
折り箱もスマホ梱包も99%成功 — GEN-1が工場にやってきた
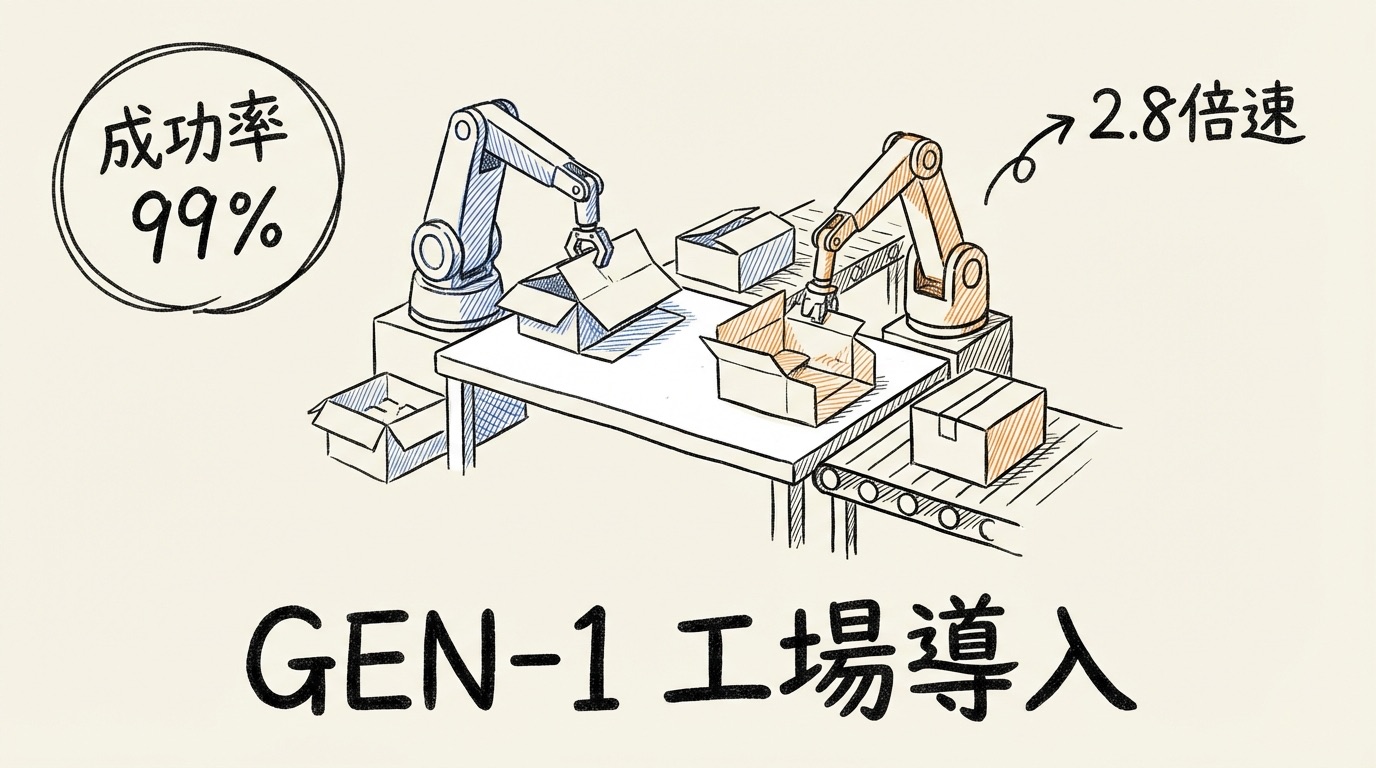
2026年4月2日、Generalist AIというスタートアップがロボット向けの新しいAIモデル「GEN-1」を発表しました。発表された数字を見て、私は正直なところ少し立ち止まりました。いくつかのタスクで成功率が99%以上に達した、それまでの手法と比べて3倍速くタスクを完了できた、新しいロボットや作業環境への適応に必要なデータがたった1時間分だった、という三点です。
「また大げさな発表か」と思う気持ちも分かります。ただ、GEN-1が示したタスクの内容を見ると、どうやら少し話が違うようです。派手なロボットダンスや研究室の中だけのデモではなく、Tシャツを86回連続で折り続けたり、ロボット掃除機の整備を200回以上繰り返したり、部品をケースに詰める作業を1,800回以上こなし続けたりというものです。地味に見えますが、こうした繰り返し作業こそ、工場や物流の現場で毎日発生していて、人手不足が深刻な仕事です。研究者向けのショーケースではなく、現場で使うことを最初から意識した発表という印象を受けました。
以前のモデルとの比較が面白いのですが、GEN-1より前、特定の作業だけを教え込んだ専用モデル(一つのタスクに特化して最初から学習させたもの)の平均成功率は19%でした。前世代モデルのGEN-0をベースにファインチューニング(既存のモデルを新しいタスク向けに追加学習させること)すると64%まで上がり、GEN-1では平均99%に達した。19%から99%への道のりは、少しずつ精度を上げてきた改良の積み重ねというより、ロボットの学習方法そのものが変わり始めているのではないかという気がしてきます。
速さの面でも似たような傾向があります。箱を組み立てる作業で12.1秒という記録が出ていて、GEN-0や競合モデル(Physical IntelligenceのπO)が同じ箱で約34秒かかっていたのと比べると2.8倍速い。スマートフォンをケースに収める作業でも15.5秒で、こちらもGEN-0の2.8倍のペースです。
