- AIエージェント開発の最新トレンド – 企業導入率82%の秘密
- ゼロから構築 vs 既存フレームワーク – AIエージェント作り方の決定的分岐点
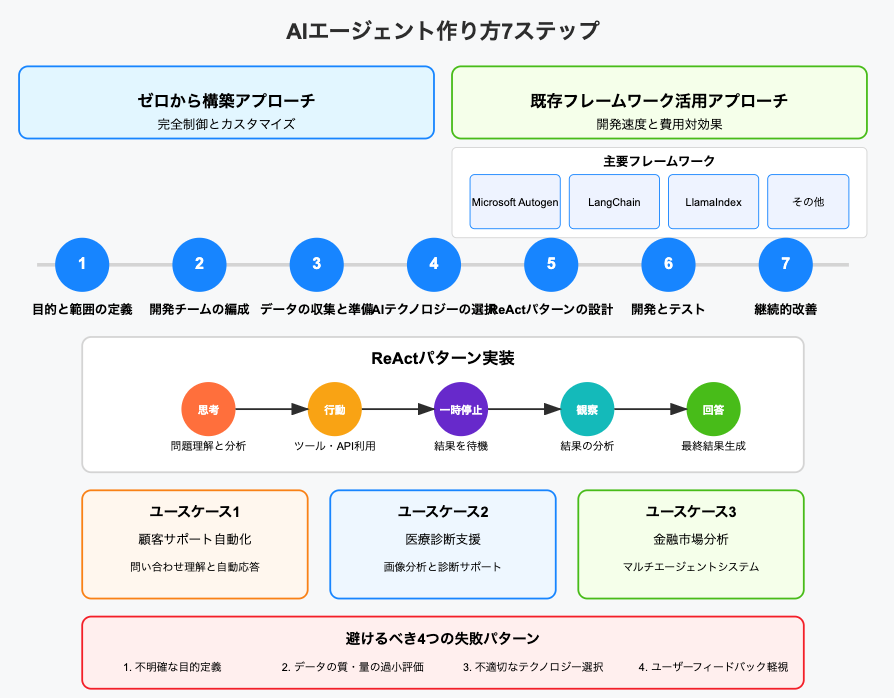
- AIエージェント作り方の7ステップ実践ガイド – チーム作りからデザインパターンの活用
- 失敗しないAIエージェント構築術 – リアルタイム処理とスケーラビリティの壁を突破
- 実例で学ぶAIエージェントの作り方 – 3つのユースケースと避けるべき4つの失敗
- 調査手法について
AIエージェント開発の最新トレンド – 企業導入率82%の秘密

この記事では、AIエージェントの作り方を7つの具体的ステップで徹底解説します。AIエージェントの導入が加熱する背景から、ゼロから構築する方法と既存フレームワークを活用する方法の比較、ReActパターンを活用した実装手法、リアルタイム処理とスケーラビリティの課題解決法まで、実践的な知識を網羅しました。
さらに、顧客サポート・医療診断・金融分析の3つの成功事例と、多くのプロジェクトで繰り返される4つの致命的な失敗パターンを紹介し、あなたのAIエージェント開発を成功に導くための具体的なヒントを提供します。
AIテクノロジーの急速な発展により、AIエージェントの作り方に注目が集まっています。業界を問わず、多くの企業がAIエージェントの導入を急ピッチで進めている背景には、競争優位性の確保と業務効率化への期待があります。では、なぜこれほど多くの企業がAIエージェント開発に熱心なのでしょうか?
主要企業1,100社の調査結果とAIエージェント活用状況

主要企業のエグゼクティブ1,100人を対象とした調査で、すでに10%の企業がAIエージェントを実装済み、さらに驚くべきことに82%が今後3年以内に導入を計画していることが明らかになりました。この数字は単なるAIブームではなく、実際のビジネス価値を見出した企業の戦略的判断を示しています。
特に注目すべきは導入スピードです。調査対象企業の60%が1年以内にAIエージェントの作り方を学び、実際に構築に着手する予定であるという事実です。残りの企業も3年以内には何らかの形でAIエージェントを活用する計画を持っています。
現在AIエージェントを活用している業界別の内訳を見ると:
- 金融業界: 不正検出と取引分析に特化したAIエージェント
- ヘルスケア: DeepMindやIBM Watson Healthなどによる医療診断支援システム
- 製造業: サプライチェーン最適化とプロセス自動化
- 小売業: パーソナライズされた顧客体験の創出
AIエージェントの作り方を知り、早期に導入した企業は、顧客満足度の向上、業務効率の30%以上の改善、そして新たな収益源の創出といった具体的な成果を報告しています。
市場で求められているAIエージェントの機能と種類
AIエージェントには、大きく分けてアシスタントエージェントと自律エージェントの2種類があります。それぞれに特徴的な機能と応用領域があります。
アシスタントエージェント
これらは人間の業務をサポートするために設計されており、次のような機能が求められています:
- 情報検索と要約: 膨大なデータから必要な情報を探し出し、簡潔に要約
- スケジュール管理: 会議の設定、リマインダーの管理
- 業務効率化: 反復的なタスクの自動化とワークフロー最適化
例えば、UiPathやBlue PrismのようなRPA(ロボティック・プロセス・オートメーション)ツールと組み合わせたAIエージェントは、すでに多くの企業で導入され、従業員の生産性を大幅に向上させています。
自律エージェント
より高度な機能を持ち、人間の介入なしに複雑なタスクを完了できるAIエージェントです:
- 顧客対応: 問い合わせの理解と自動応答
- 意思決定: データに基づく戦略的判断のサポート
- 問題解決: 複雑な問題を分析し、解決策を提案
自律エージェントの作り方で重要なのは、高品質なトレーニングデータの準備と、エージェントが取るべきアクションの明確な定義です。定番なのが、ReActパターン(Reason + Act)の実装で、思考・行動・観察のサイクルを通じてより効果的な問題解決が可能になります。
レポートから見る、今後3年の導入予測
このレポートでは、今後3年間でAIエージェントの作り方と導入がどのように進化するかについて、次のような予測を示しています:
- 2024年: 60%の企業がAIエージェントを導入し、主に単一機能に特化したエージェントが中心となる
- 2025年: マルチタスク対応のAIエージェントが主流となり、マルチエージェントシステムへの移行が始まる
- 2026年: 82%の企業がビジネスプロセスの中核にAIエージェントを据え、全社的な統合が完了する
特に注目すべきは、AIエージェント開発のフレームワークとツールが急速に進化している点です。2024年から2025年にかけて、Microsoft AutogenやLangChain、LlamaIndexなどのフレームワークを活用したAIエージェントの作り方が標準化され、より少ない技術リソースでの開発が可能になると予測されています。
また、業界別の導入率についても興味深い予測があります:
- 金融サービス: 2026年までに90%以上の導入率を達成
- 小売・消費財: カスタマーエクスペリエンスを重視したAIエージェントの普及
- 製造: 生産ラインとサプライチェーン全体を統合管理するエージェントの台頭
- ヘルスケア: 患者ケアとデータ分析を組み合わせた診断支援エージェントの普及
特筆すべきは、AIエージェントの開発コストが急速に低下するという予測です。ゼロからAIエージェントを構築する場合に比べ、既存フレームワークを活用した開発方法がより一般的になり、中小企業でも独自のAIエージェントを持つことが可能になるでしょう。
