう。Google以外の解説でも、オンプレミスやエッジでの実行可能性が高まる点が強調されており、これは単なる性能改善ではなく、導入可能性の拡張として見るべきだと思います。
社会・経済インパクトは、コスト低下だけでは終わらない
TurboQuantの普及が意味するのは、AIインフラ費用の圧縮だけではありません。メモリ効率が上がれば、同じ予算でより長い文脈を扱えるモデルが増え、RAGや常時対話型エージェントのように「記憶を持ち続ける」アプリケーションが現実的になります。
したがって、TurboQuantはメモリ半導体やGPU需要を単純に減らす技術と断定できません。むしろ、これまでコストや容量の壁で断念されていた長文脈アプリケーション、ローカルAI、産業現場の閉域推論を押し広げることで、AIワークロード全体を増幅する可能性があります。特に、医療、金融、公共、製造のようにデータを外に出しにくい領域では、オンプレミスで高性能モデルを回しやすくなることの意味は大きいです。技術の核心は圧縮ですが、実際に変わるのは導入の地理、予算配分、プロダクト設計、そしてAIを使える組織の裾野といったところではないでしょうか。
このレポートでは次に、KVキャッシュとはそもそも何か、なぜ長文脈LLMでボトルネックになるのかを整理したうえで、TurboQuantの技術的中身と比較対象との差分を順に掘り下げていきます。
なぜ今、KVキャッシュ圧縮が重要なのか
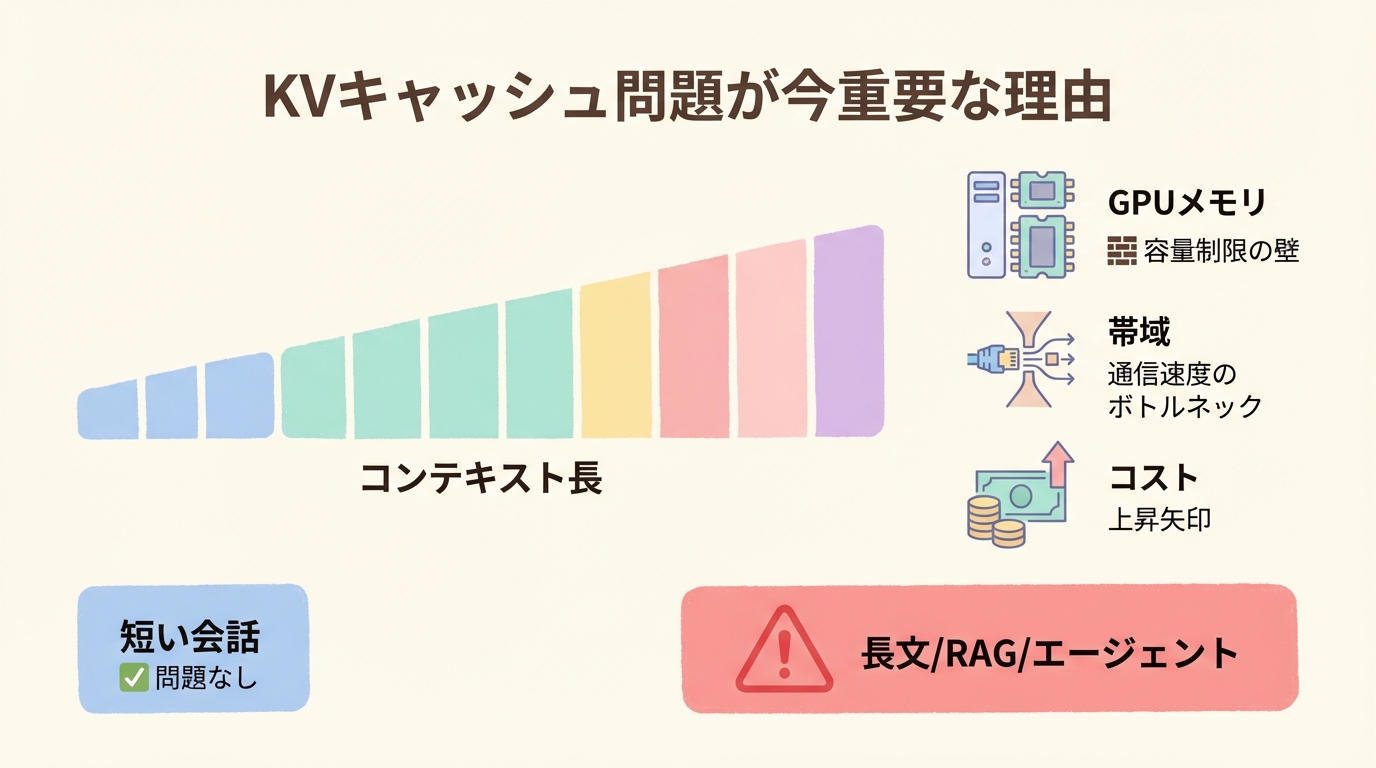
KVキャッシュ圧縮がいま急に重要視されている理由は、LLMの性能向上がそのまま推論の安さや扱いやすさにつながらなくなってきたからです。モデルの重みを一度GPUに載せれば終わりだった時代と違い、長文脈の対話、RAG、コード生成、エージェント実行では、推論のたびに過去トークンのキーとバリューを保持し続ける必要があります。この保持領域がKVキャッシュであり、文脈が伸びるほど増え続けます。PolarQuantの要約でも、KVキャッシュ圧縮がオンライン用途に特に適していると説明されており、これは問題が研究室内の最適化ではなく、実運用の中心課題に移っていることを示しています。
どうやら、モデルそのものを改善するより、「実際に動かすときのコスト構造」を変えることのほうが、今の生成AI競争でより大きな影響力を持ち始めている気がしてきました。
ボトルネックが計算量からメモリと帯域へ移っている
初学者向けに単純化すると、LLMは新しい1トークンを出すたびに、過去の文脈を全部ゼロから理解し直しているわけではありません。過去トークンから作った中間表現をKVキャッシュとして保存し、それを再利用して次の計算を速くしています。ところが、会話が長くなるほど保存量も増え、その結果としてGPUメモリ容量だけでなく、読み書きに必要なメモリ帯域も圧迫されます。KIVIの整理でも、この領域は「LLM推論時のKVキャッシュのメモリと帯域ボトルネック」を緩和する対象だと明示されています。
ここで重要なのは、重みの量子化だけでは十分でない場面が増えている点です。重みは静的ですが、KVキャッシュはセッションごとに動的に増えます。つまり、同じモデルでも短い質問応答では問題が目立たず、長文PDFの読解、複数ターン会話、社内文書検索を伴うRAG、コードリポジトリ全体を前提にした支援では、一気にコスト構造が変わります。TurboQuantやPolarQuantのような研究が注目されるのは、モデル本体よりも「実際に使うときの増殖コスト」を圧縮するからです。
長文脈化とエージェント化が、圧縮の価値を押し上げている
現在の生成AIプロダクトは、単発のQ&Aから、長い会話履歴を持つ常時アシスタントや、外部ツールをまたいで複数ステップ実行するエージェントへと進んでいます。こうした使い方では、1回の応答品質だけでなく、長い状態保持をどう安く回すかが競争力になります。OpenAI関連報道でも、需要の急増に対応するために大規模な計算資源確保が進んでおり、OpenAIはAmazon、SoftBank、Nvidiaから1100億ドルの調達を受けたとされています。
これは、推論効率が単なる技術改善ではなく、巨大な設備投資の回収と直結していることを意味します。ユーザー数が増えるほど、1トークンあたり数%の改善でも経済効果は大きくなります。OpenAIは週9億ユーザー、5000万人の有料サブスクライバー、900万を超えるエンタープライズユーザーを持つとされており、もしこの規模感で長文脈利用が増えれば、KVキャッシュの扱いは基盤収益性を左右する論点になります。
KVキャッシュ圧縮は、性能改善ではなく提供条件の改善でもある
KVキャッシュ圧縮の価値は、単に「速くなる」「省メモリになる」にとどまりません。実務では次のような形で効いてきます。
- 同じGPUでより長いコンテキストを扱えるようになる
- 同じコンテキスト長で同時処理数を増やせる
- より小さいGPUやオンプレ環境でも運用しやすくなる
- メモリ帯域制約が緩み、待ち時間のばらつきも抑えやすくなる
この点で、最近の研究は単なる圧縮率競争から一歩進んでいます。PolarQuantは「KVキャッシュを4.2倍以上圧縮」しつつ高い品質を示したとされ、TurboQuantはそこからさらにメモリ使用量を6分の1に下げながら注意計算を最大8倍高速化できると説明されています。この進化は、圧縮そのものより、圧縮した状態でどれだけ実用的に注意計算を回せるかへ焦点が移っていることを示しています。
| 観点 | 従来の課題 | KVキャッシュ圧縮がもたらす変化 |
|---|---|---|
| メモリ容量 | 長文脈でセッション継続が難しい | より長い入力や履歴を保持しやすい |
