
Embodied AIの正体:「ただのロボット」ではなく「物理世界を学習するシステム」
最近、X(旧Twitter)やYouTubeで、人間そっくりのロボットがコーヒーを淹れたり、倉庫で荷物を運んだりする動画を見かけることが増えました。「すごい時代になったな、ロボット工学が急激に進化したんだな」と感じる方も多いでしょう。
しかし、これらの動きを深く追っていくと、どうやらこれは単なる「ロボット工学の進化」ではないような気がしてきました。私たちが目にしているのは、AIがデジタルの殻を破り、物理世界そのものを学習し始めた「新しいデータ産業」の幕開けかもしれません。
本記事では、いま注目を集める「Embodied AI(身体性AI)」の正体について、技術的な定義だけでなく、なぜ今GoogleやNVIDIAといったテック企業がこぞって参入しているのか、その背景にある構造的な変化を紐解いていきます。
「ChatGPTに身体がついた」だけではない

まず、Embodied AI(エンボディドAI)とは何でしょうか。言葉の通り「身体(Body)を持ったAI」のことですが、その本質は「身体の形」ではなく「仕組み」にあります。
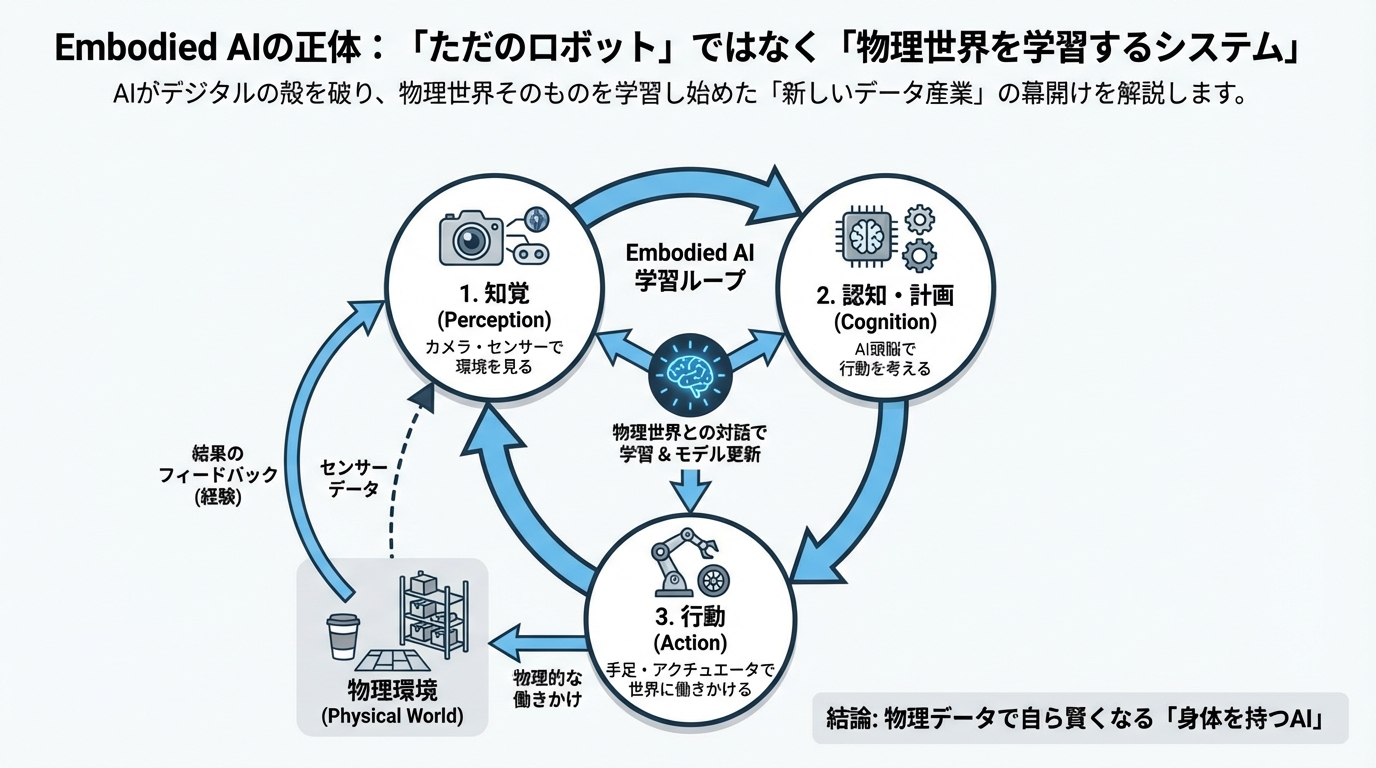
従来のAI、たとえばChatGPTや画像生成AIは「Disembodied AI(身体を持たないAI)」と呼ばれます。彼らはインターネット上のテキストや画像を読み込んで賢くなりますが、自分自身で物理世界に触れることはできません。対してEmbodied AIは、以下の3つのサイクルを回すシステムとして定義されます。
- 知覚(Perception):カメラやセンサーで環境を見る
- 認知・計画(Cognition):何をするべきか頭脳(AI)で考える
- 行動(Action):手足や車輪(アクチュエータ)を動かして世界に働きかける
そして重要なのが、行動した結果、世界がどう変わったかを再び「知覚」し、そこから学習するという「ループ(循環)」です。
例えば、ロボットがコップを掴もうとして失敗し、倒してしまったとします。従来のプログラムされたロボットなら単なるエラーですが、Embodied AIは「この力加減だと倒れるんだな」と学習し、次の行動を修正します。この「物理世界との対話を通じて賢くなる」という点が、単なる自動化ロボットとの決定的な違いです。
ロボットは「物理世界のウェブブラウザ」かもしれない
では、なぜ今、この技術に莫大な資金が集まっているのでしょうか。
もちろん、人手不足の解消や危険作業の代替といったニーズはあります。しかし、テック企業の動きを見ていると、もっと別の大きな動機があるように思えてなりません。それは、ロボットを「物理世界のデータを収集するためのデバイス」として見ているという点です。
インターネット上のテキストデータで学習したLLM(大規模言語モデル)は、驚異的な知能を獲得しました。しかし、ネット上には「卵を割る力加減」や「散らかった部屋での歩き方」といった、言葉にしにくい身体的なデータは落ちていません。AIがさらに賢くなる(汎用人工知能にづく)ためには、物理世界のデータがどうしても必要なのです。