AIエージェントの作り方を学び、早期に導入することが企業の競争力維持に不可欠であることは明らかです。次のセクションでは、AIエージェントを構築する際の2つの主要アプローチである「ゼロから構築」と「既存フレームワークの活用」について、それぞれのメリットとデメリットを詳しく解説します。
ゼロから構築 vs 既存フレームワーク – AIエージェント作り方の決定的分岐点
AIエージェントの作り方を検討する際、最初に直面する重要な選択は「ゼロから構築するか」それとも「既存のフレームワークを活用するか」という決断です。この選択はプロジェクトの成功を左右する決定的な分岐点となります。両アプローチには明確な特徴があり、プロジェクトの目的、利用可能なリソース、タイムライン、必要なカスタマイズレベルによって最適な選択肢が変わってきます。
完全制御とカスタマイズを求めるなら「ゼロから構築」の実際
ゼロからAIエージェントを構築するアプローチは、最大の柔軟性と制御を求める企業や開発者にとって魅力的な選択肢です。このアプローチの核心は「完全なカスタマイズ性と設計の自由度」にあります。
ゼロから構築する利点
- 完全な設計と機能の制御: AIエージェントの動作の隅々まで細かく調整可能
- ビジネス特有のニーズへの最適化: 業界固有の要件に完全に合わせた設計が可能
- システム全体の所有権: サードパーティへの依存なく、すべてのコンポーネントとデータを自社で管理
ゼロからAIエージェントを構築した成功事例として、既存のソリューションでは捉えられない特殊な詐欺パターンを検出するために、完全にカスタマイズされたAIエージェントを開発するケースがあります。
ゼロから構築する際の実際の課題
ただし、このアプローチには重要な課題もあります:
- 高度な専門知識の必要性: 機械学習、自然言語処理、ソフトウェアエンジニアリングなど、複数分野の専門家チームが必要
- 開発時間の長期化: ゼロから構築する場合、典型的なプロジェクトでは6〜18ヶ月の開発期間が必要
- 高いコスト: 専門人材の確保、インフラ構築、テスト環境の整備など、総コストは既製ソリューションの2〜5倍に達することも
現実的には、強力なAI専門知識、十分な開発予算、そして既製ソリューションでは対応できない特定ニーズを持つ企業にとって最適な選択肢と言えます。
開発速度と費用対効果を重視するなら「既存フレームワーク」の活用法
一方、既存のフレームワークを活用したAIエージェントの作り方は、開発期間の短縮と初期投資の軽減という明確なメリットがあります。
既存フレームワーク活用の主なメリット
- 迅速な開発: 既製コンポーネントにより開発サイクルが大幅に短縮
- 低い技術的障壁: プログラミングの知識は必要ですが、AIの深い専門知識がなくても開発可能
- 費用対効果: 専門家チームの規模を縮小でき、初期コストを抑制
- 高度なLLM(大規模言語モデル)へのアクセス: 最新の言語モデルをすぐに利用可能
既存フレームワーク活用の課題
しかし、このアプローチにも注意点があります:
- カスタマイズの制限: フレームワークの設計上の制約内での開発となる
- サードパーティ依存: フレームワークの更新や変更に影響を受ける可能性
- 差別化の難しさ: 競合他社も同じフレームワークを使用している可能性があり、独自性の創出が課題
AI専門知識が限られている企業、タイトなスケジュール、標準的なAIエージェント機能を求める場合に最適なアプローチです。
Microsoft Autogen、LangChain、LlamaIndexなど主要フレームワークの比較
現在、AIエージェントの作り方を検討する際に注目すべき主要フレームワークには、それぞれ特徴と適した用途があります。以下に主要なフレームワークの比較を示します:
Microsoft Autogen
Microsoft Researchが開発したAutogenは、複数のAIエージェントが連携して作業するマルチエージェントシステムの構築に特化しています。
- 主な特徴: マルチエージェント会話、自己改善メカニズム
- 最適な用途: 複雑な意思決定、チームワークが必要なタスク
- 言語サポート: Python中心
- 学習曲線: 中〜高(マルチエージェント概念の理解が必要)
Microsoft Autogenを活用した事例では、複数のエージェントが異なる役割(コンシェルジュとフロントデスク)を担当し、旅行の推奨事項を共同で作成するシステムが紹介されています。
LangChain
LangChainは現在最も人気のあるフレームワークの一つで、モジュール式のアーキテクチャと豊富な統合オプションが特徴です。
- 主な特徴: 柔軟なコンポーネント構成、多数の外部サービス統合
- 最適な用途: 一般的なAIアプリケーション、データソースとの統合
- 言語サポート: Python、JavaScript
- 学習曲線: 低〜中(充実したドキュメントとサンプルコード)
LlamaIndex
LlamaIndexは、情報検索や知識管理に特化したフレームワークで、大量のドキュメントやデータソースを効率的に扱えます。
- 主な特徴: 高度なデータインデックス作成、RAG(検索拡張生成)
- 最適な用途: 情報検索、ドキュメント分析、知識ベース
- 言語サポート: Python、JavaScript
- 学習曲線: 中(データ構造の概念理解が必要)
crewAI
crewAIは比較的新しいフレームワークで、役割ベースのエージェントという概念を中心に設計されています。
- 主な特徴: 人間のチームワークを模倣、役割と目標の明確な定義
- 最適な用途: ビジネスプロセス自動化、協調作業
- 言語サポート: Python / Javascript
- 学習曲線: 中(概念的なフレームワークの理解が必要)
Mastra
Mastraは、TypeScript(JavaScript)で実装された比較的新しいLLMエージェントフレームワークで、オールインワン設計と型安全性を重視しています。
