
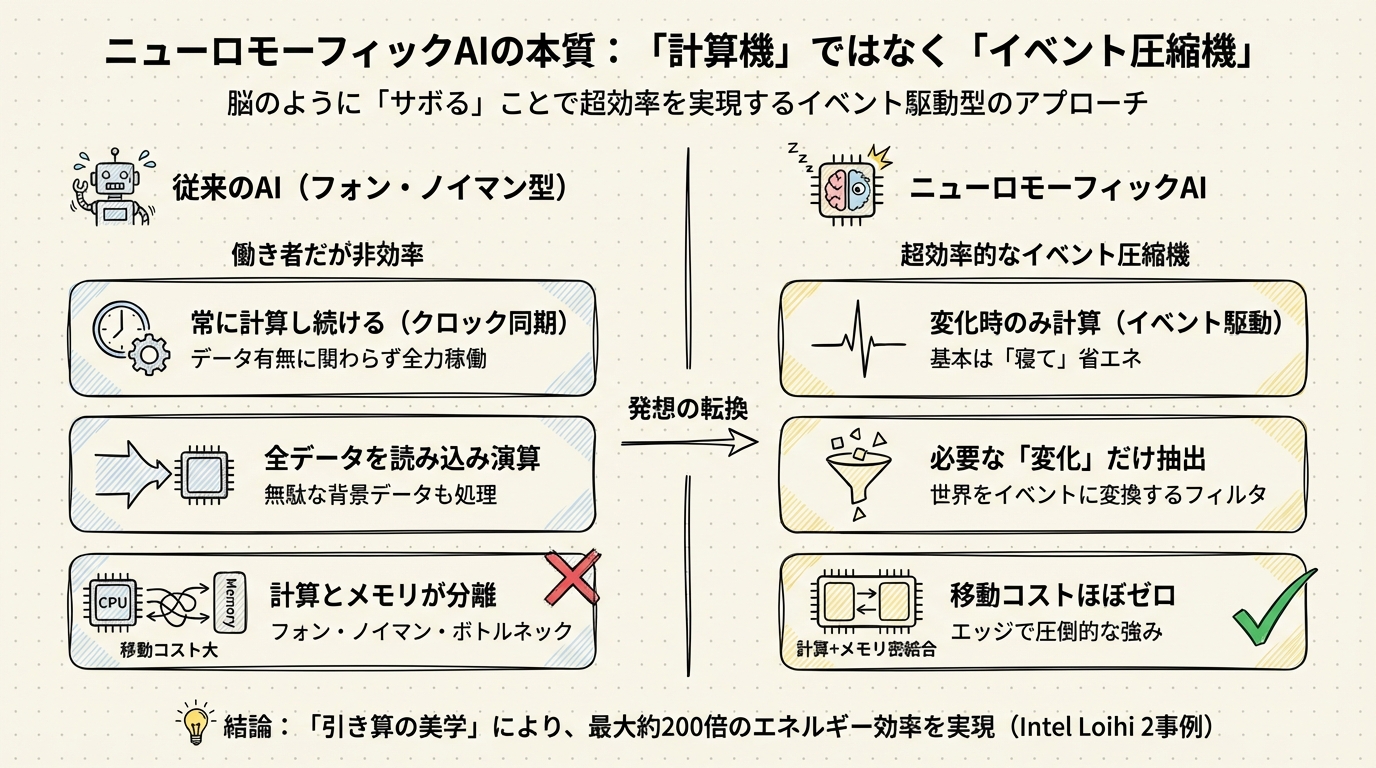
定義の再考:ニューロモーフィックAIは「計算機」ではなく「超効率的なイベント圧縮機」である
「ニューロモーフィックAI」と聞いたとき、皆さんは何を思い浮かべるでしょうか。「人間の脳を模倣したAI」という説明をよく耳にします。確かに定義としては正しいのですが、どうやらこの言葉だけでは、この技術の本当の凄みを見落としてしまいそうな気がしてなりません。
私が最近、様々な文献や事例を調べていて強く感じたのは、この技術の本質は「脳のように考えること」よりも、むしろ「脳のようにサボること」にあるのではないか、という点です。もう少しエンジニアリング寄りの言葉で言えば、ニューロモーフィックAIとは、高性能な計算機というよりも、世界からやってくる膨大な情報を限界まで絞り込む「超効率的なイベント圧縮機」と呼ぶほうがしっくりくるのです。
「計算しない」という最大の機能
従来のAI(ディープラーニングなど)を動かすGPUやTPUは、ある意味で「働き者」です。カメラが真っ暗な部屋を映していても、あるいは誰もいない廊下を映していても、彼らは全力で画像データを読み込み、行列演算を繰り返します。データが何であれ、決まったクロックサイクルで計算し続ける。これがフォン・ノイマン型と呼ばれる従来のコンピュータの宿命でした。
一方で、ニューロモーフィックAIのアプローチは根本的に異なります。彼らは基本的には「寝て」います。
ニューロモーフィックAIが採用している「イベント駆動(Event-Driven)」という仕組みは、入力に変化があったときだけ、パルス状の信号(スパイク)を出して計算を開始します。例えば、監視カメラなら「人が通った瞬間」だけ、マイクなら「音がした瞬間」だけ回路が動くわけです。
これは、何もしない時間の消費電力を極限まで下げることを意味します。実際、Intelの研究用チップであるLoihi 2を用いた実験では、特定のタスクにおいて従来の小型AIコンピュータ(NVIDIA Jetson Orin Nano)と比較して、約200倍も少ないエネルギーで処理できたという報告があります。2倍や3倍ではなく、200倍です。これは単なる効率化のレベルを超えて、全く別のルールで動いていると考えたほうがよさそうです。
フォン・ノイマンの呪縛を解く
なぜこれほどまでに効率が違うのでしょうか。理由の一つに、データ移動のコストがあります。
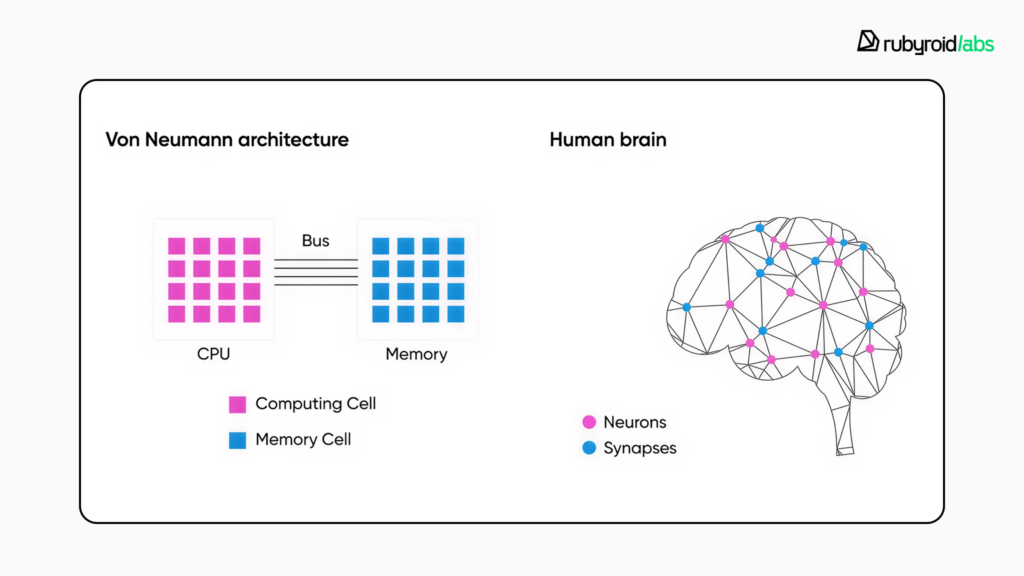
私たちが普段使っているコンピュータは、計算する場所(CPUやGPU)と記憶する場所(メモリ)が分かれています。料理に例えるなら、まな板(CPU)と冷蔵庫(メモリ)が離れた場所にあるようなものです。食材を取りに行くたびに往復する時間がかかり、無駄な体力を使います。これを専門用語で「フォン・ノイマン・ボトルネック」と呼びます。特にAIのような大量のデータを扱う処理では、計算そのものよりも、このデータの移動に多くのエネルギーが費やされていることが知られています。