| メモリ帯域 | attention時の読み出しが重い | レイテンシとスループットを改善しやすい |
| インフラコスト | 高価なGPU依存が強い | 同等体験をより安価な構成で提供しやすい |
| プロダクト設計 | 履歴切り捨てや要約が必要 | 長い記憶を持つUXを作りやすい |
なぜ「今」なのかを市場側から見る
このテーマが今である理由は、技術成熟と市場圧力が重なったからでもあります。以前は、KVキャッシュ圧縮はやや専門的な推論最適化に見えやすかった側面がありました。しかし現在は、巨大モデルの商用化が進み、利用者数が増え、しかも高品質化のためにコンテキスト長が伸びています。Yahoo Financeの論考でも、OpenAIがAIインフラへ継続的に大規模投資していることは、GoogleやMetaのような大型競合も同様の投資を迫られる構図につながると指摘されています。
つまり、KVキャッシュ圧縮は研究者の専門領域ではなく、主要AI企業の設備投資効率を左右する共通課題になりました。より厳密に言えば、モデル性能競争が、推論の総所有コスト競争へ拡張されたのです。ここで勝つ企業は、同じ品質をより安く提供できるだけでなく、同じ原価でより長い文脈や高い同時接続数を実現できます。
社会的・経済的な意味は「安くなる」より広い
社会的にも、この種の圧縮技術の意味は大きいです。推論コストが下がれば、AIの恩恵は大企業の専用GPUクラスターだけでなく、予算制約の大きい中堅企業、自治体、教育機関、医療機関にも広がりやすくなります。さらに、オンプレミスや閉域網で高性能モデルを動かしやすくなれば、データ主権やプライバシー要件の厳しい領域での導入障壁も下がります。逆に言えば、圧縮が進まない限り、長文脈AIの恩恵は資本力のある一部プレイヤーに集中しやすい状況が続きます。
ただし、効率化は必ずしも総資源消費を減らすとは限りません。使いやすく安くなることで利用量が増え、結果として計算需要全体はむしろ拡大する可能性があります。したがってKVキャッシュ圧縮は、コスト削減技術であると同時に、AI普及をさらに加速させる増幅器でもあります。
この視点を踏まえると、次に確認すべきなのは、そもそもKVキャッシュがTransformerの中でどのように働き、なぜ長文脈になると急速に重くなるのか、そしてTurboQuantがその仕組みにどう対処しているかという技術的な中身です。
TurboQuantの中身:オンライン量子化をやさしく理解する
TurboQuantの核心は、ただビット数を減らすことではありません。むしろ重要なのは、LLM推論の途中で増え続けるKVキャッシュを、その場で圧縮しながら、注意計算に必要な内積の品質をほとんど崩さないよう設計している点にあります。Google ResearchはTurboQuantを、精度を損なわずに高い圧縮率を実現する方式として説明しており、KVキャッシュ圧縮とベクトル検索の両方に適すると位置づけています。前のセクションで見た「なぜKVキャッシュ圧縮が重要か」に対し、このセクションでは「なぜTurboQuantは圧縮しても壊れにくいのか」を、初学者向けに中身から整理します。
まず「オンライン量子化」とは何か
量子化とは、データを表現するビット数を減らしてデータサイズを小さくする手法のことです。たとえば32ビットの小数を4ビットに減らすことで、同じ情報を格納するのに必要なメモリを約8分の1にできます。そのなかで「オンライン量子化」とは、あらかじめ巨大な学習用データでコードブック(圧縮のための変換テーブル)を作り込んでから圧縮するのではなく、推論時に現れるベクトルをその場で圧縮できる方式のことです。TurboQuantはこの点で、従来のベクトル量子化が抱えがちだったデータ依存性や事前学習コストを避けやすくなっています。紹介ページでもTurboQuantは、データの特性に依存しないオンライン量子化フレームワークであり、アクセラレータとの親和性が高い設計だと要約されています。
ここで初学者向けに言い換えると、オンライン量子化は「出てきた値を、その場で、軽い手順で、低ビット化する」考え方です。KVキャッシュはセッションごとに動的に増えるので、重み量子化のように一度オフラインで準備して終わる世界とは違います。だからKVキャッシュ圧縮では、圧縮率だけでなく、今まさに生成中のデータへ即座に適用できることが重要になります。TurboQuantの実務価値は、まさにこの動的な対象に向けた設計にあります。
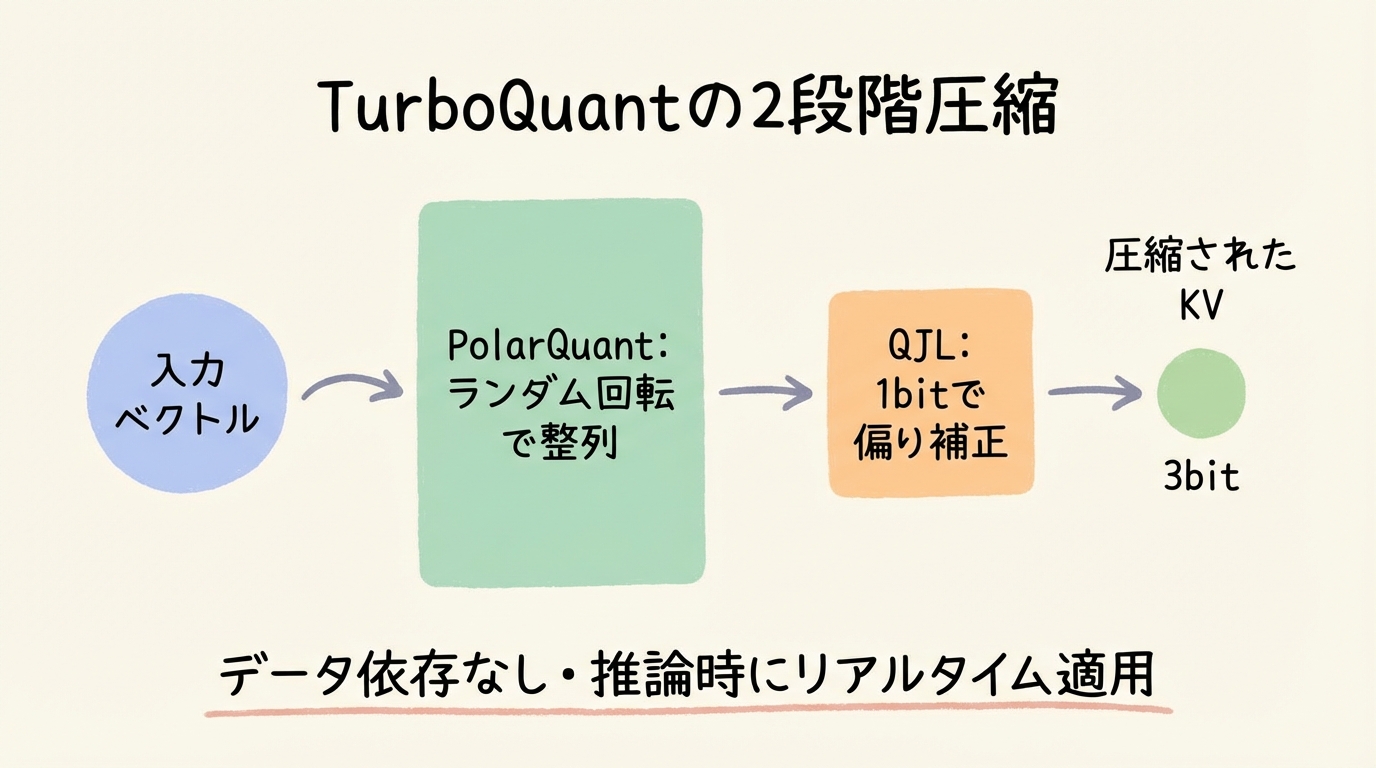
TurboQuantは2段階で動く
Google Researchの説明では、TurboQuantは二つの段階で構成されます。第一段階ではPolarQuantを使ってベクトルを高品質に圧縮し、第二段階ではQJLで残差誤差の偏りを打ち消します。この二段構成が、TurboQuantを単なる「ビット削減テクニック」ではなく、内積計算まで含めて設計された方式にしています。
第一段階のPolarQuantでは、ベクトルをいきなり雑に丸めるのではなく、まずランダム回転をかけてから各成分を量子化しやすい形に整えます。Google Researchは、TurboQuantがまずデータベクトルをランダムに回転させることから始めると説明しており、この前処理によってベクトルの幾何構造が単純化され、各部分に高品質な量子化器を適用しやすくなるとしています。直感的には、偏った値や外れ値の扱いを少し均し、「圧縮しやすい姿勢に回してから詰める」イメージです。