主な特徴:
- エージェント、ワークフロー、RAG(検索拡張型生成)、ツール、メモリ、評価・モニタリングなど、AIエージェント開発に必要な機能を統合
- 複数のLLMプロバイダ(OpenAI、Anthropic、Google、Metaなど)に対応し、モデルの切り替えやストリーミング応答も容易
- XStateベースのワークフローで複雑な処理フローを宣言的に記述可能
- 型安全なツール定義やAPI統合、GUIベースの開発支援ツールも提供
最適な用途:
- LLMを活用したAIエージェントや自律型AIアプリケーションの迅速な開発
- 複雑な業務プロセスの自動化や、外部知識を活用した高度なAIシステムの構築
言語サポート:
- TypeScript / JavaScript
学習曲線:
- 中(TypeScriptの知識と、エージェントやワークフロー設計の理解が必要)
フレームワーク選択のポイント
AIエージェントの作り方において、フレームワーク選択で考慮すべき重要なポイントは以下のとおりです。プロジェクトに適切なフレームワークを選びましょう。
- プロジェクトの複雑さ: 単純なタスク自動化ならLangChain、複雑な協調作業ならAutogen
- データ統合の必要性: 大量のデータやドキュメント処理が必要ならLlamaIndex
- 開発チームのスキル: 各フレームワークの学習曲線と開発チームの経験(TypescriptならMastraなど)
- スケーラビリティ要件: 将来的な拡張性を考慮したフレームワーク選択
ハイブリッドアプローチ:最良の選択肢?
興味深いことに、多くの成功プロジェクトではゼロから構築と既存フレームワークを組み合わせたハイブリッドアプローチを採用しています。実務の現場では、以下のような手法が効果的とされています:
- フレームワークで基本機能を素早く構築
- 差別化が必要な核心部分のみをカスタム開発
- 両者を統合して独自性と開発効率を両立
このアプローチにより、AIエージェントの作り方において「車輪の再発明」を避けつつ、ビジネスの競争優位性を確保することが可能になります。
次のセクションでは、AIエージェント作り方の実践的な7ステップを詳しく解説し、どちらのアプローチを選んだ場合でも適用できる効果的な開発プロセスを紹介します。
AIエージェント作り方の7ステップ実践ガイド – チーム作りからデザインパターンの活用

AIエージェントの作り方は単なる技術的な実装だけでなく、戦略的なプロセスから始まります。本章では、AIエージェント開発の具体的な7ステップと、特に効果的な「ReActパターン」の実装方法について解説します。ゼロから構築する場合も既存フレームワークを活用する場合も、この体系的なステップに従うことで、効率的にAIエージェントを開発できます。
エージェントの目的・範囲定義から開発チーム編成まで
ステップ1:目的と範囲の明確な定義
AIエージェントの作り方で最も重要な最初のステップは、何のためのエージェントなのか、どんな問題を解決するのかを明確にすることです。Salesforceによれば、明確な目的定義がないAIエージェント開発プロジェクトは、70%以上が途中で方向性を見失うか、期待された成果を出せずに終わると報告されています。
具体的に定義すべき項目:
- ターゲットユーザー: 誰がこのAIエージェントを使用するのか
- 解決する問題: 具体的にどんな課題に対応するのか
- 成功指標: どうなれば「成功」と言えるのか
- 機能の優先順位: 必須機能とあれば便利な機能の区別
例えば、金融機関では「顧客からの一般的な口座照会に自動応答する」というシンプルな目的から始め、後に「個人の財務状況に基づく投資アドバイス提供」へと機能を拡張することが検討できます。
ステップ2:最適な開発チームの編成
AIエージェントの作り方において次に重要なのは、適切なスキルセットを持つチーム編成です。理想的なチームは、以下のロールを含みます:
- 機械学習エンジニア: アルゴリズムの選択と最適化を担当
- データサイエンティスト: データの収集・分析・前処理を担当
- ソフトウェアエンジニア: システム統合とインフラ構築を担当
- ドメインエキスパート: 業界特有の知識と要件を提供
- UX/UIデザイナー: ユーザーインターフェースとエクスペリエンスを設計
興味深いのは、成功率の高いプロジェクトでは、技術者とビジネス部門の関係者が計画段階から密に連携している点です。これにより、技術的に可能なことと実際のビジネスニーズのギャップを早期に埋めることができます。
ステップ3:トレーニングデータの収集とクリーニング
AIエージェントの性能は、学習に使用するデータの質と量に直接左右されます。トレーニングデータに関する具体的な戦略が必要です:
- データソースの特定: 社内システム、公開データセット、サードパーティのデータなど
- データ収集メカニズム: 自動収集、手動入力、APIを通じた取得など
- データ品質の基準: 精度、関連性、最新性、多様性、法的遵守など
例えば、医療AIエージェントは、初期のモデルでは単一の病院のデータだけを使用するだけだと、地域特有の症例パターンにバイアスが出てしまうでしょう。データソースを10の異なる地域の病院に拡大すれば、診断精度をさらに向上できるはずです。
ステップ4:適切なAIテクノロジーとツールの選択
AIエージェントの作り方において、使用するテクノロジーとツールの選択は、エージェントの能力と制約を決定づけます。以下の要素に基づいて選択します:
- 言語処理能力: LLM(大規模言語モデル)関連のライブラリの選定
- 推論エンジン: ルールベースか機械学習ベースか
- 統合の容易さ: 既存システムとの連携方法
- スケーラビリティ: 将来の需要増大に対応可能か