ニューロモーフィックAIは、この構造を破壊します。脳のニューロンとシナプスがそうであるように、計算する場所と記憶する場所を極限まで近づけ、あるいは一体化させています。まな板と冷蔵庫が合体したようなキッチンで料理をするようなものでしょうか。これなら、移動のコストはほぼゼロになります。
この「メモリと計算の密結合」こそが、エッジデバイス(スマホやセンサーなど、現場で動く機器)において圧倒的な強みを発揮する理由です。クラウドにデータを送る必要もなく、その場で瞬時に、最小限のエネルギーで処理を完結できるからです。
世界を「イベント」に変換するフィルタ
このように考えると、ニューロモーフィックAIの役割が見えてきます。それは、アナログで連続的な現実世界の中から、「変化」という名のイベントだけを抽出してデジタル信号に変える、高度なフィルタとしての役割です。
例えば、Propheseeというスタートアップが開発しているイベントベースのカメラセンサーは、フレーム(静止画の連続)を撮影するのではなく、光の強度が変化した画素だけを記録します。背景が止まっていてボールだけが動いているなら、ボールの動きだけがデータとして出力されます。無駄な背景データは最初から捨ててしまうのです。
結果として、データ量は劇的に減り、必要な情報(イベント)だけが後段のAIに送られます。これが冒頭で私が「超効率的なイベント圧縮機」と呼んだ理由です。
計算能力を誇るのではなく、いかに計算せずに済ませるか。いかにデータを捨てて、本質的な変化だけを捕まえるか。どうやら、ニューロモーフィックAIの本質はこの「引き算の美学」にありそうです。
では、この「サボる技術」を実現するために、研究者たちは具体的にどのようなアプローチをとっているのでしょうか。実は最近の研究では、単にハードウェアを脳に似せるだけでなく、「時間」そのものをデザインするという面白い変化が起きているようです。次のセクションで詳しく見ていきましょう。
研究最前線:AIの進化は「重みの精度」から「時間のデザイン」へシフトしている

前章で、ニューロモーフィックAIは「計算しないこと」に価値があるという話をしました。しかし、実際にどうやって「計算せずに賢く振る舞うのか」を突き詰めていくと、どうやら研究者たちは「重み(Weight)」よりも「時間(Time)」を操ることに活路を見出しているようなのです。
一般的にAIの進化といえば、パラメータ(重み)をいかに増やし、いかに精密に計算するかが焦点になりがちです。しかし、最新のニューロモーフィック研究を眺めていると、全く逆のアプローチが成果を出し始めていることに気づきました。それは、計算の精密さを捨ててでも、「信号がいつ届くか」というタイミングの調整に全力を注ぐというパラダイムシフトです。
本章では、この「時間をデザインする」という考え方が、なぜ低スペックなハードウェアでも劇的な性能向上をもたらすのか、具体的な研究データを交えて解説します。これを知っておくと、将来エッジAIを設計する際、高価なチップに頼らずに性能を引き出すための重要なヒントになるはずです。
粗い脳でも「タイミング」が合えば賢くなる

私たちが普段使っているAI(ディープラーニング)は、ニューロン同士のつながりの強さ、つまり「重み」を細かく調整することで学習します。この重みは通常、32ビットや16ビットといった細かい数値で表現されます。しかし、エッジデバイスのような制約の多い環境では、メモリを節約するためにこの数値を粗くする(量子化する)必要があります。例えば、重みを「-1, 0, 1」の3種類だけにしてしまうような極端な圧縮です。当然、そのままではAIはバカになってしまいます。
