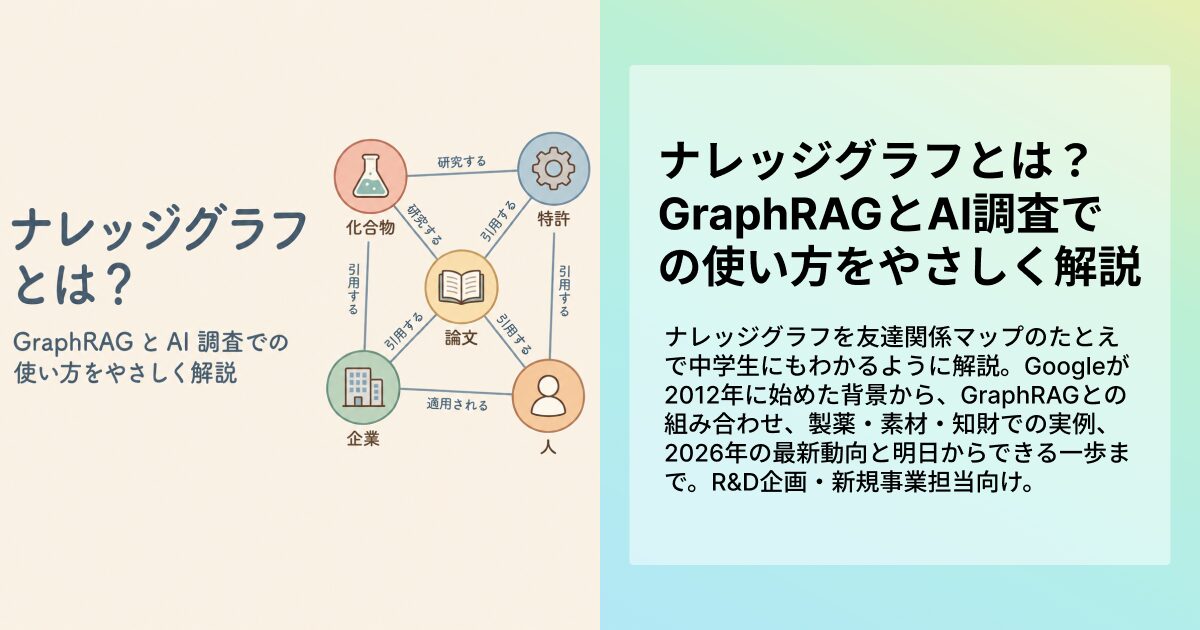
ナレッジグラフってそもそも何ですか?友達関係マップで考える
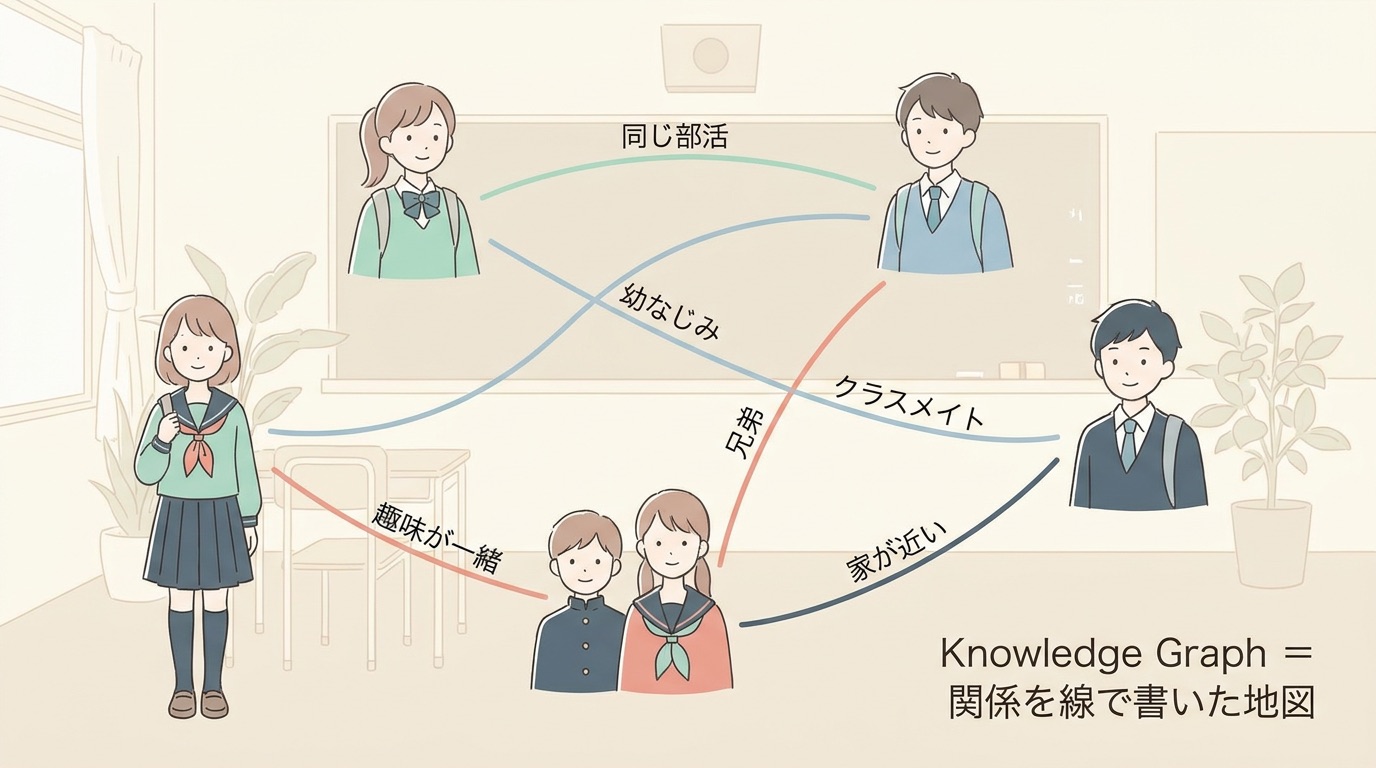
ナレッジグラフという言葉を聞くと、なんとなく「Googleがやってる難しいやつ」というイメージがありませんか。実は、本質はもっと身近です。ひと言でいえば、ナレッジグラフは「物事を点、関係を線で書いた巨大な友達関係マップ」です。
たとえばクラスの友達関係を地図にすると、太郎くんと花子さんが「同じ部活」でつながり、花子さんと健くんが「幼なじみ」でつながる、というふうに描けます。これをモノや会社、論文、特許、化合物といった世の中のあらゆるものに広げたのがナレッジグラフです。NTTの解説でも、ナレッジグラフは「さまざまな知識を体系的に連結し、グラフ構造で表した知識のネットワーク」と説明されています。
きっかけはGoogleの一言、「文字じゃなく、モノを検索する」
世界的にこの言葉が広まったのは、2012年にGoogleが検索を進化させたときです。Googleは「things, not strings」というキャッチフレーズで、検索を「文字列の一致」から「モノそのものを理解する」方向へ変えると宣言しました。みなさんが「東京タワー」と検索したときに、右側に高さや住所が並ぶパネルが出てきますよね。あれを動かしているのがGoogleのナレッジグラフです。
スケール感も少し触れておきます。Googleが扱う知識は、NTTの整理だと2020年時点で「エンティティが約50億以上、事実情報は5,000億以上」とされています。ピンと来ない数字ですが、地球上のすべての人類の60倍以上の「点」をGoogleが知っている、と思うとイメージしやすいかもしれません。
でも本当の主役は「線」のほうです
ここで一回、立ち止まりたいです。多くの入門記事は「点と線で書いた図」で説明を終えるのですが、これだとちょっと弱いです。実際の現場で価値を生んでいるのは、点の数ではなく、「線にどんな意味のラベルが付いているか」のほうだからです。
たとえば「太郎と花子はつながっています」だけだと情報がうすいですよね。でも「太郎は花子と同じ部活で、毎週火曜に練習している」となれば、ぐっと使える情報になります。ナレッジグラフも同じで、IBMはこの仕組みを「ノード、エッジ、ラベル」の3つで構成されると説明しています。ノードは点、エッジは線、ラベルはその線の意味、というわけです。
製薬の研究を例にすると、「化合物Aは標的タンパク質Bにくっつく」「論文CでAが報告されている」「特許DでAが守られている」という3本の線をつなぐと、「この化合物は誰かに先に取られているのか、まだ空いているのか」が一目でわかります。これは単に文書を検索しても出てこない情報です。
「Googleの機能」じゃなくて「LLMの相棒」になりつつある
ここからが、2026年の今、改めて押さえておきたいポイントです。ナレッジグラフは、もうGoogleの検索画面だけの話ではありません。いま流行りの生成AIやAIエージェント、たとえばChatGPTやClaudeのようなサービスを、もっと業務で使えるものにする「相棒」のような部品として再注目されています。
Google Cloud自身も、グラフを使った検索手法である「GraphRAG」を、「ベクトル検索とナレッジグラフ クエリを組み合わせることで、相互接続性をより適切に反映するコンテキストデータを取得するアプローチ」と説明しています。少しむずかしい表現ですが、要するに「LLMにただ文書を渡すだけじゃなく、関係のつながりまで一緒に渡してあげる」仕組みのことです。
実際、パナソニック コネクトはAI業務活用の実装事例として、「RAGの参照先にナレッジグラフを使って回答の速度と精度を上げる方法と、AIエージェントが自律的な質疑応答を繰り返して不要な情報を減らす方法」を組み合わせたと発表しました。文書検索の上にナレッジグラフがあると、AIの答えがしっかりした根拠と一緒に返ってくるようになる、ということです。
「家系図」より「特捜本部の人物相関図」に近いです