例えばHugging Face Transformersなどのライブラリは、大規模言語モデルの多用なモデル選定や強化に特化したツールとして広く活用されています。
Thought→Action→Pause→Observation→Answerサイクルの実装方法
ステップ5:ReActパターンによるAIエージェントの設計

AIエージェントの作り方で特に注目すべきは、ReActパターン(Reason + Act)です。このパターンは推論と行動を組み合わせることで、AIエージェントの能力を格段に向上させる設計手法です。
ReActパターンの実装ステップ:
- Thought(思考): 質問やタスクについて推論するプロセス
- Action(行動): 利用可能なツールやAPIを使って具体的なアクションを実行
- Pause(一時停止): アクションの実行結果を待つ状態
- Observation(観察): アクションの結果を観察して情報を収集
- Answer(回答): 収集した情報に基づいて最終的な回答を生成
このパターンの強みは、AIが考える過程と行動する過程を明示的に分離していることです。これにより、推論の質が向上し、複雑な問題解決能力が強化されます。
ReActパターンの実装例
ReActパターンをPythonで実装する際の基本構造は以下のようになります:
import openai
import re
import httpx
class AIAgent:
def __init__(self, system=""):
self.system = system
self.messages = []
if self.system:
self.messages.append({"role": "system", "content": system})
def __call__(self, message):
self.messages.append({"role": "user", "content": message})
result = self.execute()
self.messages.append({"role": "assistant", "content": result})
return result
def execute(self):
completion = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=self.messages
)
return completion.choices[0].message.content
# ReActパターンのプロンプト設計
prompt = """
あなたは「思考、行動、一時停止、観察」のループで実行されます。ループの終わりには回答を出力します。「思考」を使って質問について考えたことを説明してください。「行動」を使って利用可能なアクションのいずれかを実行し、その後「一時停止」と返します。「観察」はそれらのアクションを実行した結果になります。
あなたが利用できるアクションは以下の通りです:
計算: 例 calculate: 4 * 7 / 3
ウィキペディア: 例 wikipedia: France
検索: 例 search: latest news
"""
# アクションのパターンマッチング
action_re = re.compile('^Action: (\w+): (.*)')
# 各種アクションの実装
def wikipedia(query):
# Wikipediaからの情報取得ロジック
pass
def calculate(expression):
# 計算処理ロジック
return eval(expression)
def search(query):
# 検索ロジック
pass
# 使用可能なアクションの登録
available_actions = {
"wikipedia": wikipedia,
"calculate": calculate,
"search": search
}
# クエリ処理メイン関数
def process_query(question, max_turns=5):
i = 0
agent = AIAgent(prompt)
next_prompt = question
while i < max_turns:
i += 1
result = agent(next_prompt)
# アクションを検出
actions = [action_re.match(a) for a in result.split('\n') if action_re.match(a)]
if actions:
action, action_input = actions[0].groups()
if action not in available_actions:
raise Exception(f"Unknown action: {action}: {action_input}")
# アクションを実行し、結果を観察
observation = available_actions[action](action_input)
next_prompt = f"Observation: {observation}"
else:
# 最終的な回答を返す
return result
この例では、AIエージェントは問題を解決するために、思考と行動を繰り返しながら最終的な回答に到達します。例えば「パリの人口は?」という質問に対して:
- Thought: パリはフランスの首都なので、まずWikipediaで情報を調べよう
- Action: wikipedia: Paris
- Pause: (Wikipedia APIからの応答を待つ)
- Observation: パリの人口は約215万人(市域)、広域圏では1200万人以上
- Answer: パリの人口は市域で約215万人、広域圏では1200万人以上です