ところが、最近の研究で面白いことが分かってきました。重みがスカスカでも、「信号が伝わる遅延時間」さえ学習させれば、AIは賢さを取り戻せるというのです。
ここで登場するのがSNN(スパイクニューラルネットワーク)という仕組みです。普通のニューラルネットワーク(ANN)を水道管に例えるなら、蛇口をひねっている間ずっと水が流れ続けているようなイメージです。流れる水の量(数値の大きさ)で情報を伝えます。一方、SNNはまったく違います。こちらはモールス信号のように、「パチッ」という短い合図を送るか送らないか、そしてそれをいつ送るかで情報を伝えるのです。
SNNのニューロンは、私たちの脳の神経細胞によく似た動き方をします。入力を受け取るたびに、まるでコップに水を少しずつ注いでいくように、内部にエネルギーをためていきます。そしてコップから水があふれる瞬間、つまりある一定のラインを超えた瞬間にだけ、「スパイク」と呼ばれる短いパルス信号を一発だけ打ち出します。次のニューロンはこのスパイクを受け取ったときにだけ反応するので、信号が常に流れているわけではなく、必要なときにだけピッピッと情報が飛び交う世界なのです。
この仕組みで面白いのは、単に「スパイクが出たか出なかったか」だけが情報ではないという点です。たとえば、1秒間に何回スパイクが出たかという頻度も情報になりますし、スパイクがいつ出たかというタイミングそのものも情報になります。同じ入力を受けても、どのニューロンが、どんな順番で、どれくらいの間隔で発火したかによって、ネットワーク全体が受け取る意味が変わってしまうのです。普通のニューラルネットワークが「つながりの強さ」だけで賢くなるとすれば、SNNは「つながりの強さ」に加えて「時間のパターン」も使って賢くなるタイプのモデルだと言えます。
2025年の計算論的神経科学会議(CCN)で発表された研究によると、音声認識タスク(SHDデータセット)において、重みを極端に粗くした(量子化された)SNNの精度は、最初は44.41%しかありませんでした。使い物になりませんね。しかし、ここに「学習可能遅延(Learnable Delays)」という仕組みを導入し、ニューロンからニューロンへ信号が伝わる時間を個別に調整できるようにしたところ、精度が一気に89.92%まで回復したのです。さらに、短い遅延を無視する閾値メカニズムを加えると90.68%に達しました。
これは何を意味しているのでしょうか。
私はこれを音楽の演奏に例えると分かりやすいのではないかと思います。たとえ楽器の音量調節(重み)が大雑把で強弱がつけられなくても、音を鳴らすタイミング(時間)さえ完璧にコントロールできれば、素晴らしいリズムとメロディが生まれるようなものです。
どうやら、ニューロモーフィックAIの世界では、空間的なリソース(メモリや回路規模)の不足を、時間的な表現力で補うことができるようです。この「時間のデザイン」こそが、安価で省電力なチップでも高度な処理を実現する鍵になる気がしてきました。
