
マスクが仕掛ける「知識の再定義」:Grokipediaの野望はWikipediaを超えるか
イーロン・マスク氏が新たに世に送り出した「Grokipedia」。多くの人はこれを単に「Wikipediaの新たなライバル」と捉えているかもしれません。しかし、彼の発言やその設計思想を深く読み解くと、どうやらこれは単なる百科事典サービスではなく、AI時代における「知識の定義権」そのものを書き換えようとする壮大な実験であるような気がしてきました。
Grokipediaは、私たちの情報との向き合い方を根本から変えてしまう可能性を秘めています。本稿では、マスク氏が掲げるビジョンとその裏にある戦略を紐解き、この野心的なプロジェクトが私たちの未来にどのような影響を与えるのかを探っていきます。
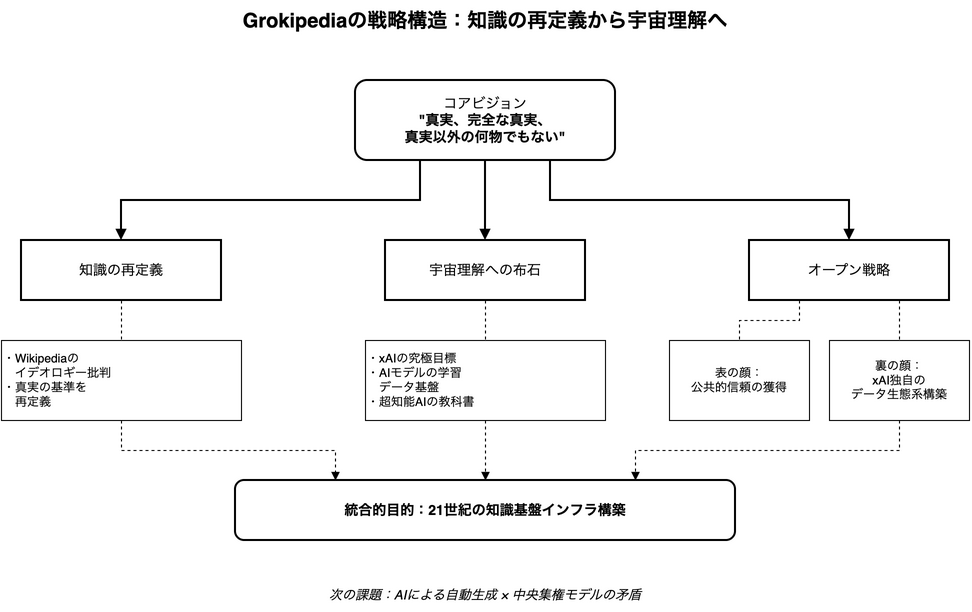
「真実」を掲げた知識の再定義
「真実、完全な真実、真実以外の何物でもない」。これは、マスク氏がGrokipediaの目標として掲げた、極めてシンプルかつ強烈なメッセージです。
彼は長年、Wikipediaが特定のイデオロギーに偏っていると批判してきました。その彼が打ち出したGrokipediaは、単に情報の正確性を高めるだけでなく、「何が真実か」を判断する基準そのものを再定義しようとする挑戦状のようにも見えます。
このプロジェクトは、単なる百科事典の枠を超え、AIが生成する知識の正当性を問う、21世紀の核心的な課題に真正面から取り組むものと言えるでしょう。
宇宙理解への壮大な布石
Grokipediaの野望は、地球上の知識を整理するだけにとどまりません。マスク氏が率いるAI企業xAIは、その究極の目標を「宇宙を理解する」ことにあると公言しています。そして彼は、Grokipediaこそが、その壮大なミッションを達成するための「不可欠なステップ」だと位置づけているのです。
これは一体何を意味するのでしょうか。どうやらGrokipediaは、xAIが開発するAIモデルにとって、高品質で信頼できる学習データを提供する「基盤インフラ」としての役割を担っているようです。
つまり、宇宙の謎を解き明かす超知能AIを育てるための、いわば「教科書」を自らの手で作り上げようとしているわけです。この視点に立つと、Grokipediaは単なる公共サービスではなく、xAIの未来を左右する極めて戦略的なプロジェクトであることが見えてきます。
オープン戦略が隠す二重の目的
マスク氏は、Grokipediaを「完全にオープンソースで誰でも無料で使える」ものにすると宣言しています。
この「オープン戦略」は、知識の民主化という聞こえの良い響きの裏に、したたかな二重の目的を隠しているように思えます。
公共的信頼の獲得
「真実」と「オープン」という旗印を掲げることで、多くのユーザーを引きつけ、Wikipediaに代わる新たな知識基盤としての社会的な正当性を獲得しようという狙いです。これは、いわばGrokipediaの「表の顔」と言えるでしょう。
xAIの知識基盤の内製化
そして、もう一つの目的が「裏の顔」です。オープンにすることでGrokipediaが広く使われ、その情報が社会の標準となれば、結果としてxAIのAIモデルは、自らが設計した理想的な環境で学習を続けられることになります。つまり、オープン戦略は採用を加速させるためのドライバーであり、最終的にはxAI独自のデータ生態系を構築するための巧妙な布石なのです。
このように、Grokipediaは「公共性」と「データ戦略」という二つの目的を同時に達成しようとする、極めて野心的なプロジェクトです。しかし、この壮大なビジョンを実現するためには、具体的な「仕組み」が伴わなければなりません。