この実装により、AIエージェントは単一の応答だけでなく、情報収集と推論のプロセス全体を通じて、より正確で詳細な回答を提供できるようになります。
ステップ6:AIエージェントの開発とテスト
設計が完了したら、実際のコーディング、統合、そしてテストフェーズに移行します:
- プロトタイプ開発: 最小限の機能を持つ初期バージョンを構築
- ユニットテスト: 個々のコンポーネントの動作確認
- 統合テスト: システム全体の連携確認
- ユーザーテスト: 実際のユーザーによる使用テスト
開発前にエージェントの振る舞いを詳細に文書化し、それに基づいてテストケースを作成することが、品質向上の鍵となっています。また、AIエージェントの作り方においては、徐々に機能を追加していく「イテレーティブ・アプローチ」が推奨されています。
トレーニングデータの収集とクリーニングの具体的手法
ステップ7:データの前処理と品質向上
AIエージェントのトレーニングデータの処理は、成功への重要な鍵です。具体的な手法として以下が挙げられます:
1. データ収集の多様化
単一のソースに依存せず、複数の視点からデータを収集することが重要です:
- 内部データ: 会社のCRM、メール、チャットログなど
- 公開データセット: KaggleやHugging Face Datasetsなど
- 合成データ: 既存データをベースに生成した追加データ
例えば、金融AIエージェントの開発では、実際の顧客問い合わせデータに加えて、金融専門家が設計した仮想シナリオを追加することで、レアケースへの対応能力が向上させることができるでしょう。
2. データクリーニングの自動化と人間レビュー
AIエージェントの作り方において、データクリーニングは地味ながら極めて重要なプロセスです:
- 重複の削除: 同一または非常に類似したデータポイントの除去
- 異常値の検出: 統計的手法による外れ値の特定
- 欠損値の処理: 適切な補完または除外
- 標準化・正規化: 一貫した形式への変換
3. データ拡張テクニック
トレーニングデータが限られている場合、以下のデータ拡張テクニックが有効です:
- パラフレージング: 同じ内容を異なる表現で言い換え
- バック・トランスレーション: 別言語に翻訳後、再び元の言語に戻す
- ノイズ追加: 意図的に小さなバリエーションを加える
- 合成データ生成: AIを使って新しいデータを生成
実装のポイント:継続的な学習とフィードバックループ
AIエージェントの作り方で見落とされがちな点は、デプロイ後の継続的な学習メカニズムです。最も効果的なAIエージェントは、初期トレーニングだけでなく、実際の使用から学習し続ける仕組みを持っています。
- ユーザーフィードバックの収集: 「この回答は役に立ちましたか?」などの簡単な評価
- プロンプトのLLM as a Judge: Langfuseなどで行うプロンプトデータの評価
- 人間によるレビュー: 特定の応答の質を専門家が評価
- A/Bテスト: 異なるバージョンのエージェントの効果を比較
- 定期的な再トレーニング: 新しい傾向やパターンを学習
最初のデプロイを「学習の始まり」と位置づけ、継続的な改善サイクルを確立することが重要です。これにより、時間とともにパフォーマンスが向上し、ユーザーのニーズに合わせて進化していくAIエージェントを構築できます。
次のセクションでは、AIエージェントの構築において避けられない課題であるリアルタイム処理とスケーラビリティの問題に焦点を当て、これらの壁を突破するための具体的な手法を解説します。
失敗しないAIエージェント構築術 – リアルタイム処理とスケーラビリティの壁を突破

AIエージェントの作り方を検討する多くの企業や開発者が直面する大きな壁が、「リアルタイム処理」と「スケーラビリティ」です。特に本番環境で実用的なAIエージェントを運用するには、これらの課題を克服することが必須となります。このセクションでは、AIエージェント構築において避けられないこれらの技術的ハードルを突破するための具体的な戦略と実践的なアプローチを解説します。
データ品質が低い場合の対処法と多様なデータソースの活用戦略
AIエージェントの品質は使用するデータの質に直結します。しかし、現実には理想的なデータセットを手に入れることは稀です。低品質データの問題を解決できるかどうかが、AIエージェント作り方の成功と失敗を分ける分岐点となります。
低品質データへの対処法
- データクリーニングの自動化パイプライン
- 低品質データの問題は、自動化されたクリーニングパイプラインで効率的に対処できます。
- 半教師あり学習アプローチ
- データ量が限られている場合、少量のラベル付きデータと大量の未ラベルデータを組み合わせる半教師あり学習が非常に効果的です。
- シンセティックデータ生成
- 実データが不足している場合や、特定のエッジケースをカバーするために、AIを使って合成データを生成するアプローチも効果的です。
多様なデータソースの戦略的活用
AIエージェントの作り方において、単一データソースへの依存は大きなリスクです。以下の戦略で多様なデータソースを組み合わせることが重要です:
- ドメイン固有データと一般データの融合
- 例えば、カスタマーサポートAIエージェントでは、一般的な会話データセットと、自社特有のFAQやサポート記録を組み合わせることで、汎用性と専門性の両立が可能になります。
- マルチモーダルデータの活用
- テキストだけでなく、音声、画像、センサーデータなど複数の形式のデータを組み合わせることで、AIエージェントの理解力と応答品質が大幅に向上します。ヘルスケア分野では、患者の記述データと生体センサーデータを組み合わせたAIエージェントが、テキストのみのシステムより高い精度で健康リスクを予測できる可能性があります。
- クラウドソーシングによるデータ強化
- 特に初期段階で十分なデータがない場合、クラウドソーシングプラットフォームを活用して特定の条件に合うデータを収集する戦略も有効です。