この仮説を裏付けるような興味深い動きがあります。ヒューマノイドロボット開発の注目株であるFigure AIは、世界的な投資会社Brookfieldと提携しました。Brookfieldは物流施設や住宅など膨大な不動産を持っています。Figureはこの提携により、研究室の中だけでなく、実際の生活空間や倉庫でロボットを動かし、そこから得られる膨大な「実世界データ」を独占的に収集しようとしています。
これは、Googleがかつて検索エンジンのクローラーを使ってウェブ上のデータを集めたように、ロボットを使って物理世界のデータをインデックス化しようとしている──そんなふうに見えないでしょうか。
テック巨人が「つるはし」を売る理由
この「データ産業としてのロボット」という視点に立つと、NVIDIAのような半導体メーカーが熱心な理由もクリアになります。
NVIDIAは最近、ヒューマノイドロボット向けのコンピュータ「Jetson Thor」や開発プラットフォームを発表し、ロボットメーカーへの支援を強化しています。彼らは自社でロボットを作って売るのではなく、世界中のロボット開発者が使う「頭脳」と「シミュレーション空間」というインフラを押さえに来ているのです。
また、中国でもこの動きは国家レベルで加速しています。中国政府はEmbodied AIを次の成長エンジンと位置づけ、安価なハードウェア製造能力と豊富な実証フィールドを武器に、データ収集の覇権を争っています。世界の人型ロボット企業の半数以上が中国拠点であるというデータもあり、まさに国を挙げたデータ獲得競争の様相を呈しています。
そして「言葉」と「身体」が繋がる
ここまでの話を整理すると、Embodied AIの正体は以下のように言えるのではないでしょうか。
- 単なる便利な機械ではなく、環境と相互作用して自ら学習するシステムである。
- AIがデジタルの限界を突破するために必要な「物理データ」を獲得するための身体である。
「ロボットがコーヒーを淹れる」という現象の裏側では、AIが物理法則や人間の生活習慣をデータとして吸い上げ、知能をアップデートし続けています。
さて、ここで一つ疑問が湧きます。デジタルの脳(AI)はどうやって物理的な身体(ロボット)をこれほど器用に操れるようになったのでしょうか? 実はそこには、「言葉で考えて、頭の中のシミュレーションで練習する」という、人間そっくりの驚くべき技術的ブレイクスルーがありました。
次章では、このEmbodied AIの知能の中核にある「VLA(視覚・言語・行動)」モデルと、頭の中で未来を予知する「世界モデル」という最新技術について、噛み砕いて解説していきます。
技術の最前線:言葉で考え、シミュレーションで練習するAI
前章では、Embodied AIが「物理世界のデータを食べるシステム」だという話をしました。でも、ここで素朴な疑問が湧いてきます。デジタルの世界で育ったAI(ChatGPTのような脳)が、どうやって重さや摩擦のある物理的な身体を、これほど器用に動かせるようになったのでしょうか?