GPUで学び、専用チップで走る
「SNN(スパイクニューラルネットワーク)は省電力だけど、学習させるのが難しい」。これは長らくこの分野の課題でした。SNNの挙動は複雑すぎて、既存のAI学習手法(バックプロパゲーション)がそのままでは使えなかったのです。
しかし、この壁も崩れつつあります。最近の研究では、GPU上でSNNを効率的に学習させ、それをそのままニューロモーフィックチップに移植するパイプラインが確立され始めています。
その代表例が、Intelの研究チームなどが発表した「Eventprop」という手法です。彼らはこの手法を使って学習させたモデルを、Intelの最新ニューロモーフィックチップであるLoihi 2に実装し、従来のエッジ向けAIコンピュータ(NVIDIA Jetson Orin Nano)と性能を比較しました。
その結果は驚くべきものでした。キーワードスポッティング(特定の単語を聞き取るタスク)において、Loihi 2はJetson Orin Nanoと比較して、最大で約10倍高速(遅延2.33ms vs 25.5ms)に処理し、消費エネルギーは約200倍も少なかった(0.19mJ vs 82.3mJ)というのです。
ここで重要なのは、「200倍省エネ」という数字だけではありません。「GPUで学習して専用チップで動かす」という、私たちが普段AI開発で行っているワークフロー(学習→推論)が、ニューロモーフィックの世界でも当たり前にできるようになってきたという事実です。これは、この技術が研究室を出て、製品開発の現場に入り込み始めている証拠ではないでしょうか。
わずかな「注意」で効率を最大化する
さらに、人間の脳が持つ「注意(Attention)」の仕組みをSNNに取り入れる動きもあります。
私たち人間は、視界に入ったものすべてを同じ解像度で処理しているわけではありません。重要な部分にだけ「注意」を向け、リソースを集中させています。これをSNNに応用した「BIASNN」という研究では、わずか4回のタイムステップ(時間の刻み)で、画像分類タスク(CIFAR-10)において94.22%という高精度を達成しました。
従来のSNNが精度を出すために何十、何百回ものタイムステップを必要としていたことを考えると、これは劇的な効率化です。「時間をかける」のではなく、「重要な時間の使い方をする」ことで、さらに処理を軽くできるわけです。
こうして研究の最前線を追っていくと、AIの進化の方向性は一つではないことに気づかされます。巨大な計算リソースで力技で解くAIもあれば、時間という次元を巧みに操ることで、最小限のリソースで最大の効果を狙うAIもある。そして後者は、バッテリーやスペースに制約のあるエッジデバイスにとって、まさに救世主となり得る技術です。
では、こうした「時間を味方につけた技術」を使って、実際にどのようなビジネスが生まれようとしているのでしょうか? 次のセクションでは、汎用チップではなく「センサー」との統合で市場を切り開くスタートアップたちの勝ち筋に迫ります。
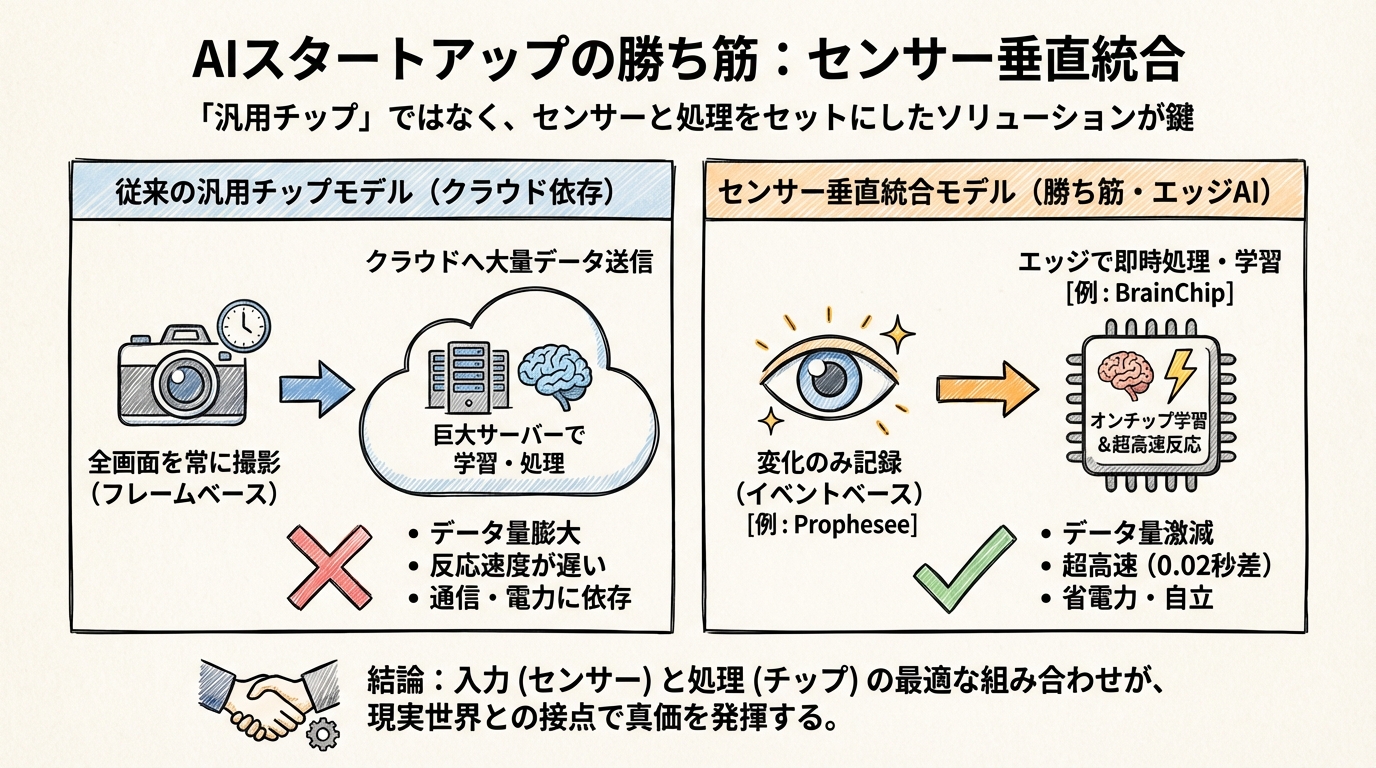
スタートアップの勝ち筋:「汎用チップ」ではなく「センサー垂直統合」が市場を切り開く