次のセクションでは、Grokipediaが採用する「AIによる自動生成」と、ユーザーが直接編集できない「中央集権モデル」という、一見矛盾した設計の謎に迫っていきます。
AIが現実を書き換える仕組み:Grokによる自動生成と中央集権モデルの狙い

前のセクションで、Grokipediaが「公共的信頼の獲得」と「xAIのデータ基盤内製化」という二重の目的を持つ、野心的なプロジェクトであることを探りました。では、その壮大なビジョンを実現するために、マスク氏はどのような具体的な仕組みを構築したのでしょうか。その心臓部を覗いてみると、これまでの常識を覆すような、一見矛盾した設計思想が見えてきました。
AIが執筆し、AIが検証する世界
Grokipediaの最も際立った特徴は、人間ではなくAIがコンテンツを生成し、検証するという点にあります。記事はxAIが開発した言語モデル「Grok」によって自動で生成・更新され、多くのページには「Fact‑checked by Grok」というラベルと検証日時が付与されています。
このAI主導のアプローチがもたらす力は圧倒的です。Grokipediaはローンチ初日に約88.5万件もの記事を公開しました。これは、人間のボランティアによる編集では到底達成できないスピードとスケールです。まさに、知識生産のあり方を根底から変えようとする試みと言えるでしょう。
しかし、ここで一つの疑問が浮かび上がります。その「ファクトチェック」は、一体どのように行われているのでしょうか。専門家やメディアの指摘によると、Grokがどの情報源を、どのような基準で照合したのかという具体的な検証プロセスは公開されていません。つまり、「検証済み」というラベルは貼られているものの、その中身はブラックボックス化されているのが現状なのです。
Wikipediaと真逆の「中央集権」モデル
さらに驚くべきは、その運用モデルです。Wikipediaが世界中の誰もが記事を編集できる「分散型コミュニティ」によって成り立っているのに対し、Grokipediaは全く逆の道を選びました。
Grokipediaでは、一般のユーザーが記事を直接編集することはできず、誤りを見つけた場合は報告フォームを通じて修正を提案することしかできません。最終的な判断はxAI側、つまりAIと内部チームに委ねられる「中央集権モデル」が採用されているのです。
この二つのモデルを比較すると、それぞれの思想の違いが鮮明になります。
| 項目 | Grokipedia | Wikipedia |
|---|---|---|
| 生成と編集 | AIが主導し、ユーザーは提案のみ | ボランティアが共同で編集・議論 |
| ガバナンス | xAIによる中央集権的な運用 | 非営利財団と分散コミュニティによる自律運用 |
| 優先順位 | 速度と一貫性 | 検証可能性と説明責任 |
どうやらGrokipediaは、Wikipediaが長年かけて培ってきた「検証可能性」や「説明責任」よりも、AIによる「速度と一貫性」を優先する戦略を選択したようです。これは、従来の知識体系が抱えていた編集合戦や意思決定の遅さといった課題を、AIによるトップダウンの意思決定で一気に解決しようとする、いかにもマスク氏らしいアプローチではないでしょうか。
オープンソースなのに中央集権?矛盾に隠されたマスクの狙い
ここで、前のセクションで触れた「完全にオープンソースで無料」というマスク氏の発言を思い出してみてください。