どうやら、その秘密は「人間の脳の使い方の模倣」にあるようです。私たちが何か新しい動作を覚えるとき、頭の中で考え、イメージし、練習しますよね。最新のロボットも、まさにそれと同じことを「言葉」と「想像」を使って行っているのです。
本章では、ロボットの頭の中で起きている2つの技術革新、「VLA(視覚・言語・行動)」と「世界モデル」について、できるだけ噛み砕いて見ていきましょう。
AIは「言葉」を「筋肉の動き」に翻訳する

昔のロボットを動かすには、「腕を右に30度、肘を45度曲げる」といった厳密なプログラミングコードが必要でした。しかし、今のAIロボットには「その辺のゴミを捨てておいて」と言うだけで通じます。
これを可能にしているのが、「VLA(Vision-Language-Action)」と呼ばれる技術です。これは簡単に言うと、「言葉の指示」を「身体の動き」に翻訳する通訳機のようなものです。
これまでのAI(LLM)は、「ゴミを捨てて」と言われれば、「ゴミを見つける→掴む→ゴミ箱へ移動する→離す」という手順(レシピ)を考えることは得意でした。しかし、具体的に「指にどのくらいの力を入れれば空き缶が潰れないか」までは分かりません。
そこでVLAの登場です。VLAは、画像(Vision)と言葉(Language)だけでなく、実際のロボットの行動データ(Action)をセットで学習しています。そのため、「空き缶を掴む」という言葉を受け取ると、それを「指のモーターに送るべき電気信号」へと瞬時に変換できるのです。
いわば、AIが「頭でっかちな評論家」から、「実際に手足を動かせる実務家」へと進化した瞬間と言えるかもしれません。
「頭の中のシミュレーター」で未来を予知する
しかし、言葉で指示通り動けるだけでは不十分です。物理世界には「取り返しがつかない」という厳しさがあるからです。ChatGPTが文章作成でミスをしても書き直せば済みますが、ロボットがコップを掴み損ねて割ってしまったら、元には戻せません。
そこで研究者たちが開発したのが、「世界モデル(World Models)」という技術です。これは一言で言えば、ロボットの頭の中に作られた「物理世界のシミュレーター」です。

人間も、初めてのスポーツに挑戦するとき、実際に動く前に「こう動いたらボールはどう飛ぶかな?」と頭の中でイメージトレーニングをしますよね。世界モデルを持つAIも同じことをします。
- 想像する:実際に行動する前に、頭の中のシミュレーターで「もしこう動いたらどうなるか」を何通りも試す。
- 予知する:「あ、この角度だとコップが倒れるな」「こっちなら大丈夫そうだ」と、数秒先の未来を予測する。
- 実行する:安全だと確信したプランだけを現実の身体で実行する。
最新の研究では、VLA(言葉で考える脳)が「やりたいこと」を提案し、世界モデル(物理を知る脳)が「それが実行可能か」を検証するという、二重のチェック体制が主流になりつつあります。これによって、ロボットは初めての場所でも、まるで熟練者のように失敗の少ない動きができるようになってきたのです。
最大の壁:「ゲーム」と「現実」は微妙に違う
「言葉で動けて、シミュレーションで予習も完璧。ならもう実用化できるのでは?」
そう思いたくなりますが、実はここに、研究者たちを悩ませ続ける巨大な壁が立ちはだかっています。専門用語で「Sim-to-Real(シム・トゥ・リアル)ギャップ」と呼ばれる問題です。