たとえとしてもう一つ追加させてください。家系図は親子関係しか描けません。でもナレッジグラフは、「同じ会社」「同じ研究テーマ」「同じ規制対象」「過去に共同研究した」「特許で引用した」と、何種類もの線を描けます。これはちょうど、刑事ドラマの特捜本部に張ってある人物相関図に似ています。誰と誰がどうつながっていて、誰がカギを握っているか。それをコンピュータが見える形にしたもの、と思ってください。
R&Dや新規事業の現場では、この「線の種類の豊かさ」が事業価値を作ります。製薬であれば「化合物→標的→疾患→特許→企業」、素材であれば「原料→組成→工程→物性→用途→規制→顧客」といった連鎖がつながっていれば、「うちの会社にとって、まだ誰も触っていない空白地帯はどこか」を機械が代わりに探してくれます。
このセクションのまとめ
ナレッジグラフは「物事を点、関係を線で書いた地図」で、本質は線の意味の豊かさにあります。Googleが2012年に広めた言葉ですが、いまの主役はもう検索画面ではなく、LLMやAIエージェントを賢く動かす裏方インフラへ移りつつあります。次のセクションでは、その地図がどんな部品でできているのか、「ノード」「エッジ」「オントロジー」というたった3つの最小要素を、学校の出席名簿のたとえで見ていきます。
中身はノード・エッジ・オントロジー、たった3つだけ
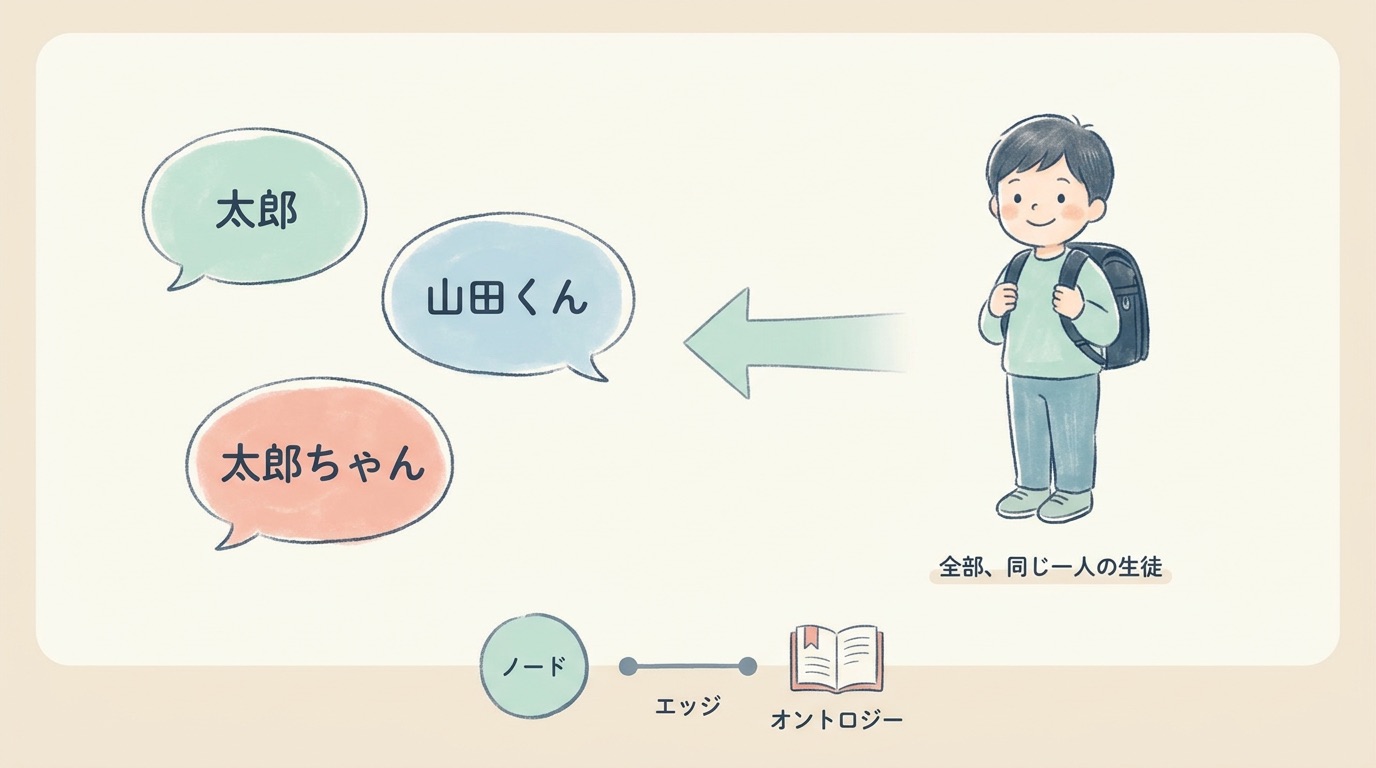
前のセクションでは、ナレッジグラフを「点と線で描いた巨大な相関図」と紹介しました。ここからは、その中身がどう作られているのかをのぞいてみます。といっても、覚えるのはたった3つの言葉だけで十分です。ノード、エッジ、オントロジー。順番に説明します。
ノードとエッジ、これは「点」と「線」のことです
ノードは「点」、エッジは「線」のことです。IBMはナレッジグラフの最小要素を「ノード、エッジ、ラベル」の3つで説明しています。ノードは人や物や概念といった「対象」、エッジはその対象どうしの「関係」、ラベルはその関係の意味、という整理です。
たとえば、「太郎」をノード、「花子」をノードとし、その間に「同じクラス」というエッジを引く、という感じです。これを企業の研究現場でやると、「化合物A」「標的タンパク質B」「論文C」「特許D」「企業E」がノードになり、「Aは何の論文で報告された」「DはAを請求している」「EはDを出願した」といった関係がエッジになります。
ここまでは、なんとなくイメージできると思います。
本当に難しいのは「つなぐ」ことじゃなく「同じものとして扱う」こと
ここからが、参考文献を読んでいていちばん面白かった話です。中学校の出席名簿を想像してください。クラス担任の先生は「太郎」と呼び、部活の先生は「山田くん」と呼び、保護者会では「太郎ちゃん」と呼ばれる、同じ一人の生徒がいたとします。もしシステムがこの3つを「別の3人」として扱ってしまったら、出欠も成績もテストの点数もぐちゃぐちゃになりますよね。
実は、ナレッジグラフを企業で作るときに、本当に難しいのはここなんです。同じ材料が、研究部では「開発コード」、製造部では「グレード名」、営業部では「商品名」、特許部では「化学式」で呼ばれていることが普通にあります。これを「同じものですよ」と機械に教えてあげない限り、どれだけ立派なグラフを作ってもバラバラのままです。
参考文献では、ナレッジグラフ構築の本丸が「ID戦略と更新パイプラインにある」と整理されていました。ちょっとお堅い表現ですが、要するに「呼び方の違うものを1つにまとめるルールと、それを毎日新鮮に保つ仕組み」が一番大変、ということです。これが見えてくると、「ナレッジグラフはデータを集める仕事」ではなく「言葉の意味を揃える仕事」だとわかってきます。
オントロジー、これは「学校のクラス分けルール」みたいなものです
3つ目の言葉、オントロジーです。むずかしそうですが、要は「点と線の意味を、組織のみんなで揃えるためのルールブック」です。Ontotextはオントロジーを「ナレッジグラフのデータスキーマ」と表現し、さらに「開発者と利用者のあいだの正式な契約」とも説明しています。「契約」と言うとイカつい感じがしますが、ここでは「同じ言葉を同じ意味で使うための約束」と思ってください。
学校でたとえるなら、「1年A組と1年B組をまとめて『1年生』と呼びましょう」「『部活』とは週1回以上集まる活動を指します」というクラス分けのルール集が、まさにオントロジーです。これがないと、「太郎は何年生?」と聞いただけで人によって答えが違ってしまいます。