ただし、ここで終わるとまだ問題が残ります。量子化は平均的にはうまくいっても、注意計算で重要な内積計算では小さな偏りが積み上がって効いてしまうことがあります。そこで第二段階としてQJLを使います。Google Researchの説明によれば、このQJLの段階は数学的な誤差修正器として機能して偏りを除去するとされています。これは初学者向けに言えば、「圧縮で生じた見えにくいズレを、追加の軽い仕組みで補正する」段階です。TurboQuantが強いのは、圧縮率だけでなく、この偏り除去までひとまとまりで設計されているからです。
なぜ従来法より有利なのか
従来のベクトル量子化では、圧縮そのものとは別に、量子化定数を保持するためのメモリが必要になりやすかったです。Google Researchは、伝統的な手法では補助情報の保持による余分なメモリ負担が生じ、1値あたり1〜2ビット分の超過が増えると説明しています。つまり理論上は低ビットでも、実装上は補助情報のせいで思ったほど軽くならないことがありました。
TurboQuantはこの補助情報の重さをかなり意識して設計されています。紹介サイトでも、従来法が多数の正規化定数を完全精度で保存しなければならない一方、TurboQuantでは1ビットの残差補正(QJL)により正規化のオーバーヘッドが不要になると整理されています。この違いは地味に見えて実務上は大きいです。KVキャッシュ圧縮では、1値あたり数ビットの違いが長文脈全体では巨大な差になるからです。
性能をどう読むべきか
TurboQuantの印象的な点は、圧縮率と品質維持がかなり両立していることです。紹介ページでは、精度劣化なしの3bitKVキャッシュ圧縮、メモリ6分の1削減、注意計算最大8倍高速化と要約されています。またGoogle Researchの一次情報でも、KVボトルネックを下げつつAIモデル性能を維持することが強調されています。
Llama-3.1-8B-InstructのLongBench比較では、TurboQuantの3.5bit設定が50.06でフルキャッシュ16bitと同水準、2.5bitでも49.74を維持しており、PolarQuant 3.9bitの49.78やKIVI 3.0bitの48.50と比べても、低ビット域での品質保持がかなり堅いことが示されています。この読み方で重要なのは、TurboQuantが「絶対に常に最高性能」というより、「少ないビット数でもフル精度に非常に近い実用域を作りやすい」方式だという点です。
| 手法 | 代表的な特徴 | 実務上の含意 |
|---|---|---|
| KIVI | KeyとValueで異なる統計を使う非対称2bit量子化 | 追加学習不要で実用性が高く、先行ベースラインとして重要 |
| PolarQuant | ランダム前処理と極座標変換で高品質圧縮 | KV圧縮に強いが、TurboQuantの第一段階としても位置づく |
| TurboQuant | PolarQuant+QJLの二段構成 | 圧縮だけでなく内積誤差の偏り補正まで含めて最適化 |
理論的な新規性はどこにあるのか
TurboQuantは経験的にうまいだけではなく、理論限界に近い歪み率を狙う点でも新しいです。紹介ページでは、情報理論的な限界値に近づく設計と説明されています。さらに要約記事では、TurboQuantのMSE歪みが理論限界に対して約2.7倍という小さな定数倍の範囲に収まると整理されています。
これは実務者向けには、「たまたま効いた圧縮」ではなく、かなり筋のよい設計原理に基づいていることを意味します。特にKVキャッシュ圧縮は、モデルや文脈長やハードウェア条件が変わると挙動が崩れやすい領域なので、理論保証があることは汎化への期待につながります。もちろん理論保証がそのまま製品品質を保証するわけではありませんが、少なくとも研究としての寿命が短い一発芸では終わりにくいと言えます。
初学者が押さえるべき本質
初学者がTurboQuantを理解するときは、次の順番で捉えるとわかりやすいです。第一に、KVキャッシュは長文脈で増え続ける動的メモリであり、重み量子化とは別の課題です。第二に、TurboQuantはその動的メモリをオンラインに圧縮できます。第三に、単に値を荒くするのではなく、PolarQuantで高品質圧縮し、QJLで内積の偏りを補正します。第四に、その結果として、少ないビット数でも注意計算の品質を保ちやすくなります。つまりTurboQuantは、「低ビット化したのに意外と壊れない」のではなく、「壊れにくいように最初から内積計算まで見て作られた」方式なのです。
この理解を持つと、次に重要になるのは、TurboQuantが先行手法であるKIVIやPolarQuantと比べて、具体的にどこで優位なのか、またどの条件ではトレードオフが残るのかという比較の話です。次のセクションでは、その違いをベースラインごとに整理し、研究上の新規性と実務導入時の判断軸をより明確にしていきます。
何がすごいのか:性能指標と実用インパクト

TurboQuantのすごさは、単に「よく圧縮できる」ことではありません。LLM推論で本当に効く三つの指標、つまりメモリ使用量、計算速度、品質維持を同時に改善しようとしている点にあります。紹介ページでは、TurboQuantは精度劣化なしの3bit KVキャッシュ圧縮、メモリ6分の1削減、注意計算最大8倍高速化と要約されており、3bit級の圧縮でKVキャッシュを扱いながら、メモリを6分の1規模に抑え、注意計算を最大8倍高速化できると整理されています。Google Researchの説明でも、TurboQuantはAIモデルの性能を犠牲にせずにKVキャッシュのボトルネックを削減することを狙う方式として位置づけられています。この三つが同時に立つことが重要で、どれか一つだけなら従来法にも例はありますが、実運用では三つのバランスが崩れると採用しにくくなります。