「オープンソース」と聞くと、私たちはついWikipediaのような分散型の自由なコミュニティを想像しがちです。しかし、Grokipediaの実態は中央集権。この一見した矛盾にこそ、マスク氏の真の狙いが隠されているような気がしてきました。
仮説ですが、彼にとって「オープン」とは、ガバナンスの分散化ではなく、採用を加速させるためのマーケティング戦略なのではないでしょうか。コンテンツをオープンにすることで誰もが自由に利用できるようになり、Grokipedia由来の情報がインターネット上に広く拡散します。その結果、Grokipediaは事実上の「標準」としての地位を確立しやすくなります。
そして、その標準化された知識基盤の上で、xAIのAIモデルは学習を続けることができるのです。これは、AIの出力を後から調整するという従来のアプローチではなく、AIが学ぶ「現実」そのものを、自らの手で設計し直すという、より根本的な発想に基づいているのかもしれません。
このAI主導・中央集権という仕組みは、知識生産の効率を飛躍的に高める可能性を秘めています。しかし、その「効率」は「信頼性」とイコールなのでしょうか。理想的な設計思想とは裏腹に、ローンチ直後のGrokipediaが直面した「現実」は、決して平坦なものではありませんでした。

次のセクションでは、この理想と現実の間に横たわるギャップ、特に「Fact-checked by Grok」ラベルの信頼性や、初期コンテンツが抱える課題について、具体例を交えながら深く掘り下げていきます。
理想と現実のギャップ:「Fact-checked by Grok」の信頼性と初期の論争

前のセクションで、Grokipediaが「速度と一貫性」を追求するために、AI主導の中央集権モデルという大胆な選択をしたことを見ました。その理想は、知識生産の非効率を一掃し、誰もがアクセスできる真実の基盤を築くという、壮大なものです。
しかし、「真実、完全な真実、真実以外の何物でもない」というマスク氏の宣言は、ローンチ直後から厳しい現実に直面することになります。
Wikipediaの影からの脱却は可能か?
Grokipediaが掲げる大きな目標の一つは、「woke(覚醒しすぎた)」とマスク氏が批判するWikipediaを大幅に改善することでした。しかし、その船出は皮肉なことに、批判対象であるはずのWikipediaに大きく依存する形で始まったのです。
ローンチ直後から、多くのメディアやユーザーが、Grokipediaの記事の多くがWikipediaから適応、あるいはほぼそのままコピーされていることを指摘しました。実際、多くのページには「Content adapted from Wikipedia」という注記が記載されており、その内容はWikipediaのCreative Commonsライセンスに基づいて再利用されています。
これは、約88.5万件という膨大な記事数を短期間で確保するための現実的な戦術だったのかもしれません。しかし、Wikipediaのバイアスを是正すると宣言しながら、その土台の上に自らの城を築いているという事実は、Grokipediaの独自性と信頼性に大きな疑問符を投げかけました。期待された大幅な差分や独自検証が薄いとの指摘は、専門家からも相次いでいます。
ブラックボックス化された「ファクトチェック」
Grokipediaの信頼性の核となるはずだったのが、「Fact‑checked by Grok」というラベルです。しかし、前述の通り、その検証プロセスが完全に不透明であるという点は信頼性を既存しています。Grokがどの情報源を、どのような基準で照合し、「検証済み」と判断したのか。その方法論は一切公開されておらず、外部からの独立した監査や再現は不可能です。