会社の例だと、製薬会社が「標的」と言ったとき、それが「遺伝子」なのか「タンパク質」なのか「経路」なのかをはっきり決めておく作業がオントロジーです。素材メーカーが「性能」と言ったとき、それが「物性値」なのか「工程の安定性」なのか「顧客の評価」なのかを揃える作業もそうです。これが揃っていないと、AIに質問してももっともらしいけれど再利用できない答えが返ってくることになります。
あと少しだけ、RDF・SPARQL・Cypherという用語に触れさせてください
ここまで覚えてもらえれば、入門としては十分です。ただ、もうちょっと業界用語にも触れておきます。
ナレッジグラフを作るときの「書き方の標準」として有名なのが、W3C(Web技術の標準化団体)が決めた「RDF(Resource Description Framework)」です。RDFは、すべての知識を「主語、述語、目的語」の3つ組(これを「トリプル」と呼びます)で表す書き方です。たとえば「化合物A − 阻害する − 標的B」というふうに、3つの単語の組みで関係を書いていきます。日本のVeriServeは、これを「さまざまな種類の情報源からデータを取り出し、融合し、その統一的な表現を可能にする」仕組みだと説明しています。
そして、こうやって作ったグラフに質問するための言葉が、「SPARQL」と「Cypher」です。SPARQLはRDF系のグラフに、CypherはNeo4jなどのグラフデータベースに使います。両者は英語と日本語くらい見た目が違いますが、目的は同じで、「グラフに対して『この条件にあてはまる関係を全部出して』とお願いするための言葉」です。エクセルでフィルタをかける感覚を、もっと自由にできるようにしたもの、と思ってください。
このセクションのまとめ
ナレッジグラフの中身は、点(ノード)、線(エッジ)、意味の約束(オントロジー)の3つです。ややこしく見えますが、本当に難しいのは点を増やすことではなく、「呼び方の違うものを1つにまとめる」「言葉の意味を組織でそろえる」という地味な作業のほうです。ここがそろえば、AIエージェントは初めて「業務で使える文脈」を持てるようになります。次のセクションでは、この仕組みが、いま話題のRAGやGraphRAGとどう組み合わさるのか、「司書」と「探偵」のたとえで見ていきましょう。
AIとの組み合わせ方、RAGとGraphRAGの違いを図解で理解する
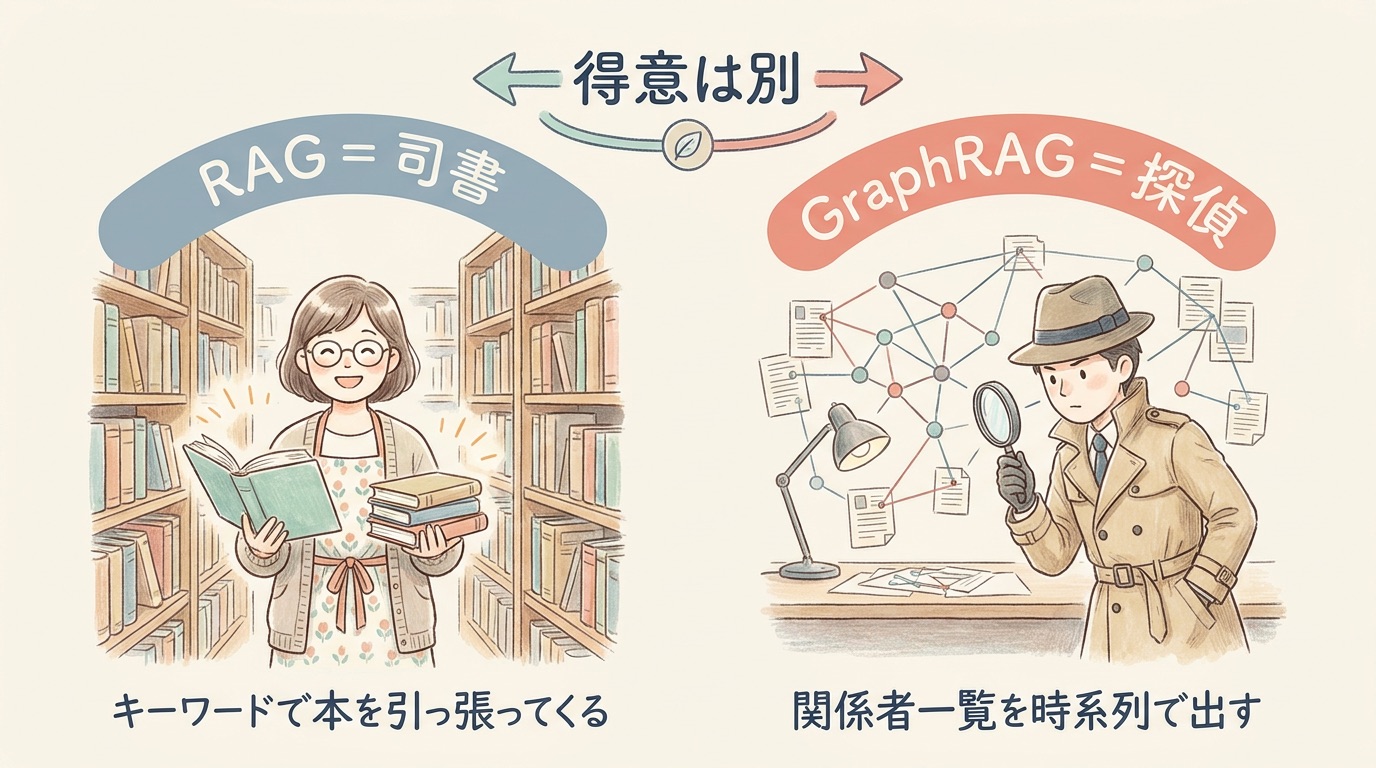
前のセクションで、ナレッジグラフを作る部品の話までいきました。ここからは、いま流行りの生成AIとの組み合わせ方を見ていきます。とくに重要なのが、RAGとGraphRAGの違いです。両方とも「LLMに正しい情報を渡す技術」なのですが、得意分野がけっこう違います。
RAGは「司書」、GraphRAGは「探偵」だと思ってください
たとえ話から入ります。RAGは、図書館の司書さんです。「半導体の最近の動向ってどうですか?」と聞くと、関連する本を素早く何冊か棚から取ってきてくれて、「だいたいこういう感じです」と要約してくれます。これはこれでかなり便利です。実際、社内文書検索チャットボットの多くはこの仕組みで動いています。
一方のGraphRAGは、探偵です。「この事件、関係者一覧を時系列で並べてください」とお願いすると、人物相関図を引っ張り出して、「Aさんは去年Bさんと取引があり、Bさんは半年前Cさんと連絡を取り、Cさんが先週現場近くにいました」と、関係をたどって組み立ててくれます。
この違いは、実務で響いてきます。司書(RAG)は1つの問いには強いです。でも「Aと関係するBのうち、Cの条件を満たすものは?」のように何ステップも関係をたどる問いになると、文書を引いてくるだけでは届きません。そういうときに探偵(GraphRAG)の出番になります。
MicrosoftとGoogleがGraphRAGを推している理由
GraphRAGという言葉が一気に広まったのは、Microsoftが2024年にこれをパッケージ化してから、と言ってよいと思います。Azure Database for PostgreSQL向けの発表では、Microsoftは自社のGraphRAGソリューションを「LLM応答の品質と情報検索パイプラインの精度を向上させる」ものだと位置づけ、ベクトル検索、セマンティックランキング、GraphRAGの3つを組み合わせる構成を示しました。