まず見るべき性能指標は「圧縮率」ではなく「総合効率」
初学者が見落としやすいのは、KVキャッシュ圧縮の評価がビット数だけでは決まらないことです。ビット数が低くても、補助情報の保持や復元コストが重ければ、実際のGPU運用では得をしません。Google Researchは従来法について、量子化の補助情報による余分なメモリ負担があり、1値あたり1〜2ビット分の超過が生じると説明しています。TurboQuantが実用的に見えるのは、この余分なオーバーヘッドを抑える設計まで含んでいるからです。紹介ページでも、従来法が多数の正規化定数を完全精度で保存しなければならない一方、TurboQuantでは1ビットの残差補正(QJL)により正規化のオーバーヘッドが不要になると整理されています。つまり、理論上の圧縮率ではなく、実装したときにどれだけ本当に軽くなるかまで踏み込んでいます。
メモリ削減の価値は、長文脈と同時接続数で一気に効く
KVキャッシュは、推論を続ける限り増え続けるメモリです。したがって、TurboQuantのメモリ6分の1という主張は、単にGPUの空き容量が増えるという意味にとどまりません。実務では、この余裕がそのまま長いコンテキスト、より大きなバッチ、あるいは同一GPU上でのセッション同時処理数の増加に変わります。KVCISの説明でも、圧縮の追加コストが小さいことが「バッチサイズ拡大やより長いコンテキスト対応に直接つながる」とされており、KV圧縮技術の価値が単独のメモリ節約ではなく、運用可能性の拡張にあることがわかります。TurboQuantは圧縮率が特に大きいため、この運用余地の増え方も大きいと考えられます。
速度改善は「モデルが軽くなる」ではなく「注意計算が速くなる」ことに意味がある
TurboQuantのもう一つのインパクトは、速度指標がかなり具体的な点にあります。紹介ページでは注意計算の最大8倍高速化とされ、特に注意計算そのものの高速化が強調されています。前のセクションで見た通り、TurboQuantは内積計算の歪みや偏りを強く意識した設計であり、単なる保存容量削減ではなく、読み出しと注意スコア計算の効率化まで見ています。この点は、メモリ帯域が律速になりやすい長文脈推論で特に効きます。モデル重みの量子化は主にモデル常駐コストを下げますが、KV圧縮は生成のたびに繰り返されるメモリアクセスを減らすため、対話型推論の体感速度により直結しやすい特徴があります。
品質維持が本丸であり、ここが崩れないから導入候補になる
どれだけ速くても、応答品質が落ちれば本番導入は難しいです。TurboQuantが注目される最大の理由は、Google側が「精度劣化ゼロ」と明確に打ち出していることです。もちろん、この表現は評価条件つきで読む必要があり、すべてのモデル、すべてのタスク、すべての文脈長で絶対不変と解釈すべきではありません。それでも、極低ビット圧縮で品質劣化が観測しにくい水準まで抑えたという主張は、KV圧縮の採用障壁を大きく下げます。
先行手法と比べると、TurboQuantは「圧縮単体」より「システム全体」で強い
KIVIは、追加学習不要の非対称2bit量子化でKVキャッシュのメモリと帯域ボトルネックを緩和する重要な先行研究であり、2.6倍のメモリ削減と2.35倍〜3.47倍のスループット改善が参照されています。これは実用上十分に大きい成果ですが、TurboQuantはそこからさらに、少なくとも6倍のKVメモリ削減と最大8倍の注意計算高速化を狙っている点で、改善幅が一段大きいです。PolarQuantも4.2倍超圧縮で高品質とされており有力ですが、TurboQuantはその圧縮品質に加えてQJLによる誤差補正を組み合わせることで、品質維持と実効効率をさらに押し上げています。要するに、TurboQuantは単独の量子化トリックというより、KVキャッシュを保存し、読み出し、注意計算に使うまでの流れをまとめて最適化した点が強みです。
| 観点 | KIVI | PolarQuant | TurboQuant |
|---|---|---|---|
| 主な狙い | 追加学習不要のKV量子化 | 高品質なオンライン圧縮 | 高品質圧縮と内積誤差補正の統合 |
| メモリ削減 | 2.6倍 | 4.2倍超 | 少なくとも6倍 |
| 速度改善 | 2.35倍〜3.47倍 | 文脈依存で改善 | 注意計算最大8倍 |
| 品質面の打ち出し | 実用的な精度維持 | SOTA級品質 | 精度劣化ゼロを強調 |
| 実務上の意味 | 先行ベースラインとして重要 | 高圧縮の有力候補 | 導入判断を変える総合効率 |
実務インパクトは、GPU節約よりも「サービス設計の自由度」にある
実務で本当に大きいのは、TurboQuantがインフラ設計の選択肢を広げることです。メモリ制約が厳しい現場では、長文脈を諦める、同時接続数を絞る、より高価なGPUに上げる、といった対応が必要になります。KVキャッシュを6倍規模で圧縮できるなら、その一部は単純なコスト削減になりますが、より本質的には同じハードウェアでできることが増えます。たとえば、RAGで長い参照文書を投げても文脈を切り捨てにくくなりますし、エージェント型処理で複数ステップの履歴を保持しやすくなります。高速化も加われば、応答待ち時間の短縮だけでなく、ピーク時のリクエスト処理能力の向上にもつながります。これはSaaS型のLLMサービス、コンタクトセンター自動化、開発支援ツール、業務検索のいずれでも直接的な価値になります。