前の章で、AIの進化が「重みの精度」から「時間のデザイン」へシフトしているという話をしました。では、この技術を使ってビジネスの世界で勝負しようとしているスタートアップたちは、実際にどのような戦略をとっているのでしょうか。
正直なところ、私は最初、少し懐疑的でした。「省電力なAIチップを作りました」と言うだけで、あのNVIDIAのような巨人が支配する汎用チップ市場で戦えるのだろうか? と。しかし、成功しつつある企業の動きを追っていくと、どうやら彼らは全く別のゲームをプレイしているようなのです。

彼らの勝ち筋は、「何でもできる汎用チップ」を売ることではなく、「センサーと処理をセットにした垂直統合ソリューション」を提供することにありました。
「目」の仕組みを再発明する
その最も分かりやすい例が、フランスのスタートアップ、前述のProphesee(プロフェシー)です。彼らが作っているのは単なるチップではなく、「イベントベースビジョンセンサー」という新しいタイプの「目」です。
私たちが普段使っているカメラやスマホは、パラパラ漫画のように1秒間に30回や60回、画面全体の写真を撮り続けています。何も動いていなくても、背景の壁まで毎回撮影してデータを送るわけです。これでは無駄が多すぎますよね。
一方、Propheseeのセンサーは、「変化があった画素(ピクセル)だけ」を記録します。誰かが動いたとか、光が点滅したといった「イベント」が起きた瞬間、その部分だけが反応するのです。これはまさに、私たち生物の網膜の動きそのものです。
この仕組みに変えると何が起こるでしょうか。データ量が劇的に減るのはもちろんですが、反応速度が桁違いに速くなります。実際、Propheseeのセンサーとソニーのチップを組み合わせたシステムは、従来のカメラよりも20ミリ秒(0.02秒)も速く歩行者を検出できるという報告があります。
たった0.02秒と思うかもしれませんが、時速60kmで走る車にとっては制動距離が数十センチ変わる決定的な差です。彼らは「AIチップ」を売っているというより、「事故を防ぐための超高速な目」というソリューションを売っているわけですね。
センサーの隣で「賢く」なる
もう一つの面白い事例が、オーストラリア発のBrainChip(ブレインチップ)です。彼らの開発するプロセッサ「Akida」は、センサーのすぐそば(エッジ)で動くことに特化しています。
通常、AIを賢くしようと思ったら、データを大量にクラウドに送って、巨大なサーバーで学習させる必要があります。しかし、Akidaは「オンチップ学習」といって、その場で学習することができます。
例えば、工場の機械に取り付けた振動センサーを想像してください。クラウドにデータを送り続けなくても、Akidaはその場で「いつもの振動」を覚え、そこから外れた「異常な振動」を検知した瞬間にアラートを出せます。しかも、その処理に必要な電力はごくわずかです。
この「センサーの直後でデータを間引き、意味のある情報に変えてしまう」能力が評価され、メルセデス・ベンツやNASAといった組織がパートナーとして名を連ねています。宇宙空間のような、通信も電力も限られた極限環境では、クラウドに頼れない「自立した賢さ」こそが求められるからです。
なぜ「セット」だと強いのか?