Google Cloudも同じく、GraphRAGについて「RAGに対するグラフベースのアプローチ」と説明し、その狙いを「より詳細で関連性の高い AI レスポンス」を得ることだとしています。要するに、両社ともAIエージェントを企業の現場に下ろすときに、「文書検索だけだと届かない壁」を関係グラフで超えようとしているわけです。
国内でも実装が動いています、パナソニックの例
「海外の話でしょ?」と思った方に、国内の具体例を紹介させてください。
パナソニック コネクトは、社内の業務AIの精度を上げるために、「RAGの参照先にナレッジグラフを使って回答の速度と精度を上げる方法と、AIエージェントが自律的な質疑応答を繰り返して不要な情報を減らす方法」を組み合わせたと発表しています。これは結構画期的な構成で、3つの技術が同時に動いています。
1つ目は、文書を直接探すRAG(司書)。2つ目は、その参照先を整理しているナレッジグラフ。3つ目は、回答を絞り込むAIエージェント。司書と探偵と編集者がチームで動いているイメージです。
富士通も2024年に、「既存RAGでは大規模データを正確に参照できない課題」があるとして、ナレッジグラフ拡張RAGを開発したと発表しました。関係性を踏まえた知識を与えることで「論理推論や出力根拠を示すことが可能」になる、というのが要点です。AIが答えを出すときに、「なぜそう答えたのか」を一緒に示せるようになるのは、業務で使う側にとって決定的に大事です。
「LLMだけだとなぜ困るのか」をはっきりさせておきます
ここで一度、RAGやGraphRAGがなぜ必要になったのかを整理させてください。
LLM(ChatGPTの中で動いているような大規模言語モデル)は、文章の流暢さは天才クラスですが、「最新の社内データを知らない」「事実をそれっぽく作ってしまう」「複数の関係をたどる思考が弱い」という3つの弱点があります。RAGは1つ目の弱点を、GraphRAGはさらに3つ目の弱点を補う、という役割分担です。
ちょっとオタクな話を一つ。AI研究の特許文献では、LLMの問題について「文脈はLLMを少し賢くするけど、確率的な性質そのものは変わらない」と書かれています。つまり、どれだけグラフで補強しても、LLMはサイコロを振りながら答えを作っている、というのが現実です。GraphRAGは「サイコロの目を正解寄りに重ねる仕掛け」ではあるけれど、サイコロをなくす技術ではない。ここを理解しておくと、過剰な期待で失敗するのを避けられます。
じゃあ、なぜそれでもGraphRAGが効くのか
それでもGraphRAGに価値があるのは、「答えが当たる確率を上げる」だけじゃなく、「答えの根拠をたどれる」からです。AIエージェントが「この材料は次世代パッケージに向きます」と言ったとき、その理由が「論文Xでこの物性が報告されていて、それは用途Yの要件を満たし、しかも特許Zで競合が押さえていないから」と関係つきで返ってきたら、人間が確かめられます。
参考文献にあるAI研究のサーベイでも、GraphRAGは「局所的な事実検索と大域的なコミュニティ構造の両方を扱える」と整理されていました。「局所的」は1点の正確さ、「大域的」は全体の構造、という意味です。司書(RAG)は局所的に強く、探偵(GraphRAG)は大域的にも強い。これが業務調査の現場で効いてくる本当の理由です。
このセクションのまとめ
RAGは「司書」、GraphRAGは「探偵」、と覚えてください。司書は1問1答に強く、探偵は関係をたどる調査に強い。MicrosoftやGoogle、富士通、パナソニックといった会社が2024〜2025年にGraphRAG型の実装を相次いで出してきたのは、LLMを業務で使うには「探偵モード」が必要だと、現場が気づき始めたからです。次のセクションでは、これを実際の仕事の場面に落とし込んで、製薬・素材・知財でどう効くのかを見ていきます。
実際の使い方、製薬・素材・知財でこう効く具体例
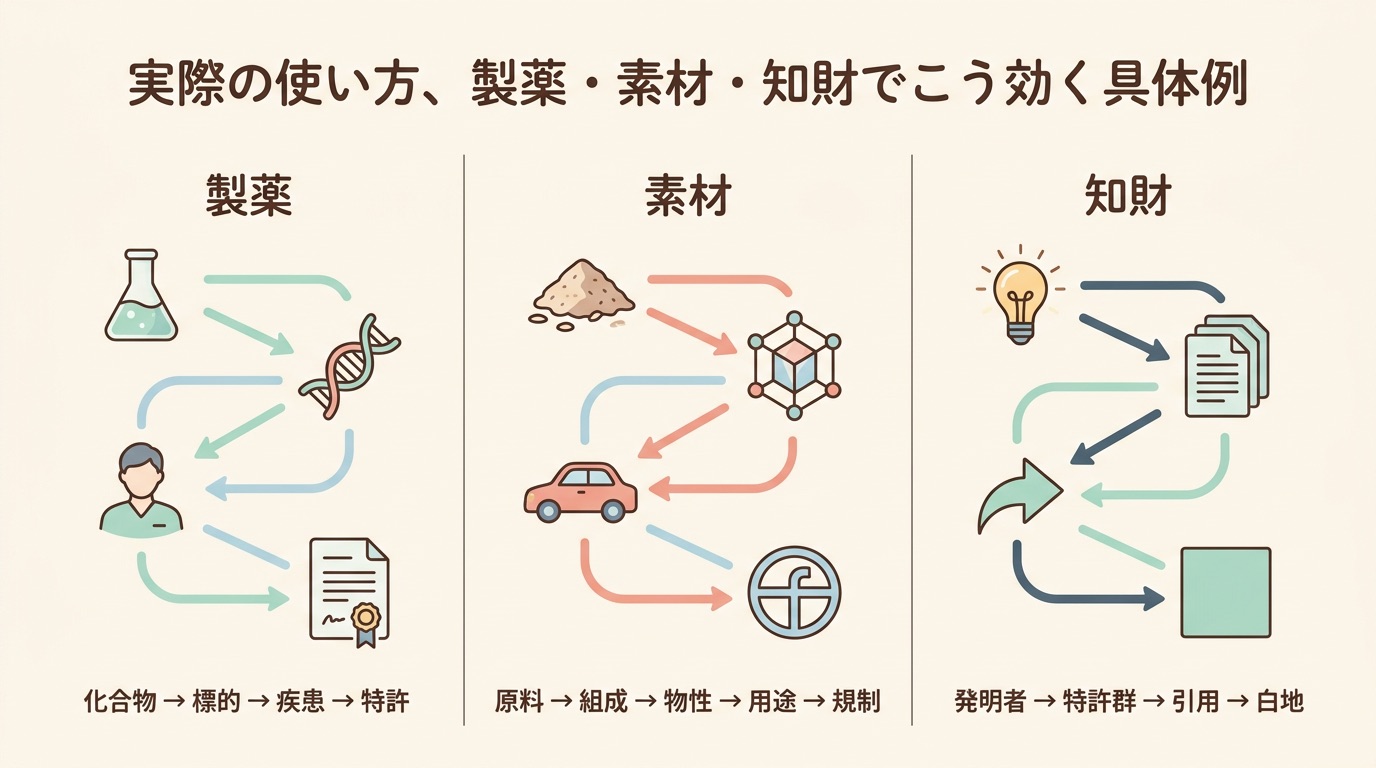
「で、結局自分の仕事ではどう使うんですか?」というのが、ここまで読んだ皆さんの本音じゃないでしょうか。ここでは、参考文献で深掘りされている産業のうち、製薬・素材・知財の3つを例に、ナレッジグラフが実際にどう効くのかを見ていきます。中学生でもイメージできるように、できるだけ具体的に書きます。