ただし、TurboQuantは非常に有望ですが、実務導入ではいくつか冷静に確認すべき点もあります。第一に、「精度劣化ゼロ」は評価範囲の中での結果なので、自社タスク、とくに日本語・長文・構造化出力・マルチターン対話で再検証する必要があります。第二に、注意計算高速化の上限値はハードウェアや実装に依存するため、H100級での最良値がそのまま一般GPU環境に出るとは限りません。第三に、KV圧縮は重み量子化やページング、連続バッチ処理など他の最適化と組み合わせて初めて最大効果が出る場合が多いです。したがって、TurboQuantは魔法の一手というより、LLM推論スタックの中核部品として評価するのが適切でしょう。
ここまで見てきたように、TurboQuantは「少ないメモリで、速く、しかも品質を落としにくい」という、現場が最も欲しい条件をかなり高い水準で束ねています。次のセクションでは、この性能がどのような比較軸で先行手法より優位に立つのか、そして逆にどの条件では他方式や併用戦略が有利になりうるのかを、より具体的に読み解いていきます。
KIVI・PolarQuant・KVCISとの比較で見えるTurboQuantの位置づけ
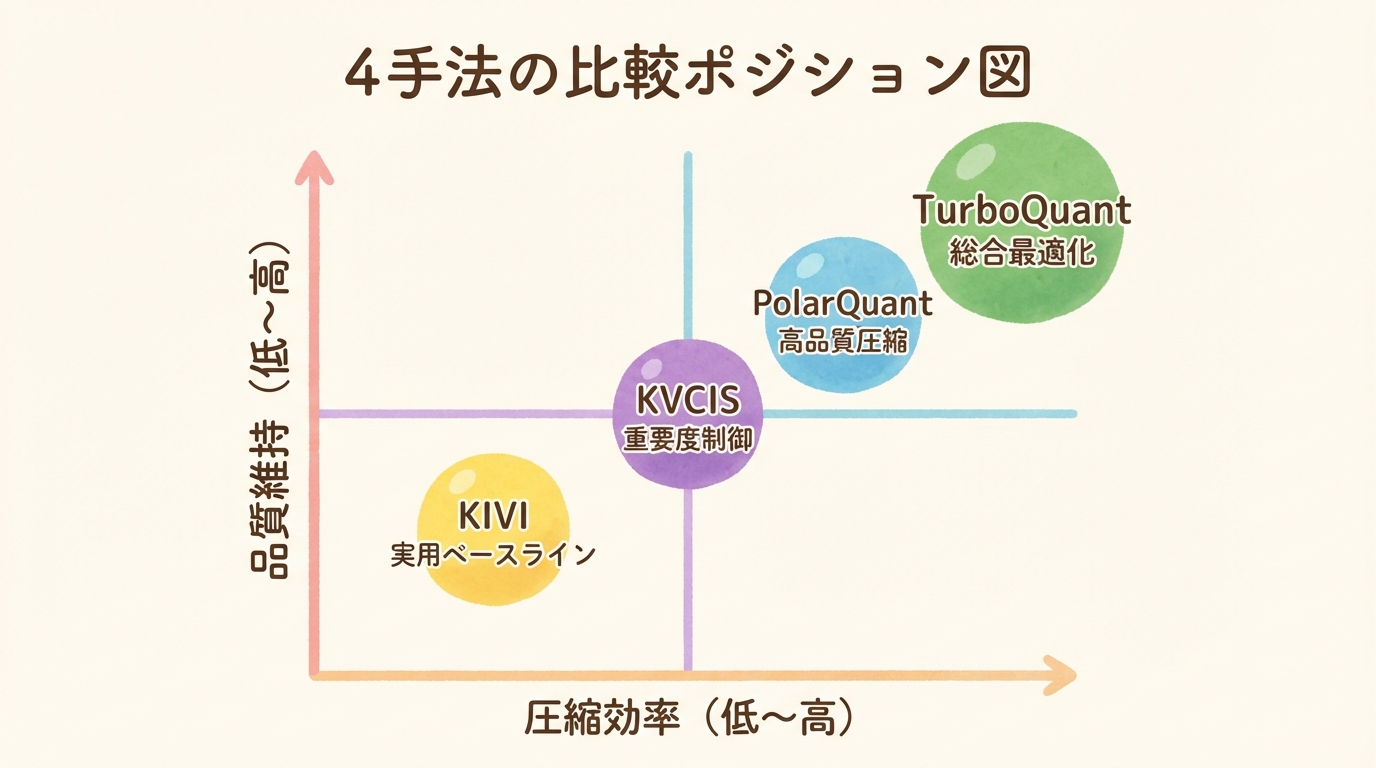
TurboQuantの価値は、単独で見るよりも、KIVI、PolarQuant、KVCISという近接手法と並べたときにはっきりします。結論から言えば、KIVIは「実務で効く軽量量子化の基準点」、PolarQuantは「オンライン量子化の品質を押し上げた中核技術」、KVCISは「何を残すかを賢く選ぶ重要度制御」、そしてTurboQuantはそれらの流れを受けて圧縮品質、オーバーヘッド削減、注意計算の精度補正までを一体化した総合最適化として位置づけるのが最も自然です。
まず比較軸をそろえると、4手法は競合であると同時に発想が異なる
初学者には、これら4つをすべて「KVキャッシュを小さくする方法」と一括りに見てしまいやすいです。しかし実際には、何を最適化しているかが異なります。KIVIはKeyとValueの統計特性の違いを利用し、追加学習なしで2bit非対称量子化を行うことで、省メモリ化とスループット改善を狙う方式であり、先行する実用ベースラインとして重要な存在です。PolarQuantはランダム前処理と極座標変換を使って、オンライン量子化でも高品質を出しやすくしました。KVCISは量子化そのものより、「どのトークンのKVを厚く残すべきか」を事前予測する方向に軸足があります。一方のTurboQuantは、Google Researchの説明どおりPolarQuantを第一段に使い、さらに1ビットのQJLで残差誤差の偏りを消す二段構成を取ります。つまりTurboQuantは、KIVIのような単純な低ビット化とも、KVCISのような選別型とも少し違い、「圧縮そのものの質」と「注意計算に効く誤差制御」を両方まとめて扱っています。
KIVIと比べると、TurboQuantは「低ビット化」から「低ビットでも壊れにくい設計」へ進んでいる
KIVIの意義は大きいです。Keyをper-channel(チャンネル単位)、Valueをper-token(トークン単位)で扱い分ける非対称設計により、追加学習なしでも実運用に耐えるKV量子化を示し、ピークメモリ削減2.6倍、スループット2.35倍〜3.47倍、最大バッチサイズ4倍という、かなり具体的な改善を出しています。これは「KVキャッシュ量子化は研究上の小技ではなく、本当に運用で効く」ということを示した点で画期的でした。
しかしTurboQuantは、その次の段階に進んでいます。Google ResearchはTurboQuantについて、KVキャッシュをわずか3ビットで量子化しつつ、追加学習や微調整なしで少なくとも6倍のメモリ削減を実現したと説明しています。ここで重要なのは、ビット幅だけを見るとKIVIの2bitのほうがさらに低いのに、総合性能ではTurboQuantが有利に見える点です。理由は、TurboQuantが従来法の弱点である量子化定数の保持コストを正面から問題化し、そのオーバーヘッドを減らす設計まで含めているからです。KIVIが「少ないビットで量子化する方法」だとすれば、TurboQuantは「少ない実効コストで、注意計算に効く形で圧縮する方法」だと言えます。
PolarQuantと比べると、TurboQuantは継承者であり拡張者でもある
TurboQuantとPolarQuantの関係は、単純な競合よりも、基盤技術とその拡張に近いです。Google Research自身が、TurboQuantの第一段を「高品質な圧縮(PolarQuant)」として明記しているため、PolarQuantはTurboQuantに内包される中核部品として理解するのが正確です。PolarQuant単体でも、OpenReviewの要約ではKVキャッシュ圧縮などのオンライン用途に非常に適しており、KVキャッシュを4.2倍超圧縮できると報告されています。
ただしTurboQuantは、そこで止まりません。PolarQuantだけでは残るわずかな誤差に対し、QJLを数学的な誤差修正器として使い、注意スコアのバイアスを消すという発想を加えています。この一手によって、TurboQuantは「高品質な圧縮」から「高品質な注意計算」へと評価軸を広げています。つまりPolarQuantが圧縮器として優れているのに対し、TurboQuantは推論系全体の挙動まで見ています。
KVCISと比べると、TurboQuantは「どう圧縮するか」、KVCISは「何を圧縮するか」を解いている