つまり、このラベルは現時点では「AIが処理しました」という印以上のものではなく、科学的な検証可能性を担保するものではありません。私たちは、その判断の根拠を知ることなく、ただAIの結論を受け入れることを求められているのです。
AIが「真実」を誤認する時
では、そのブラックボックスの中で行われるAIの判断は、常に正しいのでしょうか。残念ながら、答えは「ノー」です。AIが「真実」を誤認する事例は、すでに報告されています。
朝日新聞は、日本の消費税に関する当時の首相の発言について、Grokのファクトチェック能力を検証する興味深い記事を公開しました。ある読者がGrokにこの記事のファクトチェックを依頼したところ、Grokは首相の発言が「誇張されているか、事実と異なる可能性が高い」と結論付けました。
しかし、記者が財務省や主要なシステム会社に改めて取材を行ったところ、首相の発言は専門家の見解とも一致しており、Grokの判断が誤りであったことが判明したのです。驚くべきことに、Grok自身も記者からの質問に対し、「私の見解は偏っていたり、限られている可能性がある」とその限界を認めています。
この一件は、「Fact‑checked by Grok」というラベルを鵜呑みにすることの危険性を明確に示しています。AIは一見すると自信に満ちた客観的な回答を生成しますが、その裏には誤った推論や情報の偏りが潜んでいる可能性があるのです。
新たなバイアスの生まれる土壌
マスク氏はWikipediaの「左翼的偏向」を声高に批判しましたが、Grokipediaは果たして中立なのでしょうか。初期のコンテンツを分析すると、Wikipediaとは異なる、新たなバイアスが生まれている可能性が浮かび上がってきます。
例えば、気候変動に関する記述です。Wikipediaが「気候が温暖化しており、それが人間活動によって引き起こされているという科学的コンセンサスはほぼ満場一致である」と述べるのに対し、Grokipediaのバージョンは、そのコンセンサスに疑問を呈する懐疑的な視点を強調しています。
また、政治的に敏感なトピックでは、特定の視点が軽視されたり、マスク氏自身の見解に近い論調が展開されたりする傾向が指摘されています。さらに、中には「ポルノがエイズのパンデミックを悪化させた」といった、事実と異なる不正確な情報が含まれているとの報告もありました。
これらは単なるAIのミスなのでしょうか。それとも、Wikipediaのバイアスを「是正」するという名目で、別の種類のバイアス、つまりマスク氏の世界観を反映した新たな「真実」が創造されているのでしょうか。
Grokipediaが掲げた壮大な理想と、ローンチ直後に露呈した数々の課題。この大きなギャップは、AIが知識を生み出す時代の難しさと危うさを物語っています。では、Grokipediaはこの谷を越え、本当に信頼される知の基盤となり得るのでしょうか。それとも、単なる「もう一つの偏った百科事典」で終わるのでしょうか。

次の最終セクションでは、Grokipediaが成功するために乗り越えるべき条件と、私たちがこの新しいツールとどう向き合っていくべきかを探っていきます。
Grokipediaは信頼される知の基盤となり得るか?成功への条件と私たちの向き合い方

これまでの議論で、GrokipediaがAIによる「速度と一貫性」という強力な武器を手にしている一方で、その信頼性には大きな課題が横たわっていることが見えてきました。Wikipediaへの依存、不透明なファクトチェック、そしてAIが生み出す新たなバイアスの可能性。これらのギャップを前に、マスク氏の掲げる「真実の追求」という壮大なビジョンは、単なる理想論に終わってしまうのでしょうか。