頭の中のシミュレーション(Sim)では完璧に歩けたのに、現実(Real)でやってみると転んでしまう──。これは、私たちがゲームの中ならスーパープレイができるのに、現実のサッカーでは足がもつれてしまうのと似ています。
シミュレーターの中の世界は、あくまで数式で作られた近似値です。現実世界の「カーペットの微妙な摩擦」「ケーブルの硬さ」「照明のちらつき」「突発的な風」といった無数のノイズまでは、完全には再現できません。このわずかなズレ(Reality Gap)が、精密な作業においては命取りになるのです。
解決策は「現実から逆算してシミュレーターを作り直す」
この壁をどう乗り越えるか。最近の研究トレンドは、非常に面白いアプローチをとっています。「Real2Sim2Real(リアル・トゥ・シム・トゥ・リアル)」と呼ばれる手法です。
従来は「シミュレーターを頑張って現実に近づけよう」としていましたが、これには限界がありました。そこで発想を逆転させ、「現実世界で少しだけ動いてデータを集め、そのデータを使ってシミュレーターの方を書き換えてしまう」という方法が採られています。
例えば、「EmbodieDreamer」という最新の研究では、現実の映像や動きのデータを使い、シミュレーター内の「物理法則(摩擦係数など)」と「見た目(映像のリアルさ)」の両方を、現実にそっくりになるよう自動調整します。
- Real:現実で少し失敗データを集める。
- Sim:そのデータに合わせて、シミュレーターを「現実そっくり」に自動修正し、そこで猛特訓する。
- Real:特訓したAIを現実に書き戻す。
こうすることで、ロボットは「現実世界専用にカスタマイズされた脳内シミュレーター」を持つことになり、格段に器用さが増すのです。どうやら、人間が経験を通じて「勘」を修正していくプロセスを、AIも高速で回し始めているようです。
技術のピースは揃った、あとは「誰がやるか」
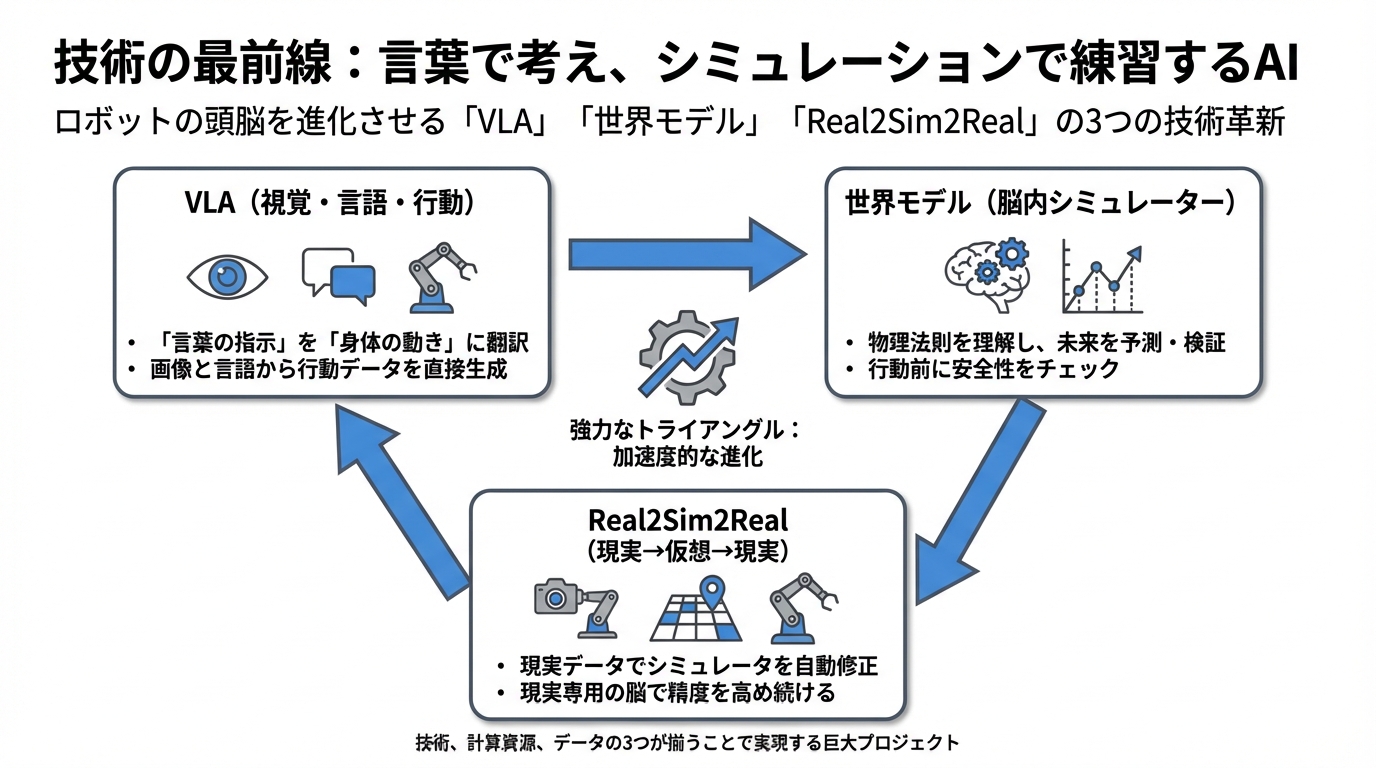
ここまでの話をまとめると、技術的には以下のような強力なトライアングルが出来上がりつつあります。
- VLA:言葉を理解し、指示を行動に変換する。
- 世界モデル:物理法則を理解し、未来を予測・検証する。
- Real2Sim2Real:現実データを使って、シミュレーションの精度を高め続ける。
この仕組みが回れば回るほど、ロボットは加速度的に賢くなっていきます。しかし、これを実現するには、「高度なAIモデル」だけでなく、「大量の計算資源(GPU)」と、「現実世界のデータ」の3つを同時に揃える必要があります。これは、大学の研究室レベルでは抱えきれないほど巨大なプロジェクトになりつつあります。
では、この巨大な山を実際に登ろうとしているのは誰なのでしょうか?
次章では、それぞれ全く異なるアプローチでこの頂を目指す3つの注目スタートアップ──垂直統合の「Figure」、現場主義の「Apptronik」、そして汎用脳を狙う「FieldAI」の戦略を解剖していきます。
スタートアップの戦略解剖:Figure、Apptronik、FieldAIの異なる登り方
前章で触れたように、「VLA(視覚・言語・行動)」や「世界モデル」といった技術のピースは出揃いました。しかし、これらを組み合わせて「本当に役に立つロボット」を作り、ビジネスとして成立させるのは、また別の次元の話です。