KVCISは、この比較の中で少し毛色が違います。KVCISの本質は、トークン重要度を中間層活性から事前予測し、KVキャッシュ格納を先回りして最適化する点にあります。すべてのトークンを同じ精度で保存するのではなく、重要なものを厚く残し、重要でないものを大胆に削るという考え方です。
この発想は、TurboQuantとは対立というより補完に近いです。TurboQuantは、保存するKV表現そのものを低ビットで高品質に圧縮します。一方KVCISは、そもそも保存対象を重要度で選び分けます。前者は「密度を下げる」、後者は「量そのものを減らす」と言えます。したがって、長期的には両者を組み合わせる方向がかなり有望です。たとえば、KVCISで重要度の低いトークンを薄く扱い、残すべきトークン群にTurboQuantをかければ、メモリ削減と品質維持の両面でさらに強い可能性があります。
比較表で整理すると、TurboQuantの強みは「総合点の高さ」にある
| 手法 | 主な発想 | 学習・調整 | 代表的な改善 | 強み | 弱み・注意点 |
|---|---|---|---|---|---|
| KIVI | Key/Valueで異なる統計特性を使う非対称2bit量子化 | 追加学習不要 | ピークメモリ2.6倍削減、スループット2.35〜3.47倍 | 実装イメージが比較的明快で、先行ベースラインとして重要 | 極低ビットでも総合品質と速度をどこまで伸ばせるかに限界 |
| PolarQuant | ランダム前処理+極座標変換によるオンライン量子化 | 学習不要の方向 | KVキャッシュを4.2倍超圧縮 | オンライン圧縮の質が高く、TurboQuantの土台になる | 注意計算の誤差補正までは単体で担わない |
| KVCIS | 活性値から重要トークンを事前予測 | 軽量な追加予測 | メモリ50%削減でも品質維持例 | 何を残すかを賢く決められる | 圧縮器単体ではなく、別の量子化法と組み合わせ前提になりやすい |
| TurboQuant | PolarQuant+QJLで圧縮品質と誤差補正を統合 | 追加学習・微調整なし | 3bit級、少なくとも6倍メモリ削減、注意計算最大8倍高速化 | 圧縮率、速度、品質維持を同時に打ち出せる | 実環境での再現性や他最適化との相性評価は必要 |
実務の観点では、TurboQuantは「導入判断を変える閾値」に近い
なぜTurboQuantがここまで注目されるかというと、比較対象より少し良い、という水準ではなく、導入判断そのものを変えうる数字を出しているからです。Google Researchは全ベンチマークで完全な精度を保ちながらKVメモリを少なくとも6分の1に削減し、さらに4ビット設定では32ビット未量子化キーと比べて最大8倍の性能向上を達成したと述べています。KIVIやPolarQuantが有力でも、企業のインフラ担当者やプロダクト責任者が本当に動くのは、「少し省メモリになる」段階より、「GPU構成や提供価格を見直せる」段階です。少なくとも6倍のKV削減と最大8倍の注意計算高速化は、その閾値にかなり近いと言えます。
それでもKIVI・PolarQuant・KVCISが重要な理由
ただし、TurboQuantだけを特別視しすぎるのも危険です。KIVIがなければ、追加学習なしでKV量子化を実運用に持ち込む発想はここまで明瞭にならなかったでしょう。PolarQuantがなければ、オンライン量子化の品質をここまで高く維持する道筋は見えにくかったはずです。KVCISが示した「事後的な注意重みではなく、事前の活性値から重要度を読む」という転換も、今後のKV最適化の方向を広げています。TurboQuantは強いですが、何もないところから突然現れたわけではなく、これら先行・周辺手法の流れを束ねて一段上の総合性能へ押し上げた存在だと理解するほうが、技術史としても実務判断としても正確でしょう。
その意味で、TurboQuantの位置づけは「最終解」ではなく、「KVキャッシュ最適化が個別技術から統合設計へ移ったことを示す象徴」に近いと思います。次に見るべきなのは、この統合設計が実際の導入現場や社会・経済全体にどんな変化をもたらすのか、という広い視野での考察です。
社会と経済にどう効くのか:LLM運用コストから普及構造まで
TurboQuantの社会的・経済的な意味は、単に「推論が少し速くなる」ことではありません。より本質的には、長文脈LLMの運用で増え続けるKVキャッシュを強く圧縮できることで、これまで高コストゆえに成立しにくかった用途を、事業として成立可能なラインまで引き下げうる点にあります。Google ResearchがTurboQuantを、KVキャッシュをわずか3ビットで扱いながら追加学習や微調整なしで少なくとも6倍のメモリ削減を実現する方式として位置づけていることは、この技術が研究上の工夫ではなく、運用原価に直接効くレイヤーにあることを示しています。
まず効くのは、1回あたりの推論原価ではなく「同時に回せる仕事量」
LLMの経済性を考えるとき、初学者はしばしば「1トークンいくらか」だけを見がちです。しかし実務では、それと同じくらい重要なのが、限られたGPUやTPU資源で何ユーザー分を同時に捌けるか、どれだけ長い文脈を保持できるか、そしてピーク時にどれだけ落ちずに回せるかです。KVキャッシュは文脈長と同時実行数に応じて膨らむため、ここを6倍規模で削れるなら、同じハードウェアでより多くのセッションを収容できる余地が生まれます。また、TurboQuantは注意計算も最大8倍高速化しうるため、これは単なる容量節約ではなく、処理密度の改善でもあります。