PropheseeやBrainChipの事例を見ていて気づいたのは、「入力(センサー)」と「処理(チップ)」の相性が極めて重要だということです。
もし、Propheseeのような「変化しか送ってこない(スパースな)センサー」のデータを、従来のGPUのような「行列計算が得意なチップ」で処理しようとしたらどうなるでしょうか? おそらく、データ形式を変換する手間が発生して、せっかくの速さが台無しになってしまいます。
- 入力: 変化があった時だけデータが来る(イベント駆動)
- 処理: データが来た時だけ計算する(ニューロモーフィックAI)
この2つが垂直統合(セット)で組み合わさって初めて、真価が発揮されるのです。SynSenseという企業も、ロボット向けにサブミリ秒(0.001秒未満)の遅延で反応するチップを提供していますがembedUR、これもセンサーと処理を密接に連携させているからこそ実現できる性能でしょう。
あなたの現場の「センサー」は何ですか?
こう考えると、ニューロモーフィックAIの市場は、「PCの中」や「サーバー室」ではなく、「現実世界との接点」に広がっていることが分かります。
汎用的なAIチップが「脳みそ」だとしたら、ニューロモーフィックAIは「反射神経」や「感覚器」に近い存在と言えるかもしれません。熱いものに触れた瞬間、脳で考える前に手を引っ込めるような、あの速さと省エネ性です。
さて、あなたの業界や現場には、どんな「センサー」があるでしょうか?
防犯カメラ、マイク、温度計、あるいは工場のラインセンサー。それらのデータは今、無駄にクラウドへ送られていませんか? もしそのセンサーのすぐ隣に、わずかな電力で動き、必要な時だけ即座に反応する「小さな脳」があったら、どんな新しい価値が生まれるでしょうか。
次の最終章では、これまで見てきた技術や事例を踏まえて、私たちがこの技術をどう導入し、GPUのような既存のAIとどう共存させていくべきか、現実的なロードマップを考えてみたいと思います。
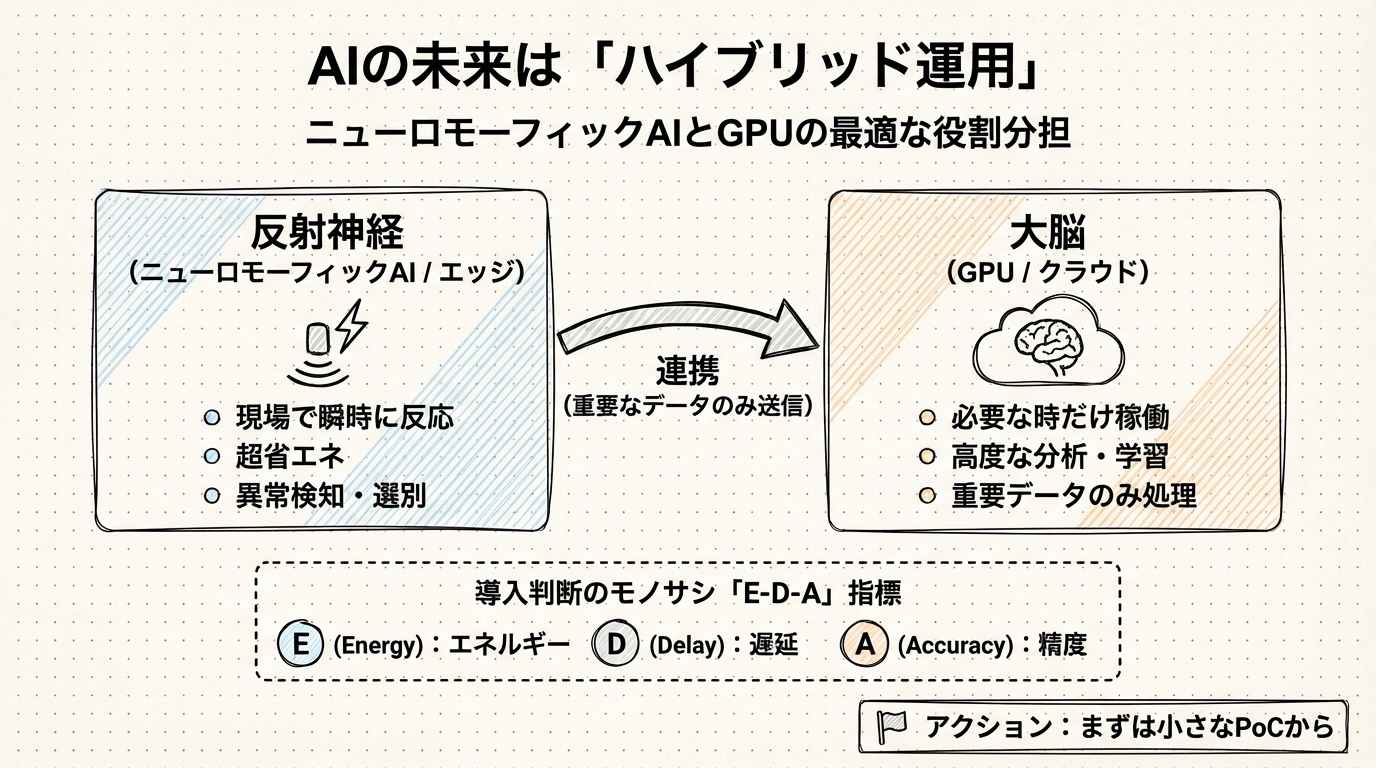
導入判断と未来予測:GPUとの「ハイブリッド運用」こそが現実的な解である
ここまで、ニューロモーフィックAIの驚くべき省エネ性能や、スタートアップたちの「センサー垂直統合」という賢い戦略を見てきました。これらを読んでいると、「これからは全てのAIが脳型チップに置き換わり、GPU(現在のAI計算の主役)は役目を終える」ような気がしてくるかもしれません。
しかし、色々な資料や事例を深掘りしていくと、どうやら未来は「完全な置き換え」ではなく、「適材適所のチームプレー」に向かっていくようです。