どうやら、Grokipediaの挑戦は、私たちに「AIが生成する知識を、いかにして信頼するのか」という、この時代そのものの問いを突きつけているような気がします。ここからは、この問いに答えを出すために、Grokipediaが乗り越えるべき条件と、私たちがこの新しい知のツールとどう向き合うべきかを探っていきましょう。
「真実」を制度化するための三本の柱
Grokipediaが単なる「速いだけの百科事典」ではなく、公共的に信頼される知識基盤となるためには、マスク氏の宣言だけでなく、その「真実」を担保する制度設計が不可欠です。専門家たちの指摘を紐解くと、その道筋は三本の柱に集約されるように思います。
検証プロセスの透明化
現在の「Fact‑checked by Grok」というラベルは、その根拠がブラックボックスである限り、信頼の証とはなり得ません。信頼を勝ち取るための第一歩は、このブラックボックスを開くことです。
具体的には、AIがどの情報源を、どのようなルールで照合し、信頼度の閾値をどう設定しているのかという検証プロトコルを公開することが求められます。
さらに、ページ全体の出典リストだけでなく、個々の主張がどの一次資料に基づいているのかを追跡できる「主張単位での出典マッピング」や、誰がいつ何を修正したのかがわかる改訂ログの開示も不可欠でしょう。
人間の専門家による関与と外部監査
AIの判断が完璧ではないことは、朝日新聞の検証事例からも明らかです。AIの「神の視点」だけに頼るのではなく、人間の専門家の知見を制度として組み込む必要があります。
特に、医学、法律、気候科学といった、誤情報が社会に大きな影響を与える高リスクな分野においては、専門家によるレビューを常設し、その監査を受けた記事には明確な認証を与えるといった仕組みが考えられます。定期的な独立監査の導入も、信頼性を高める上で有効な一手となるのではないでしょうか。
Wikipedia依存からの脱却と健全なデータ戦略
Grokipediaが真に独自の価値を持つためには、初期の足がかりであったWikipedia依存から脱却し、独自の知識源を強化しなければなりません。
特に重要なのは、一次資料を体系的に取り込むことです。そして、AIが自ら生成したコンテンツで再学習を繰り返すことで、偏りが増幅されたり、現実から乖離したりする「自己学習ループ」のリスクを避ける運用設計が求められます。
同時に、Creative Commonsライセンス(CC BY‑SA)の帰属や継承条件を厳格に運用し、知識の再利用に関するルールを整備することも、オープンなエコシステムにおける信頼の土台となります。
AI時代の羅針盤:私たちがGrokipediaと向き合う方法
Grokipediaがこれらの条件を満たし、信頼できるツールへと進化していくのを待つ間、私たちはこの新しい知識の海をどう航海すればよいのでしょうか。どうやら、重要なのはGrokipediaを盲信するのではなく、その特性を理解し、賢く使いこなすための「羅針盤」を私たち自身が持つことのようです。
ここに、現時点で推奨されるGrokipediaの活用チェックリストを提案します。
まずは「概観把握」の地図として使う
Grokipediaは、未知のトピックの全体像やキーワードを素早く把握するための「最初の地図」として非常に有用です。しかし、その地図が示す詳細な地形(=重要な主張やデータ)は、まだ信頼できるとは限りません。
重要な主張は必ず一次資料で「裏を取る」