この点は、Google Cloud側がJetStreamで示している運用最適化ともよく噛み合います。JetStreamは、continuous batching(複数リクエストを連続的に処理する手法)やsliding window attention、さらに重み・活性値・KVキャッシュへのint8量子化を組み合わせ、Cloud TPU v5e-8上で最大4783トークン/秒を実現しつつ、Gemma 7Bでは100万トークンあたり0.30ドルという価格で提供し、従来スタックの1.10ドルと比べて1ドルあたり最大3倍の推論量を達成したと説明されています。TurboQuantがこの系譜に載るなら、今後のコスト削減はモデル単体ではなく、量子化、サービング、バッチング、ハードウェア最適化の積として効いてくると考えるのが自然です。
価格が下がると、普及する用途の種類そのものが変わる
コスト低下の意味は、既存用途が安くなることだけではありません。むしろ重要なのは、これまで採算が合わなかった利用形態が市場に現れることです。たとえば長文RAG、複数文書をまたぐ要約、企業内ナレッジ検索、コードベース全体を読む支援、長時間のエージェント対話は、いずれもKVキャッシュの負担が大きいです。したがってTurboQuantのような技術は、単発の短いチャットよりも、長いセッションを持つ高付加価値業務で効きやすくなります。Google自身もTurboQuantを特に検索とAIの領域での活用に向けて展開していると説明しており、これは検索拡張生成や情報アクセスの再設計にまで波及しうることを示唆しています。
社会的に見ると、この変化は「AIを使える企業」と「AIを深く業務に埋め込める企業」の差を縮める方向に働く可能性があります。これまでは、長文脈処理や高同時接続を伴うAI機能は、大量のGPU予算を確保できる一部企業の優位になりやすかったです。しかし、推論のメモリ効率と速度が改善すれば、中堅企業や業務特化SaaSでも、より長い文脈を扱う機能を標準機能として提供しやすくなります。言い換えると、TurboQuantのような圧縮技術は、モデル能力そのものを民主化するというより、モデル能力を「業務に落とし込むコスト」を下げることで普及を後押しします。
データセンター経済では、GPU調達競争から運用効率競争へ軸がずれる
現在の生成AI市場では、しばしば「どれだけGPUを確保できるか」が競争力として語られます。しかしKVキャッシュ圧縮が強く効き始めると、競争軸は単純な台数確保だけではなく、1台あたりでどれだけ多くの推論需要をさばけるかへ移っていきます。これは資本支出の意味を変えます。設備投資額が同じでも、メモリ制約が緩むことで、より高い同時実行数や長いコンテキストを提供できれば、売上化できる推論量が増えるからです。
この構図は、ハードウェア側の議論とも整合します。Googleは初代TPUの時点で、推論向けに従来システム比15〜30倍の性能、電力効率30〜80倍という指標を示しており、性能あたり電力の改善が大規模サービスの経済性を左右することを早くから示していました。TurboQuantはハードウェアそのものではありませんが、メモリ帯域とキャッシュ容量の圧迫を下げることで、既存ハードウェアの実効効率を引き上げます。つまり新しい半導体を待たずに、ソフトウェア側から設備効率を押し上げる手段として大きな意味があります。
エネルギー消費と環境負荷にも、間接的だが無視できない効果がある
生成AIの社会的批判の一つは、推論のエネルギー消費が見えにくいまま拡大しがちな点にあります。KVキャッシュ圧縮は、この問題に対して比較的地味ですが堅実な改善策になります。メモリ使用量が減り、注意計算が速くなれば、同じ応答を返すために必要な計算資源と処理時間を減らせる可能性があります。
外部のスタートアップ動向を見ても、市場はすでに「推論をどう安く、低電力で回すか」に強く反応しています。たとえばElastixAIは、LLM推論向けに総保有コストを最大50分の1に、消費電力を80%削減できると主張して資金調達しており、推論最適化が単なる研究テーマではなく、電力と設備の産業課題になっていることがわかります。TurboQuantは、その流れの中で、ハードウェア置換ではなく圧縮アルゴリズムで効率を取りにいく点に特徴があります。
企業の料金設計とプロダクト設計も変わる
経済インパクトはインフラ企業だけの話ではありません。API提供企業やSaaS企業にとっては、推論コストの低下が料金体系の自由度を広げます。たとえば、これまで高額プランにしか載せられなかった長文解析や大規模RAGを、より広いユーザー層に開放できるかもしれません。あるいは、同じ価格のまま応答品質、文脈長、同時利用数を引き上げることで、解約率を下げる戦略も取りやすくなります。
実際、Google CloudのJetStreamでは、推論基盤の改善がそのまま1ドルあたりより多くの推論を実現するという価値に翻訳されています。TurboQuantのような技術が基盤に入ってくると、価格競争は単に安くする競争ではなく、同じ単価でどこまで文脈長や応答性能を含められるかという、体験設計の競争に変わる可能性が高いです。これはユーザーにとっては価格低下以上に重要で、AIが「高価な追加機能」から「標準機能」へ移る転換点になりうるでしょう。
ただし、社会的便益は自動では実現しない
一方で、効率化がそのまま社会的に望ましい結果を生むとは限りません。推論が安くなれば、監視的な自動化、低品質コンテンツの大量生成、過剰なエージェント常時稼働のような使われ方も増えうります。さらに、単価が下がることで総需要が増え、結果としてデータセンター全体の消費電力がむしろ増える、いわゆるリバウンド効果も起こりうります。したがってTurboQuantの社会的評価は、「1回の推論をどれだけ節約したか」だけではなく、「節約によってどんな用途が拡大したか」まで含めて見る必要があります。