山頂は見えているけれど、そこに至るルートは一つではありません。実際、現在この市場をリードするスタートアップたちは、驚くほど異なる装備とルートでこの未踏峰に挑んでいます。
本章では、代表的な3社──「Figure」、「Apptronik」、「FieldAI」を取り上げ、それぞれの「登り方(戦略)」の違いを解剖していきます。どうやら彼らの戦い方を見ていると、Embodied AIという産業が、単なる技術競争から「データと資本の総力戦」へと変質しつつある姿が見えてきそうなのです。

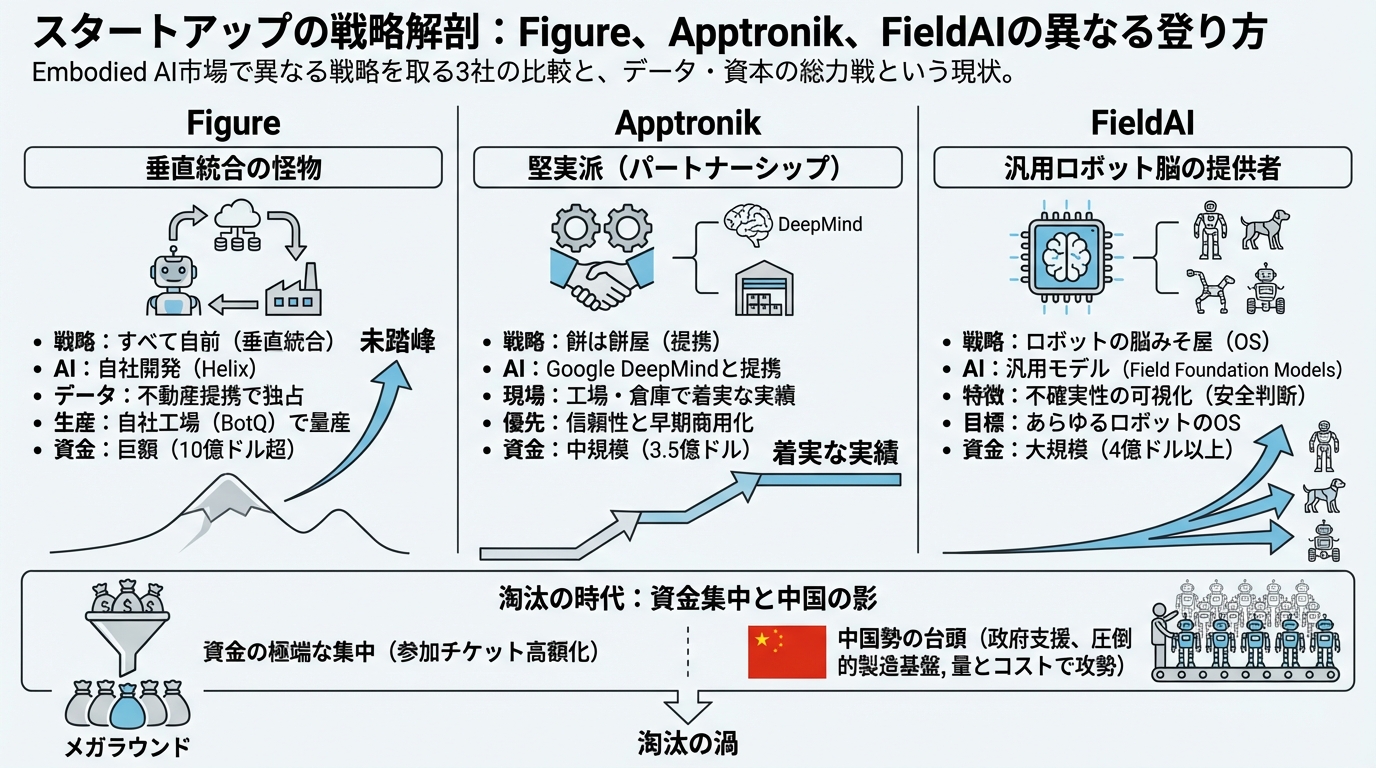
Figure:すべてを自前で揃える「垂直統合」の怪物
まず注目すべきは、今最も資金を集めているFigureです。彼らの戦略を一言で表すなら、「全部自分でやる(垂直統合)」でしょう。
多くのロボット企業が、AIモデルは他社製を借り、ハードウェア開発に集中する中で、Figureは異質の動きを見せています。彼らは当初OpenAIと提携していましたが、最近になってそれを解消し、AIモデルまでも自社開発(内製化)する道を選びました。
なぜそんな茨の道を行くのでしょうか? それは彼らが、ロボットの賢さは「独自のデータ」で決まると確信しているからかもしれません。
その証拠に、彼らは世界最大級の不動産投資会社であるBrookfieldと提携を結びました。これは、単に資金を出してもらうだけではありません。Brookfieldが持つ膨大な住宅や物流倉庫を、「ロボットの実地訓練場」として使う権利を手に入れたことを意味します。
- 場所の確保:実在する家や倉庫にロボットを送り込む。
- データの独占:そこでしか撮れない「生活のデータ」を吸い上げる。
- 知能の進化:そのデータで自社製AI(Helix)を鍛える。
- 量産:「BotQ」と呼ばれる自社工場でロボットを大量生産する。
このループを他社に依存せず、自社の中だけで高速回転させる。これこそがFigureの狙いです。シリーズCで調達した10億ドル超という巨額資金は、まさにこの「データと生産の要塞」を築くために使われているのです。
Apptronik:巨人の肩に乗り、現場で汗をかく「堅実派」
一方、Apptronikのアプローチは対照的です。彼らはテキサス大学の研究室をルーツに持ち、NASAとの共同開発経験もある「ロボット工学のプロ」集団です。彼らが選んだのは、「餅は餅屋」の戦略です。
彼らは自前でゼロからAIを作ることに固執せず、Google DeepMindと提携する道を選びました。世界最高峰のAI知能(DeepMind)を借りて、自分たちは得意な「身体作り(ハードウェア)」と「現場への適用」に集中するというわけです。
Apptronikが特に重視しているのは、「工場や倉庫」という構造化された環境での着実な実績作りです。例えば、メルセデス・ベンツの工場やGXO Logisticsの倉庫で、部品運びなどの地味ながら確実なタスクを行わせています。
- Figureが「家庭も含めた汎用的な未来」を夢見てインフラを作るのに対し、
- Apptronikは「明日の工場で確実に動くこと」を優先して信頼を積み上げる。
3.5億ドルという調達額はFigureに比べれば控えめですが、技術的な不確実性をパートナーシップで分散し、早期に商用化を目指すこの「堅実な登山ルート」は、多くの企業にとって導入のハードルを下げる安心材料になる気がします。