共通の設計図、5つの層でできています
まず、業界が違っても、ナレッジグラフの作り方の骨組みはだいたい同じです。研究では、エンティティ層、関係層、属性層、出典層、仮説層という5つの層で考えると整理しやすいと整理されていました。
たとえると、ピザに似ています。生地(エンティティ=対象)の上にトマトソース(関係)を塗り、チーズ(属性)をかけ、何のレシピか分かるように材料リスト(出典)を添え、最後に「次はこんなアレンジもできそう」というメモ(仮説)を残す。この5層構造があるから、AIエージェントが「次にどこを掘ればいいか」を考えやすくなります。
では、業界別に見ていきます。
製薬、化合物→標的→疾患→特許を一直線で見る
製薬は、ナレッジグラフがいちばん相性のいい業界の1つです。理由はシンプルで、もともと知識が「関係まみれ」だからです。
たとえば「ある新薬を開発したい」と思ったとき、考えなきゃいけない関係は、こんな感じです。
- どの標的タンパク質にくっつくのか
- その標的はどの疾患と関連しているのか
- 過去にどんな論文で報告されてきたのか
- どんな特許で先に押さえられているのか
- どんな臨床試験が進んでいるのか
- 既存の薬と比べて副作用はどうなのか
文書で1個ずつ調べると、丸一日かかります。ナレッジグラフ化してあると、「疾患Xに関連する標的のうち、論文は増えているのに特許がまだ薄く、社内アッセイで再現できる候補は何か」みたいな質問を1問で投げられるようになります。日本のVeriServeも、医療分野の例として「遺伝子、疾患、症状、治療法、薬剤といった多様な医療データをナレッジグラフで表現」できると説明しています。
製薬の研究現場でいちばん効くのは、「研究の有望性」と「事業化のしやすさ」を1画面で見られることです。論文では大注目の標的でも、特許がガッチガチに押さえられていたら事業化は難しい。逆に特許が空いていても、臨床的な根拠がうすければ後でつまずきます。ナレッジグラフは、この「やる価値」と「やれるか」を同じ地図で見せてくれるわけです。
素材、物性→用途→規制を横断して新しい使い道を見つける
素材産業はちょっと違う面白さがあります。同じ材料でも、配合、工程、顧客の要求、規制が変わると、「化ける」用途と「ハマらない」用途が出てきます。Altair Japanは、ナレッジグラフが「データのサイロ化を解消し、AIによる分析に必要な広がり・深さ・文脈を提供する」ことだと整理しています。
最近、世の中ではPFAS規制(一部のフッ素化合物への規制)やVOC規制(揮発性有機化合物への規制)が強まっていて、いままで使えていた材料が急に使えなくなる、ということが頻発しています。素材メーカーが直面しているのは、まさにこの「代替材料を見つける速さ勝負」です。
ナレッジグラフがあると、こんな問いを立てられます。
- 「耐熱性と透明性を両立する材料群のうち、食品接触規制に触れにくい用途はどこか?」
- 「自社の材料Aと近い物性を持ちながら、競合がまだ深く入っていない用途カテゴリは何か?」
- 「PFAS代替候補の中で、既存工程の変更コストが小さい組み合わせはどれか?」
これらは、文書検索だと「物性が近い材料」までは出るのですが、「用途」「規制」「顧客課題」「競合」までは一度につながらないんです。グラフ化されていると、材料を真ん中において、放射状にこれらの線をたどれます。営業ヒアリングや展示会で集めた情報が、グラフの一部として残っていくのが理想形です。
知財、自社特許と競合特許のあいだの「白地」を見つける
3つ目は知財です。ここはナレッジグラフのうまみが直接効く領域です。
知財調査の世界では、「白地(はくち)」という言葉があります。「競合がまだ出願していなくて、自社の技術にも近い、空いている領域」のことです。新規テーマを企画するときに、ここを正確に見つけられると、研究開発の効率が一気に変わります。
ノードと関係を整理すると、こんな感じになります。
- 特許 − 出願人 − 企業
- 特許 − 引用 − 別の特許
- 特許 − 分類 − 技術カテゴリ(IPC/CPC)
- 特許 − 対象 − 技術課題
- 技術課題 − 適用先 − 市場
「うちの会社の特許群と、競合5社の特許群を引用関係でつないで、市場成長が見込まれていて自社未出願の空白を出してください」という問いを投げると、ナレッジグラフは図のような形で返してくれます。これを文書検索だけでやろうとすると、まず引用関係を取るのに数日、企業との対応付けにさらに数日、と数週間仕事になります。グラフ化してあると、これが数分です。