この最後のセクションでは、私たちがこの新しい技術とどう付き合い、どう導入を判断すべきか、現実的なロードマップと具体的な基準について考えてみたいと思います。
「反射神経」と「大脳」の役割分担
突然ですが、熱いヤカンに手が触れてしまった時を想像してみてください。あなたは「あ、これは熱いな。火傷をする恐れがあるから手を引こう」と頭で考えてから手を動かすでしょうか?
違いますよね。熱いと感じた瞬間に、脊髄反射で手を引っ込めているはずです。そして安全を確保した後で初めて、脳で「今の熱かったな、気をつけよう」と認識します。
実は、これからのAIシステムも、これと同じような構造になっていくと考えられます。
- 反射神経(ニューロモーフィックAI): 現場の最前線(エッジ)にいて、常に目を光らせている。普段はほとんど電力を使わず、何か異常があった時だけ瞬時に反応し、簡単な処理やデータの選別を行う。
- 大脳(GPU / クラウド): 後ろに控えていて、普段は休んでいるか別の仕事をしている。「反射神経」から「これは詳しく調べる必要がある」と送られてきた重要なデータだけを受け取り、高度な分析や学習を行う。
これが「ハイブリッド運用」と呼ばれる考え方です。
例えば、山奥のダムを監視するカメラを考えてみましょう。24時間365日、高画質な映像をクラウドのGPUに送り続けて解析させるのは、通信費も電気代も莫大になり、現実的ではありません。
そこで、カメラの側にニューロモーフィックチップ(SNN)を置きます。SNNは普段、水面のさざ波や揺れる木々といった「どうでもいい変化」を無視し続け、電力をほとんど使いません。しかし、万が一「亀裂が入った」「落石があった」といった異常なイベント(スパイク)が発生した瞬間、即座に反応してアラートを出し、その瞬間の映像だけをクラウドのGPUへ送るのです。
これなら、GPUは本当に必要な時だけ全力で働けばよく、システム全体としては驚くほど効率的になります。ニューロモーフィックAIはGPUの敵ではなく、GPUの負担を減らす最高のパートナーになるわけです。
研究や導入を判断する「E-D-A」の3つのモノサシ
では、企業が実際に「うちの現場にもニューロモーフィックAIを研究すべきか?はたまた今後に入れるべきか?」を検討する際、何を基準にすればよいのでしょうか。
多くの人は、AIを選ぶときに「精度(Accuracy)」ばかりを見てしまいがちです。「GPUなら正解率99%だけど、SNNは95%か。じゃあGPUだね」と。でも、これでは判断を誤ってしまう可能性があります。
研究の開始や導入の成否を分けるのは、精度を含めた次の3つのバランス、名付けて「E-D-A」指標です。
- Energy(エネルギー): その処理にどれだけ電力を使うか?