FieldAI:身体を持たない「汎用ロボット脳」の提供者
3社目のFieldAIは、さらにユニークです。彼らの本質はロボットメーカーというよりも、「ロボットの脳みそ屋」に近いかもしれません。
彼らが開発しているのは、「Field Foundation Models」と呼ばれる汎用的なロボット脳です。彼らの思想は、「身体の形が人型だろうが、犬型だろうが、車型だろうが、関係なく動かせる知能を作る」というものです。
特に面白いのは、彼らが「自信のなさ(不確実性)」を可視化することに注力している点です。
従来のAIは、分かっていないことでも自信満々に間違える(幻覚を見る)ことがありました。しかし物理世界でそれをやると事故になります。FieldAIの脳は、「ここは自信がないからゆっくり動こう」とか「この先は見えないから止まろう」といった判断ができるように設計されています。
4億ドル以上の資金を集めた彼らの戦略は、ハードウェアの競争には参加せず、あらゆるロボットにインストールされる「OS(オペレーティングシステム)」のポジションを狙っているように見えます。これは、パソコン業界で言うところのMicrosoft Windowsのような立ち位置を目指しているのかもしれません。
淘汰の時代:資金の集中と「中国」という巨大な影
こうして各社の戦略を見ていくと、Embodied AI市場が決して一枚岩ではないことが分かります。しかし、共通している残酷な事実もあります。それは、「勝負の参加チケットが高すぎる」ということです。
最近の投資動向を見ると、資金はこれら上位数社に極端に集中しています(メガラウンド)。ロボットの開発、工場の建設、データの収集には莫大なコストがかかるため、中途半端な規模のスタートアップは生き残るのが難しくなっているのです。
さらに、忘れてはならないのが中国勢の存在です。
アメリカのスタートアップが技術的な差別化で戦う一方で、中国企業は政府の強力な後押しと、圧倒的な製造基盤を武器に「量とコスト」で攻めてきています。世界の人型ロボット企業の半数以上が中国拠点であるというデータもあり、今後は「米国の先端技術 vs 中国の実装力・価格競争力」という構図がより鮮明になってくるでしょう。
さて、ここまで主要プレイヤーたちの華麗な戦略を見てきました。巨額の資金、賢いAI、そして未来的な工場。すべてが順調に進んでいるように見えます。
しかし、ニュースリリースの外側、実際の「現場」に目を向けると、そこにはまだ解決されていない泥臭い課題が山積みになっているようです。
次章では、BMW工場での事例などを通じて、「デモ動画の華やかさ」と「現場運用のリアル」のギャップについて、少し冷静な視点で深掘りしていきたいと思います。ヒューマノイドは本当に、明日から私たちの職場で働けるのでしょうか?
実装のリアルと未来:華やかなデモ動画の裏側にある「泥臭い課題」
前章まで、Embodied AIの華々しい可能性と、それを追いかけるスタートアップたちの野心的な戦略を見てきました。YouTubeを開けば、人間のように滑らかに動き、コーヒーを淹れたり荷物を運んだりするロボットの動画が溢れています。それらを見ていると、「もう未来は完成したのではないか」という錯覚に陥りそうです。
しかし、一歩引いて考えてみましょう。もし本当に技術が完成しているなら、なぜ私たちの職場や家庭には、まだ彼らがいないのでしょうか?