エッジコンピューティングとクラウドベース開発の使い分け

AIエージェントの作り方において、計算リソースの配置戦略は非常に重要です。特にリアルタイム応答が求められるケースでは、エッジコンピューティングとクラウドベースのアプローチを適切に組み合わせることが鍵となります。
エッジコンピューティングの活用ケース
以下のような状況では、AIエージェントの処理をエッジ(デバイスや近接サーバー)で行うことが有利です:
- 低レイテンシーが必須の応用
- 例えば、自動運転車のAIエージェントでは、障害物検出と回避判断に100ミリ秒未満の応答時間が要求されます。このようなケースでは、クラウドへの往復通信が不可能であり、エッジでの処理が必須となります。
- インターネット接続が不安定な環境
- 遠隔地や移動中の使用など、常時接続が保証されない環境では、エッジコンピューティングが適しています。農業モニタリングAIエージェントは、接続のない農場でもセンサーデータを分析し適切な判断を下せるよう、エッジデバイスに最適化されたモデルを実装する必要があります。
- プライバシー要件の高いアプリケーション
- 医療データや個人識別情報を扱うAIエージェントでは、データをクラウドに送信せず、エッジで処理することでプライバシーリスクを軽減できます。医療診断支援システムでは、患者データがローカルデバイスを離れることなく分析できる設計を採用し、規制コンプライアンスを確保することができます。
クラウドベース開発の最適活用
一方、以下のようなシナリオではクラウドベースのAIエージェント開発が有利です。
- 計算リソースを大量に必要とするモデル
- 大規模言語モデル(LLM)を活用したAIエージェントの場合、そのサイズとリソース要件からクラウド上での実行が現実的です。顧客対応チャットボットの例では、GPT系モデルをAzureクラウド上で実行することで、複雑な質問にも自然な対応が可能になっています。
- 多数のデータソースとの統合が必要なケース
- 様々なシステムやデータベースと連携する必要があるAIエージェントでは、クラウドのインテグレーション機能が有用です。金融アドバイザリーAIエージェントは、10以上の異なる金融データソースと連携して包括的な分析を提供する設計にできますが、これはクラウドベースの統合があってこそ実現可能です。
ハイブリッド戦略:最良の両取り
多くの成功しているAIエージェント開発プロジェクトでは、エッジとクラウドのハイブリッド戦略を採用しています:
- モデルの分割: 軽量な前処理や緊急判断はエッジで、複雑な分析はクラウドで実行
- 段階的処理: 一次回答をエッジで即時提供し、詳細な分析はクラウドからバックグラウンドで補完
- 選択的クラウド通信: 必要な場合のみクラウドとデータを同期
例えば小売業のインベントリ管理AIエージェントでは、在庫スキャンと基本的な分析は店舗内のエッジデバイスで処理し、需要予測と全店舗の在庫最適化はクラウドで実行するハイブリッドアプローチを採用できます。これにより、リアルタイム性と分析の深さを両立させることができるでしょう。
マイクロサービスアーキテクチャでスケーラビリティを確保する方法
AIエージェントの作り方において、ユーザー数や処理量の増加に対応できるスケーラビリティは不可欠です。モノリシックな設計よりもマイクロサービスアーキテクチャを採用することで、より柔軟なスケーリングが可能になります。
マイクロサービスの基本設計原則
AIエージェントをマイクロサービスとして設計する際の基本原則として、特に単一責任の原則が重要です。
各マイクロサービスは、AIエージェントの特定の機能(例:LLMとの通信、外部ツールの利用など)に特化させます。AIエージェントは複数のツールを使いこなすため、それぞれを別々のサービスとして実装することで、各コンポーネントの独立した改善とスケーリングが可能になるでしょう。
また、プロンプトの設計についても、それぞれのプロンプトを疎結合にしておき、責務を分離することで管理しやすくなります。
キャッシュ戦略とパフォーマンス最適化
スケーラビリティを高めるもう一つの重要な要素が、効果的なキャッシュ戦略です:
- マルチレベルキャッシュ
AIエージェントの応答パターンを分析し、頻繁なクエリ結果をキャッシュすることで、計算リソースを節約できます。プロンプトキャッシュ、ローカルメモリキャッシュ、分散キャッシュ(Redis)、CDNキャッシュという4層のキャッシュ戦略を実装し、レスポンスタイムを平均以下に抑えることに成功することができるでしょう。
- モデル最適化と量子化
デプロイするAIモデル自体を最適化することも重要です。エッジデバイス向けAIエージェントでは、モデルの量子化(精度を若干犠牲にしてサイズと計算量を削減)や蒸留(より小さなモデルに知識を転移)を適用することができます。これにより、元のパフォーマンスを維持しながらモデルサイズを削減し、より多くのユーザーに対応できるようになりました。
AIエージェントの作り方においてリアルタイム処理とスケーラビリティの課題を克服するには、データ品質の向上、エッジとクラウドの適切な使い分け、そしてマイクロサービスアーキテクチャの採用が鍵となります。次のセクションでは、これらの知見を実際のビジネスケースに適用した成功事例と、避けるべき失敗パターンを紹介します。
実例で学ぶAIエージェントの作り方 – 3つのユースケースと避けるべき4つの失敗

理論や技術解説も重要ですが、実際のビジネスシナリオでAIエージェントがどのように構築され、どんな結果をもたらしたのかを知ることで、AIエージェントの作り方をより具体的に理解できます。
この章では、異なる業界でのAIエージェントの作成のケース集と、多くのプロジェクトで繰り返される失敗パターンを詳しく解説します。これらのケースから学ぶことで、自社のAIエージェント開発の成功率を高めることができるでしょう。