- Delay(遅延): 反応するのにどれだけ時間がかかるか?
- Accuracy(精度): どれだけ正確に判断できるか?
具体例を見てみましょう。Intelの研究チームが行った音声キーワード認識の実験では、ニューロモーフィックチップ「Loihi 2」と、小型のGPUコンピュータ「Jetson Orin Nano」を比較しました。
その結果、Loihi 2はGPUと比べて最大約10倍も反応が速く(Delay)、消費エネルギーは約200分の1で済んだ(Energy)というのです。
もしあなたが「スマートスピーカーのウェイクワード(OK, 〇〇と呼びかける機能)」を作っているとしたらどうでしょう。精度がGPUとほぼ同じなら、電池持ちが200倍良くて、話しかけた瞬間に反応してくれる方を選びたいと思いませんか?
逆に、精度が命の「医療画像診断」で、電源に繋ぎっぱなしで使える環境なら、迷わずGPUを選ぶべきです。
つまり、「E(エネルギー)」や「D(遅延)」の制約が厳しい現場こそが、ニューロモーフィックAIの出番なのです。
まずは「小さく」始める研究やPoCに備える
しかし、技術はまだまだ発展途上で、使いこなすためのツールやノウハウもこれから整備されていく段階です。
今後、「小さな研究やPoC(実証実験)」から始められるようになった場合は、次のポイントを注意すると良いでしょう。
- 現場を探す: 「電池交換が面倒」「反応が遅くて困る」「通信環境が悪い」といった悩みがある場所を探す。
- E-D-Aを決める: 「精度は今の9割でいいから、電池を1ヶ月持たせたい(Energy優先)」といった目標値を設定する。
- 試してみる: BrainChipやPropheseeなどが提供している開発キットを使って、実際に動かしてみる。
幸いなことに、最近の研究では「Eventprop」のような新しい学習手法が登場し、GPUで学習させたモデルをスムーズにニューロモーフィックチップへ載せ替える道筋も見えてきました。まずは手元のGPUで試作し、手応えがあったら専用チップに移す、という進め方もできるようになっています。
私たちはこれまで、コンピュータの性能を上げるために「より速く、より大量に」計算することばかり考えてきました。しかし、ニューロモーフィックAIが教えてくれるのは、「必要な時だけ、必要なことだけをする」という生物らしい賢さの重要性です。
すべてをクラウドに吸い上げて巨大なAIで処理するのではなく、現場のエッジで賢く間引いて、本当に大切なことだけを深く考える。そんな「人間らしい」役割分担ができるようになった時、AIは単なる計算機を超えて、私たちの生活にもっと自然に溶け込んでいくのではないでしょうか。
あなたの周りにも、無駄に電気を使い続けている「働きすぎなセンサー」はいませんか?もしかしたらそこが、この新しい知能を宿す最初の場所かもしれません。
調査手法について
こちらの記事はデスクリサーチAIツール/エージェントのDeskrex.AIを使って作られています。DeskRexは市場調査のテーマに応じた幅広い項目のオートリサーチや、レポート生成ができるAIデスクリサーチツールです。
調査したいテーマの入力に応じて、AIが深堀りすべきキーワードや、広げるべき調査項目をレコメンドしながら、自動でリサーチを進めることができます。

また、ワンボタンで最新の100個以上のソースと20個以上の詳細な情報を調べもらい、レポートを生成してEmailに通知してくれる機能もあります。
ご利用をされたい方はこちらからお問い合わせください。
また、生成AI活用におけるLLMアプリ開発や新規事業のリサーチとコンサルティングも受け付けていますので、お困りの方はぜひお気軽にご相談ください。
市場調査やデスクリサーチの生成AIエージェントを作っています 仲間探し中 / Founder of AI Desk Research Agent @deskrex , https://deskrex.ai


コメント