国内で実際に動いている例、Snorbeの場合
参考文献で取り上げられていた、国内サービスの実装例も紹介させてください。リサーチエージェントのSnorbeは、調査をしながらナレッジグラフを蓄積していくという、ちょっと面白い設計をしています。
公式説明では、Snorbeは「収集情報をナレッジグラフとして蓄積しながら次の調査テーマを自律提案する」と紹介されています。さらに、「対話を重ねるほど文脈を記憶し、ホワイトスペースを自動検出して次の調査テーマまで提案できる」とも書かれています。
これがR&Dや新規事業の現場で何を意味するかというと、「一度きりの調査レポート」が「積み上がっていく地図」に変わるということです。普通、調査レポートは作って終わりです。半年後に同じテーマを調べると、ゼロからやり直しになりがちです。Snorbe型は、その都度ナレッジグラフが成長していくので、「先月までに何をどこまで調べたか」「次に何を掘るべきか」が記憶される仕組みです。
国内大手の動き、富士通Kozuchiとパナソニック
製造業の業務AIの土台としては、富士通Kozuchiも触れておきたいです。Kozuchiは「純粋なナレッジグラフ専業」ではないのですが、日本企業のAI業務活用にナレッジグラフ的な文脈活用を取り込んでいる現実路線のプレイヤーとして注目されています。
前のセクションで紹介したパナソニック コネクトの「RAG+ナレッジグラフ+AIエージェント」の組み合わせも、まさに国内製造業がナレッジグラフを業務に組み込み始めている例です。日本企業は、海外のように「Knowledge Graph」を前面に出さないので、表からは見えにくいのですが、裏では着実に実装が進んでいます。
中学生にも翻訳すると、こんな感じです
ここまで業界の話を続けてきたので、最後に小さく翻訳しておきます。
ナレッジグラフを使った調査は、たとえると、「日本中の中学生のテスト結果、部活、好きな科目、進路希望を全部つないだ巨大な相関図」を作るような作業です。それがあると、「この市で、数学が得意で、将来エンジニアになりたいけど、まだそういう情報を発信しているお兄さんに出会っていない中学生は誰か?」という質問ができるようになります。
ビジネスの世界でも、製薬は「化合物と疾患と特許の相関図」、素材は「材料と用途と規制の相関図」、知財は「特許と発明者と引用の相関図」を作っているわけです。業界ごとの「相関図の主役」が違うだけで、やっていることは同じです。
このセクションのまとめ
製薬では「化合物→標的→疾患→特許」、素材では「材料→物性→用途→規制」、知財では「特許→引用→技術分類→市場」。どの業界でも、ナレッジグラフの本質は「線を増やすことで意思決定が速くなる」ことにあります。Snorbeのようなサービスは、その線を調査をしながら自動で増やしてくれる仕組みを作り始めています。次のセクションでは、こうした動きが2025〜2026年でどう進むのか、そしてあなた自身が明日からできる小さな一歩を整理します。
これからどうなる?AI時代の裏方インフラとしての進化と今すぐできる一歩
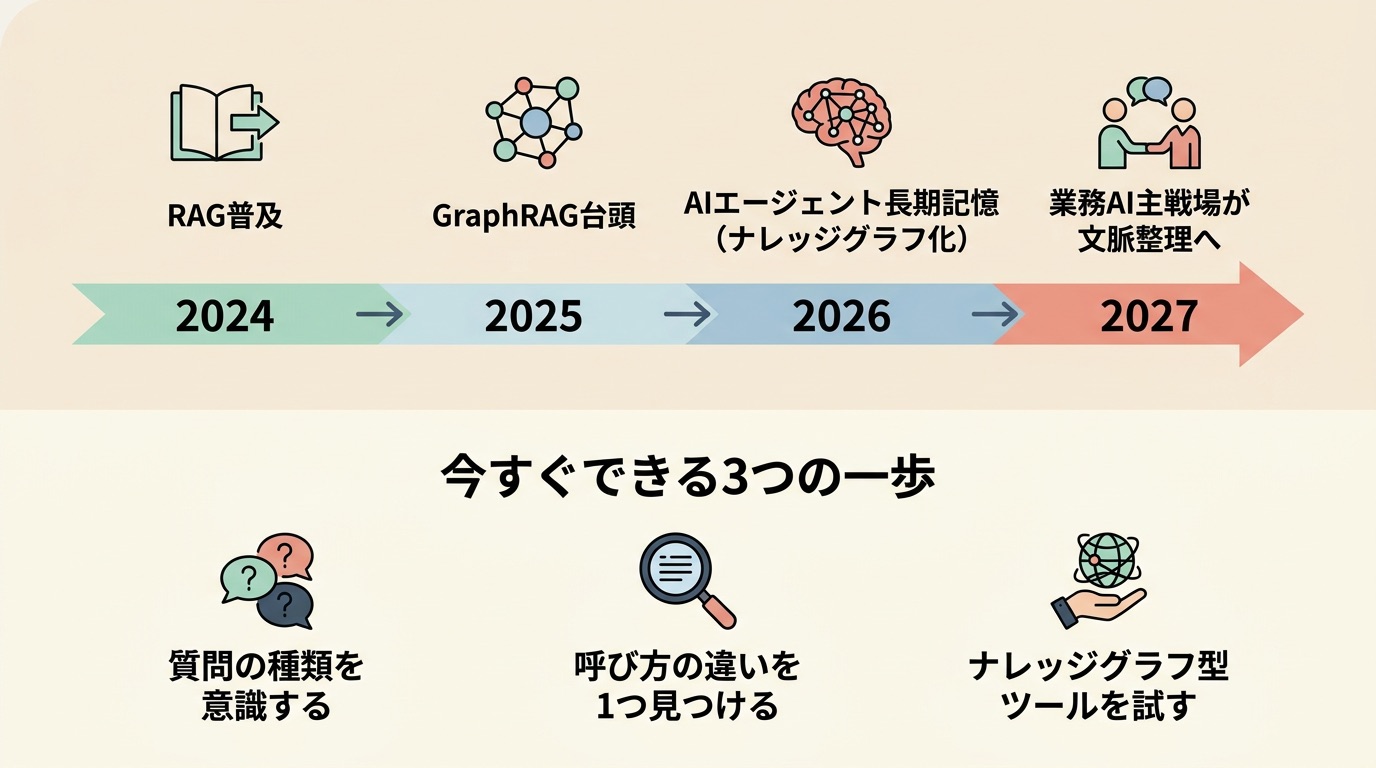
ここまでナレッジグラフの正体、中身、AIとの組み合わせ、業界別の使い方を見てきました。最後に、これからの3〜5年でこの分野がどう動きそうか、そして読者の皆さんが明日からできる現実的な一歩を整理して終わります。
言葉は流行らないけど、仕組みは絶対に普及します
最初に予想を1つ。「ナレッジグラフ」という言葉が、世間で大流行することは、たぶんありません。これは悲観論ではなく、むしろ良いニュースです。なぜなら、本当に普及する技術ほど、表に出ずに当たり前に動くからです。
たとえば、いま私たちが毎日使っているスマホは、裏でリレーショナルデータベース(RDB)という古い技術が動いています。でも、「最近RDBが流行ってるよね」と話題にする人はゼロです。ナレッジグラフもこれと同じ運命をたどると、参考文献の議論を統合すると見えてきます。表で流行るのは「GraphRAG」「AIエージェント」「Deep Research」みたいな上の層で、その下にナレッジグラフが静かに敷かれていく構図です。