どうやら、きらびやかなデモ動画のフレームの外側には、まだ解決されていない「泥臭い現実」が広がっているようです。本稿の締めくくりとして、この技術が社会に実装されるための「リアルな条件」について、少し冷静に考えてみたいと思います。
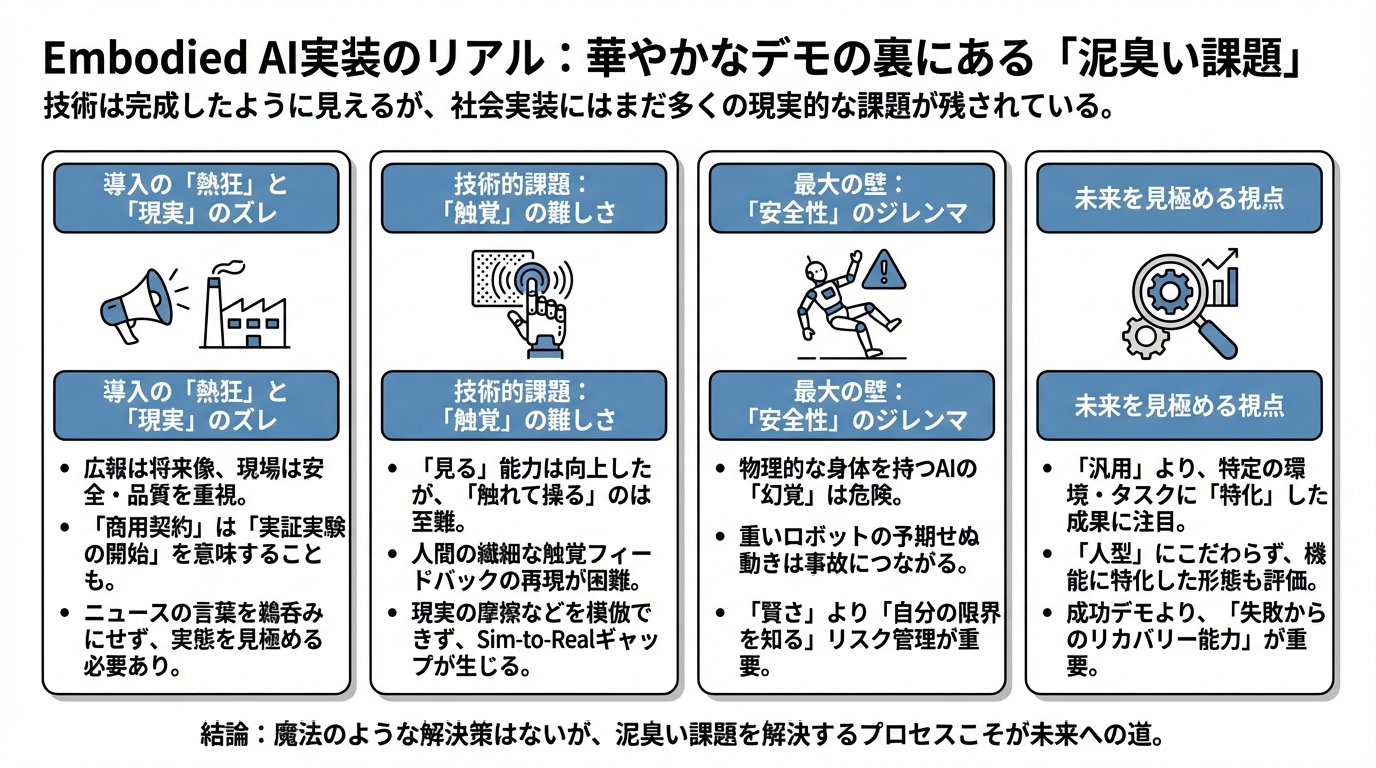
広報の「熱狂」と現場の「冷静」:BMW工場の事例から

産業界における導入事例として大きな注目を集めたのが、BMWとFigureの提携です。ヒューマノイドロボットが自動車工場で働く──まさに未来の到来を感じさせるニュースでした。
Figureの創業者は、「ロボットの艦隊(フリート)がエンドツーエンドの業務を行っている」かのような発言をし、その進捗をアピールしました。しかし、現場の実態はもう少し慎重なものだったようです。
後の報道やBMW側の説明によると、初期の導入は「工場の稼働が止まっている時間帯」に行われた練習運用が中心であり、実際に稼働していたのは艦隊ではなく単一のロボットだったという指摘もあります。
これは決して、彼らが嘘をついているということではありません。「将来的なビジョン」を語るスタートアップ側の熱量と、「安全と品質」を最優先する製造現場の温度感には、どうしてもズレが生じるものです。
ここから私たちが学ぶべき教訓はシンプルです。ニュースリリースの「商用契約」という言葉を見たとき、それが「明日から全ラインが自動化される」ことを意味するのか、それとも「これから長い実証実験が始まる」ことを意味するのか、一度立ち止まって見極める必要があるということです。
「見る」のは得意でも、「触れる」のは難しい
なぜ、現場への導入はこれほど慎重に進められるのでしょうか? その大きな理由の一つに、「触覚」の圧倒的な難しさがあります。
近年のAIブームにより、ロボットはカメラを通して世界を「見る」能力を飛躍的に向上させました。しかし、ものに「触れて、操る」能力は、それほど簡単には進化していません。
著名なロボット工学者であり、ルンバの生みの親でもあるロドニー・ブルックス氏は、現在のヒューマノイドブームに対して厳しい警告を発しています。彼は、人間の手が持つ約17,000個もの触覚受容体の複雑さを指摘し、単に「動画を見て動きを真似る」だけでは、人間のような器用さは獲得できないと論じています。
例えば、ポケットの中で鍵を探り当てたり、熟れすぎたトマトを潰さずに持ったりする動作。私たち人間が無意識に行っているこれらの作業には、視覚だけでなく、指先の繊細なフィードバックが不可欠です。
シミュレーションの中では物理法則をある程度再現できますが、現実世界の「摩擦」や「接触の微妙な感覚」を完璧にコピーすることは、現在の技術でも至難の業です。これが、シミュレーションで学んだAIが現実世界で失敗するSim-to-Realギャップの正体の一つなのです。
安全性のジレンマ:転ぶロボットは笑えない
そして、もっとも深刻な課題が「安全性」です。
ChatGPTが間違った答えを出しても(ハルシネーション)、画面の中のテキストが間違っているだけです。しかし、物理的な身体を持つEmbodied AIが「幻覚」を見て間違った行動をとれば、それは物理的な破壊や、最悪の場合は人間の怪我につながります。
特に、人間と同じサイズで二足歩行するヒューマノイドは、転倒しただけで大きな運動エネルギーを持ちます。そんな鉄の塊が、もし工場のラインで予期せぬ動きをしたらどうなるでしょうか?