顧客サポート自動化の事例とROI
ケース1:グローバル通信企業のAIエージェント導入事例
例えば、大手通信企業は、月間200万件以上の問い合わせに対応するカスタマーサポート部門の効率化を目指し、AIエージェントの作り方を徹底的に研究するとします。その場合は次のような技術的な実装を目指すと良いでしょう。
特筆すべき技術的特徴
- 段階的な意図認識: シンプルな質問は軽量モデルで、複雑なケースは大規模モデルで処理する二段階アプローチ
- コンテキスト記憶: 顧客の過去の問い合わせ履歴とサービス契約情報を統合した会話コンテキスト管理
- エスカレーション予測: AIが解決できない問題を早期に検出し、シームレスに人間オペレーターに引き継ぐ機能
AIエージェント作り方のキーポイント
このケースから学べる重要な教訓は、データ収集を早期に開始することの重要性です。開発の3ヶ月前から、同社はすべての顧客問い合わせを将来のトレーニングデータとして構造化して保存することが大事です。これにより、AIエージェントのトレーニングに実際の会話データを活用して、精度の高いエージェントの構築に役立てることができます。
ケース2:医療診断支援AIエージェントの開発プロセス
大学病院と技術企業の協働開発事例
ある大学病院と技術スタートアップの共同チームは、放射線科医の診断をサポートするAIエージェントを開発します。このプロジェクトは、AIエージェントの作り方における医療分野特有の課題と解決策を示す好例です。
段階的開発プロセス
このAIエージェントは、以下の8段階で開発することが可能です。
- 臨床ニーズの特定: 放射線科医と緊密に協力し、実際のワークフローを詳細に分析
- データ収集と匿名化: 匿名化された画像診断結果を収集
- モデルアーキテクチャの選定: 画像分析には特化ビジョンモデル、文脈理解と所見生成にはLLMを活用するハイブリッドアプローチ
- 段階的トレーニング: 胸部X線画像から始め、徐々にCTやMRIに範囲を拡大
- ドメインエキスパートによる臨床検証: 放射線科医によるテスト評価を実施
- フィードバックループの確立: 医師のフィードバックを自動的に収集・分析する仕組みを構築
- 限定的デプロイと拡大: 最初は単一部門での使用から始め、成功を確認しながら他部門へ展開
技術的特徴と工夫
このAIエージェントの作り方で特に注目すべき点は、説明可能性(XAI)の実装です。医療分野では、AIの判断理由を医師が理解できることが不可欠です。以下のような工夫が求められるかもしれません。
- 注意マップの可視化: AIがどの画像領域に注目したかをヒートマップで表示
- エビデンスリンク: 診断提案と類似症例や医学文献を自動的にリンク
- 確信度スコア: 各診断提案に確信度スコアを付与し、医師の判断材料を提供
医療AIエージェントの作り方から学ぶ教訓
このプロジェクトの最大の教訓は、エンドユーザー(医師)を開発プロセス全体に深く関与させることの重要性です。単なる意見聴取ではなく、5名の放射線科医がプロジェクトチームの正式メンバーとして参加し、開発の各段階で実践的なフィードバックを提供したことが成功の鍵です。
ケース3:金融市場分析AIエージェントの構築手法
資産運用会社のトレーディングサポートAIエージェント
例えば、グローバル資産運用会社は、トレーダーの意思決定をサポートするAIエージェントを開発できます。このエージェントは、膨大な市場データをリアルタイムで分析し、トレーディング機会を特定することを目的とします。
AIエージェント作り方の特徴的アプローチ
このプロジェクトは、従来のAIエージェント開発と異なり、マルチエージェントアーキテクチャを採用します。
- 専門化されたサブエージェント:
- マクロ経済分析エージェント: 経済指標と中央銀行の動向を追跡
- センチメント分析エージェント: ニュース、ソーシャルメディア、企業発表の感情分析
- テクニカル分析エージェント: 価格チャートとパターン認識
- ファンダメンタル分析エージェント: 企業財務データの分析
- 調整エージェント: 各専門エージェントの分析結果を統合し、一貫した推奨事項を生成
- パーソナライズエージェント: トレーダー個人の取引履歴と嗜好に基づき、推奨事項をカスタマイズ
重要なポイント:ReActパターンの基盤の実装
このAIエージェントの作り方で特筆すべきは、多段階ReActパターンの実装です。従来のThought→Action→Pause→Observation→Answerサイクルを拡張し、各サブエージェントが独自の思考プロセスを持ちながら協調する仕組みを構築します。
# 調整エージェントの簡略化された実装例
def coordinate_agents(query, market_data):
# 1. 各専門エージェントに問い合わせを分配
macro_thoughts = macro_agent.think(query, market_data)
sentiment_thoughts = sentiment_agent.think(query, market_data)
technical_thoughts = technical_agent.think(query, market_data)
fundamental_thoughts = fundamental_agent.think(query, market_data)
# 2. 調整エージェントが各サブエージェントの思考を統合
coordinator_thought = f"""
マクロ経済的視点: {macro_thoughts}
市場センチメント: {sentiment_thoughts}
テクニカル分析: {technical_thoughts}
ファンダメンタル分析: {fundamental_thoughts}
これらの情報を総合すると...