IBMが述べている通り、ナレッジグラフは大規模化すると「a foundational asset for AI」、つまりAIの基礎資産になります。基礎なので、表に見えなくていいんです。
2026年からの3つの動き
参考文献を読み込んで、2025〜2026年以降に起こりそうな動きを3つに絞ってみました。
1. AIエージェントの長期記憶がナレッジグラフ化する
ChatGPTやClaudeに「前回の話の続きやって」と頼むと、いまはまだトンチンカンになることがありますよね。これは「会話履歴」を時系列でしか覚えていないからです。AI研究のサーベイでは、AIエージェントが「長期記憶」「マルチホップ推論」「ツール使用」「他エージェントとの協調」を支える構造として、ナレッジグラフが重要視されています。
つまり、これからのAIエージェントは、「あなたが何の話をしたか」だけでなく、「その話が何と関係しているか」をグラフで覚えるようになります。仕事用のAIに「先月の競合調査の結論を踏まえて、今月の販促企画を出して」と頼んだら、ちゃんと先月の論点を構造として呼び戻してくれる。そういう世界が普通になります。
2. 業務AIの主戦場が「モデルの賢さ」から「文脈の整理」に移ります
これも大事な変化です。海外スタートアップのInterloomを取り上げた報道では、AIエージェントは「組織固有の文脈」なしには大企業で機能しにくい、と指摘されています。さらに「エージェントの良さは、依存できる専門家の判断の良さに等しい」とまで書かれています。
これがどういう意味かというと、「いいモデル(賢いLLM)を買えば業務AIが動く」という時代は終わる、ということです。むしろ、社内の「これを顧客と呼ぶ」「これを有望テーマと呼ぶ」「これを失敗と呼ぶ」といった定義の集まりを、どれだけきれいに整理してAIに渡せるかで勝負が決まります。これはまさに、ナレッジグラフが得意とする領域です。
参考文献にもあった「退職するベビーブーマー世代が、10年単位の組織知を持ったまま去っていく」という指摘は、日本でも他人事ではありません。製造業のR&Dでは、「この材料系は昔失敗した」「この用途は規制で止まる」「この企業は共同開発は速いが量産は遅い」といった暗黙知が、定年退職とともに静かに失われています。これをナレッジグラフで再利用可能な関係データに変換することが、2026年以降の組織にとって死活問題になります。
3. 国内では富士通・Snorbe・Sakana AI・NTT・PFNが、文脈レイヤーで動き始めます
日本国内も、けっこう動いています。富士通は2024年6月に「ナレッジグラフ拡張RAG」を発表しています。NTTは長年の研究蓄積で、ナレッジグラフの「基本単位はトリプル」といった概念整理を、日本語で読める形で広めています。Snorbeのようなリサーチエージェントは、調査エージェント+ナレッジグラフという新しいカテゴリを切り開いています。
参考文献の整理では、Sakana AIやPreferred Networks(PFN)は「ナレッジグラフ専業ではないが、日本国内のAI実装競争を考えると無視できない」プレイヤーとして位置づけられていました。理由は、2025〜2026年の競争軸が「誰が最も大きいグラフを持つか」ではなく、「誰が企業文脈に沿って探索・推論・提案を動かせるか」に移っているからです。
日本市場の有力な構図は、こんな感じになりそうです。
| レイヤー | 担い手 | 役割 |
|---|---|---|
| 基盤(DB・GraphRAG) | AWS、Neo4j、Microsoft等の外資 | 国際標準技術を短期で導入 |
| 業務実装 | 富士通Kozuchi、NTTなど国内大手 | 既存システム連携と説明可能性 |
| 調査エージェント | Snorbeなど新興サービス | 情報収集とKG蓄積、白地検出 |
| モデル・推論 | Sakana AI、PFN | LLMと推論最適化 |
参考文献では、これは「名称は前面に出ていなくても、AIエージェント時代の文脈基盤として静かに実装が始まっている」と表現されていました。日本は遅れているのではなく、実装論に入りつつある、という見方です。
でも、注意点も正直に書いておきます
ここまで前向きに書いてきましたが、参考文献にあった現実的な指摘も伝えておきます。