それでも、少なくとも現時点では、TurboQuantのようなKVキャッシュ圧縮は、生成AIの持続可能性に向けたかなり現実的な打ち手です。モデルを全面的に作り直さず、追加学習も不要で、既存の推論スタックに組み込みやすい形で効率を改善できるからです。社会的にはAIの利用可能性を押し広げ、経済的には推論原価と設備効率を改善し、産業的にはハードウェア争奪戦を運用最適化競争へと少しずつ移していきます。この三層の変化こそが、TurboQuantの本当のインパクトではないでしょうか。
よくある質問(FAQ)
Q: TurboQuantとは何ですか?
A: Google Researchが開発したLLMのKVキャッシュ圧縮アルゴリズムです。3bitでKVキャッシュを圧縮しながら精度を落とさず、メモリを少なくとも6分の1に削減し、注意計算を最大8倍高速化します。PolarQuantとQJLという2段階の構造を持ち、追加学習不要で既存の推論スタックに組み込める点が特徴です。
Q: KVキャッシュとは何ですか?なぜ重要なのですか?
A: KVキャッシュ(Key-Value Cache)は、LLMが次のトークンを生成するとき、過去の文脈から計算した中間表現を保存しておく領域です。会話や文書が長くなるほど増え続けるため、GPUのメモリ容量とメモリ帯域の両方を圧迫します。長文要約・RAG・エージェント実行のような用途では推論コストの主因になっており、ここを効率化できれば、同じGPUでより長い文脈を扱ったり同時接続数を増やしたりできます。
Q: 「精度劣化ゼロ」とはどういう意味ですか?完全に劣化しないのですか?
A: Googleが主張する「精度劣化ゼロ」は、LongBenchなど標準ベンチマークで非圧縮のフルキャッシュと同等の結果が得られたという意味です。ただし、これはすべてのモデル・すべてのタスク・すべての言語で保証されるわけではありません。日本語・長文・構造化出力・マルチターン対話など、自社の具体的な用途で改めて検証することが実務上は必要です。
Q: TurboQuantとKIVIは何が違うのですか?
A: KIVIはKeyをper-channel、Valueをper-tokenで扱う非対称2bit量子化で、追加学習不要でも実運用に耐えることを示した重要な先行研究です(ピークメモリ2.6倍削減・スループット最大3.47倍改善)。TurboQuantはKIVIよりビット数は多い3bitながら、量子化定数の保存コスト(余分なメモリ負担)まで削減する設計を持ち、結果としてメモリ6倍削減・注意計算最大8倍高速化という数字を出しています。KIVIが「低ビットで量子化する方法」とすれば、TurboQuantは「少ない実効コストで注意計算に効く形で圧縮する方法」と言えます。
Q: TurboQuantは実際にどうやって導入できますか?
A: 2026年3月時点では、Google ResearchのブログとturboquantにTurboQuantの概要が公開されています。ただし一般向けのOSSライブラリや標準フレームワークへの統合はまだ進行中の段階です。実務導入を検討するなら、まず公式リポジトリを確認し、自社のモデル・タスク・ハードウェア環境で品質と速度を実測することが出発点になります。
Q: TurboQuantはどんな用途で最も効きますか?
A: KVキャッシュが大きくなりやすい用途、つまり長文脈RAG(社内文書検索・長文PDFの読解)、複数ターンの会話型AI、コードベース全体を参照する開発支援、複数ステップを実行するエージェント型ワークフローで効果が出やすいです。逆に、1〜2往復程度の短い質問応答や、コンテキスト長がさほど長くない用途では、圧縮のメリットが相対的に小さくなります。
Q: TurboQuantの普及でGPU需要は減りますか?
A: 必ずしも減るとは言えません。推論が安くなることで、これまで採算が合わなかった用途が増え、AIワークロード全体が拡大するリバウンド効果が起きる可能性があります。ただしTurboQuantは、同じGPU台数でより多くのセッション・より長い文脈・より高い同時接続数を実現できるようにするため、新規のGPU調達ペースを緩和したり、より安価なGPU構成での運用を可能にしたりする効果が期待できます。
調査手法について
こちらの記事はグラフAIリサーチプラットフォームのSnorbeを使って作られています。Snorbeは研究開発・新規事業向けの調査テーマに応じた幅広い項目のオートリサーチや、ナレッジグラフの構築、構造化レポートの生成ができるAIリサーチツールです。
Screenshot
調査したいテーマを入力するだけで、AIが深堀りすべき観点や広げるべき調査項目をレコメンドしながら、自動でリサーチを進めます。収集した情報はナレッジグラフとして蓄積され、未調査領域(ホワイトスペース)を可視化しながら調査の網羅性を高めていけます。
また、観点マトリクスを30秒・構造化レポートを10分で自動生成する機能があり、出典付きのレポートをMarkdown/PDF形式でエクスポートできます。調査の元データも保存されるため、ファクトチェックや社内共有も容易です。
ご利用をご希望の方は、こちらよりお申し込みください。
また、グラフAIを活用した社内ナレッジ管理や、研究開発・新規事業のリサーチ支援、セルフホスト導入のご相談も受け付けています。お困りの方はお気軽にご連絡ください。
市場調査やデスクリサーチの生成AIエージェントを作っています 仲間探し中 / Founder of AI Desk Research Agent @deskrex , https://deskrex.ai


コメント