"""
# 3. 調整エージェントが行動計画を立案
action_plan = plan_actions(coordinator_thought)
# 4. 必要に応じて追加情報を収集
if "need_more_info" in action_plan:
additional_data = fetch_additional_data(action_plan["data_requests"])
coordinator_thought += f"\n追加情報の分析: {additional_data}"
# 5. 最終的な推奨事項を生成
final_recommendation = generate_recommendation(coordinator_thought)
return final_recommendation
金融AIエージェントから学ぶ教訓
このケースから得られる主要な教訓は、複雑な問題領域では単一のAIエージェントではなく、専門化されたマルチエージェントアプローチが有効ということです。また、段階的なリリース戦略(最初は限られた資産クラスに対して小規模に開始し、成功を確認しながら拡大)が、リスクを最小化しながらもスムーズな導入を可能にできるでしょう。
避けるべき開発上の4つの致命的ミス
多くのAIエージェント開発プロジェクトが失敗していますが、その理由は共通のパターンに集約されます。以下に、AIエージェントの作り方における致命的な4つのミスを解説します。
1. 不明確な目的定義と過度な野心
症状: プロジェクト開始時に「何でもできるAIアシスタント」のような漠然とした目標設定
AIエージェントの作り方で最も致命的なのは、明確な目的と範囲の定義なしに開発を始めることです。
対策:
- 最初は単一の明確なユースケースに焦点を当てる
- 測定可能な成功基準を設定する
- 「MVP(最小実行製品)」の考え方を採用し、段階的に機能を拡張する
初期段階で非常に限定的な機能から始め、実績を積み上げながら徐々に機能を拡張することが重要です。
2. データの質と量への過小評価
症状: トレーニングデータの収集と品質管理に十分なリソースを割り当てない
AIエージェントの作り方における最大の技術的失敗は、データの重要性を過小評価することです。
対策:
- プロジェクト予算の30〜40%をデータ収集と準備に割り当てる
- データ品質に関する明確な基準を設定する
- 必要に応じて合成データや転移学習を活用する
プロジェクト開始前に、必要なデータ量の10%程度のサンプルでプロトタイプを構築し、データの質と量の要件を検証するプラクティスが推奨することができます。
3. テクノロジースタックの誤選択
症状: 会社の技術力や実際のユースケースに適合しないテクノロジーの選択
誤ったフレームワークや技術スタックの選択は、AIエージェントの作り方において致命的です。ある中小企業は、社内にPython開発者がいなかったにもかかわらず、Pythonベースのカスタムフレームワークを選択。結果として、外部コンサルタントへの依存度が高まり、コストが膨れ上がってしまいます。
対策:
- 社内の技術スキルセットを正直に評価する
- ユースケースの要件(リアルタイム性、精度、説明可能性など)を明確にする
- 複数の選択肢をプロトタイプで比較検証する
4. ユーザーフィードバックの軽視
症状: 開発が完了するまでエンドユーザーの関与がない
AIエージェントの作り方における非技術的なミスで最も多いのが、実際のユーザーを開発プロセスから遠ざけることです。エンドユーザーの理解や業務の理解がAIエージェントの自律的な高度な機能の実装に大きく影響します。
対策:
- 開発の最初期段階からエンドユーザーを関与させる
- 「ウィザードオブオズ」テスト(人間がAIの役割を演じる)から始める
- 定期的なユーザビリティテストを計画する
失敗から学ぶ成功への道
これらの失敗から学べる最大の教訓は、AIエージェントの作り方において技術的な側面だけでなく、人的要素、プロセス、組織的な準備が同等に重要だということです。以下のプロセスを大事にする必要があります。
- 段階的アプローチ: 小さく始め、成功を積み上げる
- クロスファンクショナルチーム: 技術者だけでなく、ビジネス、UX、ドメイン専門家を含める
- リスクベースの計画: 最大のリスク要因を特定し、それに対処する戦略を優先する
- 定期的な成果発表: 開発過程で定期的に成果を示し、ステークホルダーの継続的なサポートを確保する
AIエージェントの作り方において、これら失敗を回避するための投資は、プロジェクト全体のコストのほんの一部ですが、成功確率を劇的に高める効果があります。
総括:実践から学ぶAIエージェント構築のエッセンス
3つの成功事例と4つの失敗パターンから見えてくるのは、AIエージェントの作り方に「魔法の公式」は存在しないということです。しかし、明確な目的設定、適切なデータ戦略、段階的な開発アプローチ、ドメインエキスパートの関与、そして継続的なユーザーフィードバックという共通の成功要因は存在します。
産業や用途に関わらず、成功したAIエージェントプロジェクトは、技術的な卓越性と実用的なビジネス価値のバランスを常に意識しています。最終的に、AIエージェントの真の価値は、それが解決する具体的な問題と、ユーザーの日常にもたらす変化によって測定されるのです。
人間とAIの最適な協働を実現するAIエージェントの作り方を極めることは、今後のビジネス競争力の核となるでしょう。これらの事例と教訓が、あなたの組織におけるAIエージェント開発の道標となることを願っています。
調査手法について
こちらの記事はグラフAIリサーチプラットフォームのSnorbeを使って作られています。Snorbeは研究開発・新規事業向けの調査テーマに応じた幅広い項目のオートリサーチや、ナレッジグラフの構築、構造化レポートの生成ができるAIリサーチツールです。
Screenshot
調査したいテーマを入力するだけで、AIが深堀りすべき観点や広げるべき調査項目をレコメンドしながら、自動でリサーチを進めます。収集した情報はナレッジグラフとして蓄積され、未調査領域(ホワイトスペース)を可視化しながら調査の網羅性を高めていけます。
また、観点マトリクスを30秒・構造化レポートを10分で自動生成する機能があり、出典付きのレポートをMarkdown/PDF形式でエクスポートできます。調査の元データも保存されるため、ファクトチェックや社内共有も容易です。
ご利用をご希望の方は、こちらよりお申し込みください。
また、グラフAIを活用した社内ナレッジ管理や、研究開発・新規事業のリサーチ支援、セルフホスト導入のご相談も受け付けています。お困りの方はお気軽にご連絡ください。
市場調査やデスクリサーチの生成AIエージェントを作っています 仲間探し中 / Founder of AI Desk Research Agent @deskrex , https://deskrex.ai


コメント