そのため、研究の現場では「賢くなること(性能向上)」と同じくらい、「自分の限界を知ること(不確実性の認識)」が重要視され始めています。前章で紹介したFieldAIが「自信のなさ」を可視化しようとしているのは、まさにこのリスク管理のためです。
「何でもできる万能なロボット」よりも、「危ないときは止まる臆病なロボット」の方が、今のところ社会にとっては必要なのかもしれません。
明日の技術をどう見極めるか
さて、ここまで課題ばかりを並べてしまいましたが、私はEmbodied AIの未来に悲観しているわけではありません。むしろ、課題が具体的になったことで、実用化への道筋がはっきりしてきたと感じています。
最後に、読者の皆さんがこの技術ニュースに触れる際、あるいは導入を検討する際に役立つであろう「見極めの視点」をいくつか提案して締めくくりたいと思います。
1. 「汎用」より「特化」から始まる
いきなり「家事全般ができるロボット」を期待するのは時期尚早かもしれません。まずは倉庫の荷運びや、特定の部品の組み立てなど、環境が限定されたタスクから実用化が進んでいくでしょう。ニュースを見る際は、「何でもできる」という言葉よりも、「この特定の作業ができる」という具体的な成果に注目してみてください。
2. 形態へのこだわりを捨てる
「人型(ヒューマノイド)」であることは、必ずしも正解ではありません。車輪で走ったほうが安定する場所もあれば、腕が4本あったほうが便利な作業もあるはずです。ロドニー・ブルックス氏が予測するように、将来成功するロボットは、人間型を捨てて機能に特化した形をしているかもしれません。
3. 「失敗データ」の価値を知る
成功したデモ動画よりも、「失敗したときにどうリカバリーするか」や「どれだけ多様な失敗データを学習しているか」の方が、技術の堅牢性を測る指標になります。実世界での泥臭いデータ収集を重視している企業(例えばFigureとBrookfieldの提携など)は、その点で一歩リードしていると言えるかもしれません。
Embodied AIは、単なる便利な道具の開発競争ではありません。それは、「知能とは何か」「身体性とは何か」を、工学を通じて再定義しようとする人類の壮大な実験です。
魔法のような解決策は明日すぐには来ないかもしれません。しかし、シミュレーションと現実を行き来し、泥臭い課題を一つずつクリアしていくそのプロセスの先にこそ、AIと物理世界が真に融合する未来が待っているのではないでしょうか。
調査手法について
こちらの記事はデスクリサーチAIツール/エージェントのDeskrex.AIを使って作られています。DeskRexは市場調査のテーマに応じた幅広い項目のオートリサーチや、レポート生成ができるAIデスクリサーチツールです。
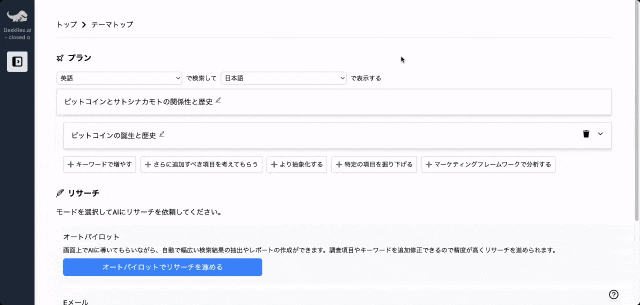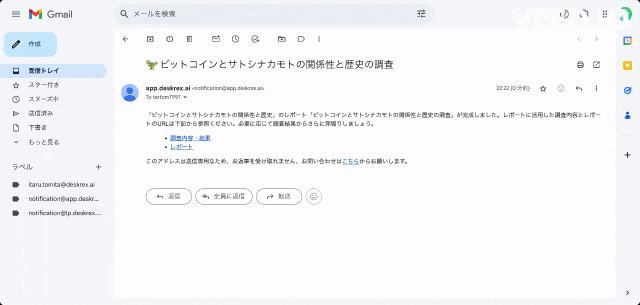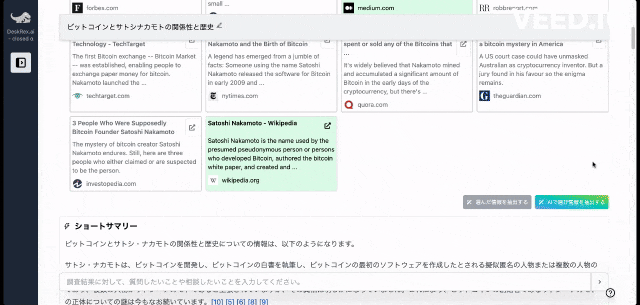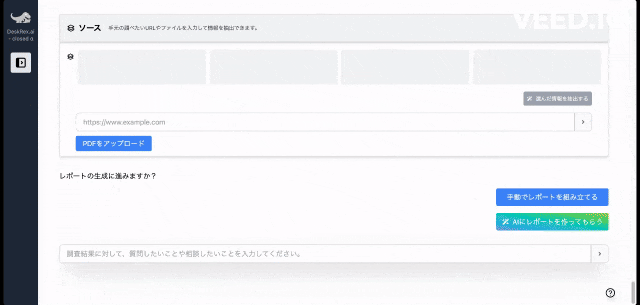
調査したいテーマの入力に応じて、AIが深堀りすべきキーワードや、広げるべき調査項目をレコメンドしながら、自動でリサーチを進めることができます。

また、ワンボタンで最新の100個以上のソースと20個以上の詳細な情報を調べもらい、レポートを生成してEmailに通知してくれる機能もあります。
ご利用をされたい方はこちらからお問い合わせください。
また、生成AI活用におけるLLMアプリ開発や新規事業のリサーチとコンサルティングも受け付けていますので、お困りの方はぜひお気軽にご相談ください。
市場調査やデスクリサーチの生成AIエージェントを作っています 仲間探し中 / Founder of AI Desk Research Agent @deskrex , https://deskrex.ai


コメント