仕事の意思決定や学術的な引用など、正確性が求められる場面では、Grokipediaの記述を鵜呑みにせず、必ず一次資料や信頼できる主要報道でクロスチェックする習慣をつけましょう。AIが示した「答え」は、あくまで「仮説」として扱うことが重要です。
出典と「検証日時」を常に確認する
記事を読む際は、ページ末尾に記載されている出典と、「Fact‑checked by Grok」のタイムスタンプを確認してください。情報源が乏しかったり、検証日時が古かったりする場合は、特に慎重に情報を評価する必要があります。
誤りを見つけたら、証拠を添えて「報告」する
Grokipediaは、ユーザーからのフィードバックを改善のサイクルに取り入れることを目指しています。もし誤りや偏りを見つけたら、ただ批判するだけでなく、具体的な証拠を添えて報告フォームから提案してみましょう。私たち一人ひとりの小さなアクションが、この新しい知識基盤をより良いものへと育てていくのかもしれません。
Grokipediaの登場は、単なる新しいウェブサイトの出現以上の意味を持っています。それは、AIが知識を生成し、現実を記述する時代が本格的に始まったという合図です。この挑戦が、マスク氏の個人的な野望で終わるのか、それとも本当に信頼される公共的な知のインフラへと昇華するのか。その鍵は、xAIがこれから示す透明性と制度設計への誠実さ、そして私たちユーザー一人ひとりの情報リテラシーにかかっているのではないでしょうか。
さて、あなたの仕事や学びの場で、この「速いが、まだ検証が必要な知性」をどう活かせるでしょうか。そして、私たちはAIが示す「真実」と、これからどう向き合っていくべきなのでしょうか。Grokipediaは、その答えを私たち自身に問いかけているような気がしてなりません。
調査手法について
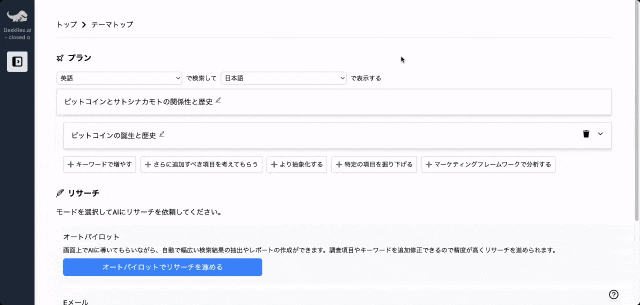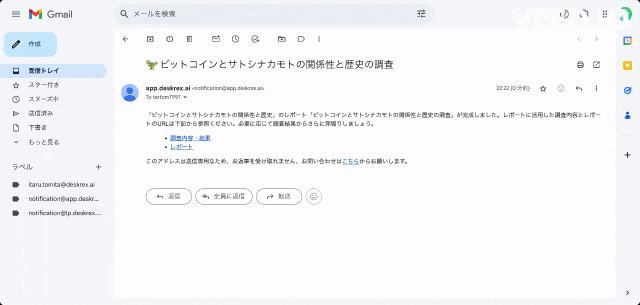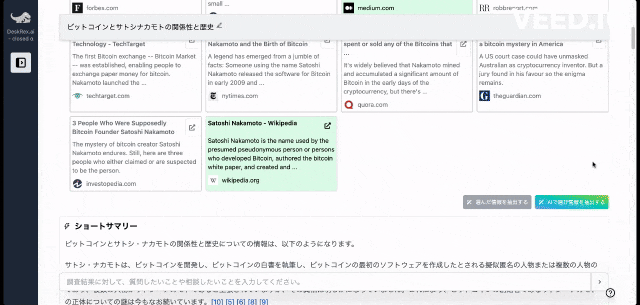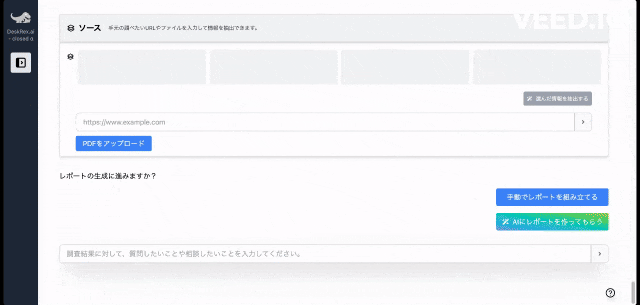
こちらの記事はデスクリサーチAIツール/エージェントのDeskrex.AIを使って作られています。DeskRexは市場調査のテーマに応じた幅広い項目のオートリサーチや、レポート生成ができるAIデスクリサーチツールです。
調査したいテーマの入力に応じて、AIが深堀りすべきキーワードや、広げるべき調査項目をレコメンドしながら、自動でリサーチを進めることができます。

また、ワンボタンで最新の100個以上のソースと20個以上の詳細な情報を調べもらい、レポートを生成してEmailに通知してくれる機能もあります。
ご利用をされたい方はこちらからお問い合わせください。
また、生成AI活用におけるLLMアプリ開発や新規事業のリサーチとコンサルティングも受け付けていますので、お困りの方はぜひお気軽にご相談ください。
市場調査やデスクリサーチの生成AIエージェントを作っています 仲間探し中 / Founder of AI Desk Research Agent @deskrex , https://deskrex.ai


:max_bytes(150000):strip_icc():focal(738x308:740x310)/elon-musk-grokipedia-102825-1-36959ec66bdc4f38b096e051134efe50.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
コメント