ナレッジグラフを入れても、LLMの幻覚は消えません。AI研究の特許文書では、RAGや各種チューニングがあっても「LLMの確率的な性質そのものは変えられない」と書かれていました。これは厳しい現実ですが、ちゃんと頭に入れておくと、過剰な期待で失敗するのを防げます。
それから、「グラフを作っただけで賢くなる」は幻想です。Ontotextは、ナレッジグラフの本質を「開発者と利用者のあいだの正式な契約」と表現していました。要するに、技術ではなく社内の意味合意のシステムだ、ということです。ここを甘く見ると、PoCで見栄えのよいデモは作れても、本番で使えない「綺麗なゴミ」を量産することになります。
今すぐできる3つの一歩
ここまで読んでくださった皆さん、長文おつかれさまでした。最後に、明日からできる現実的な3つの一歩を提案します。
1. AIサービスを使うときに「これは検索型か、関係探索型か」を意識する
ChatGPTやClaude、社内の業務AIを使うときに、自分の質問が「1つの情報を取りに行く問い」なのか、「複数の関係をたどる問い」なのかを意識してみてください。前者なら従来のRAGで足ります。後者なら、いまの社内AIだと届かない可能性が高いです。この差を体感できると、ナレッジグラフが必要な場面が見えてきます。
2. 自分の業務の中で、「呼び方の違いで損している場面」を1つ見つける
研究のコード名、製造のグレード名、営業の商品名、特許の化学式。同じものが部門ごとに違う名前で呼ばれていて、誰かが手作業で突き合わせている場面はありませんか? そこは、ナレッジグラフ的な整理がいちばん効く場所です。この気づきが、社内AI化の最初の一歩になります。
3. 試しにナレッジグラフ型のリサーチサービスを触ってみる
百聞は一見にしかず。たとえばSnorbeは、「対話を重ねるほど文脈を記憶し、ホワイトスペースを自動検出して次の調査テーマまで提案できる」と公式に説明されています。自分の業界のテーマで実際に何度か聞いてみて、回答が積み上がっていく感覚を体験してみると、「AIエージェント時代の調査」がどう変わるかが体でわかります。
最後に
ナレッジグラフは、Googleの検索画面で見た「あれ」のことだけだと思っていた方も、ここまで読んで、ずいぶんイメージが変わったんじゃないでしょうか。点と線で世界を整理するという発想は、もう何十年も前からありました。それが2024〜2026年に再評価されているのは、生成AIという「文章だけは流暢な天才」を業務に下ろすときに、ちゃんと根拠を持って関係を辿らせる仕組みが必要になったからです。
主役は派手なLLMかもしれませんが、それを支えているのは地味なグラフです。スタジアムのライトが眩しくても、芝生がしっかり育っていないと試合にならない、と思ってください。
これから3年、あなたの会社で使うAIエージェントが、どれだけ業務の言葉を理解しているか。それは結局、裏側にどれだけ整理されたナレッジグラフがあるかで決まります。今日この記事を読んで「自分の仕事の中の呼び方の違いが気になる」と感じたなら、それがもう、最初の一歩です。
調査手法について
こちらの記事はグラフAIリサーチプラットフォームのSnorbeを使って作られています。Snorbeは研究開発・新規事業向けの調査テーマに応じた幅広い項目のオートリサーチや、ナレッジグラフの構築、構造化レポートの生成ができるAIリサーチツールです。
Screenshot
調査したいテーマを入力するだけで、AIが深堀りすべき観点や広げるべき調査項目をレコメンドしながら、自動でリサーチを進めます。収集した情報はナレッジグラフとして蓄積され、未調査領域(ホワイトスペース)を可視化しながら調査の網羅性を高めていけます。
また、観点マトリクスを30秒・構造化レポートを10分で自動生成する機能があり、出典付きのレポートをMarkdown/PDF形式でエクスポートできます。調査の元データも保存されるため、ファクトチェックや社内共有も容易です。
ご利用をご希望の方は、こちらよりお申し込みください。
また、グラフAIを活用した社内ナレッジ管理や、研究開発・新規事業のリサーチ支援、セルフホスト導入のご相談も受け付けています。お困りの方はお気軽にご連絡ください。
市場調査やデスクリサーチの生成AIエージェントを作っています 仲間探し中 / Founder of AI Desk Research Agent @deskrex , https://deskrex.ai

コメント