GEN-1がすべてのタスクを解決できるわけではなく、Generalist AI自身も「一部のタスクでは99%より高い成功率が求められる」と認めています。それでも、「どれだけ確実か」「どれだけ速いか」「想定外の状況に対応できるか」というロボット評価の三つの軸において、実際の現場投入が現実的な選択肢として見えてきた、という点は確かだと思います。
Generalist AIは2024年創業で、2025年には1億4000万ドルを4億4000万ドルの評価額で調達しています。チームには、GoogleでPaLM-EやRT-2といった大規模ロボット向けAIモデルを手がけた人材、ChatGPTやGPT-4の開発に関わった人材、Atlas・Spot・Stretchといった実機ロボットの開発者が名前を連ねています。言語AIの研究者とロボット工学者が同じチームに集まっているという構成が、この会社の特徴です。
なぜそのチーム構成が重要なのかというと、GEN-1の学習方法が、ChatGPTのような大規模言語モデルの発展と深く結びついているからです。GEN-1がどのような仕組みでロボットを動かしているのか、次で見ていきます。
ロボットデータなしで学ぶ — 人間の動作から賢さを借りる仕組み
GEN-1の面白さは、成功率という数字よりも、学習の仕組みそのものにあるのではないかと私は思っています。
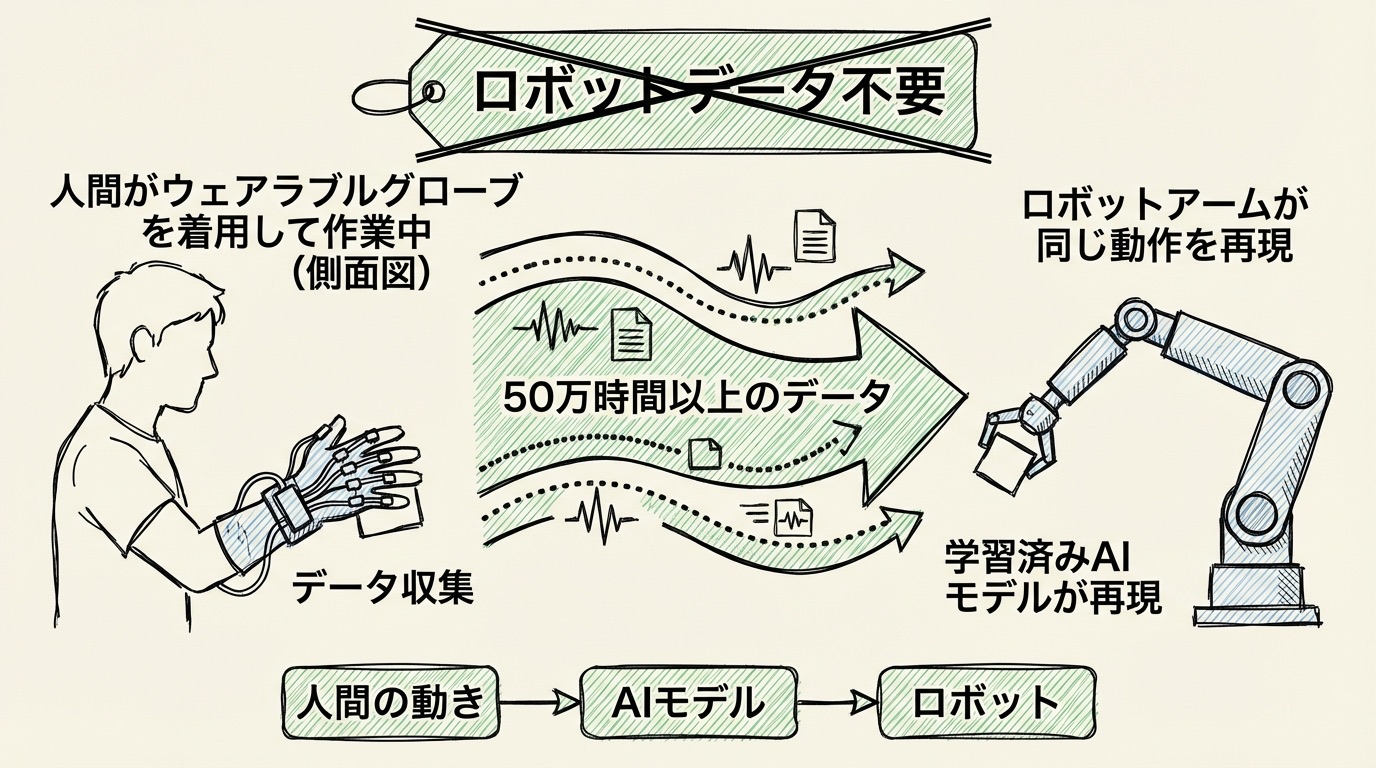
「ロボットを賢くするには、ロボットが動いているデータで学習させる必要がある」、そう考えるのが自然な発想でしょう。ところがGeneralist AIの方針はその逆を行きます。GEN-0もGEN-1も、ベースとなる基盤モデルはロボットデータを一切使わずに訓練されているのです。
では、何で学んでいるのかというと、人間の動作データです。
Generalist AIは低コストのウェアラブルデバイスを活用し、人間が日常的な作業をするときの動きを大量に記録しています。その規模は50万時間以上、ペタバイト級の物理インタラクションデータとされています。ペタバイトとは1テラバイトの1000倍、一般的なスマートフォンストレージ換算で数十万台分に相当する量です。これだけの人間の動作記録が、ロボット学習の土台になっているわけです。
この発想がどこから来ているのか、少し考えてみると面白いことに気づきます。
大規模言語モデル(ChatGPTのような、大量のテキストから言語を学習したAI)が急速に賢くなった背景には、インターネット上の膨大な文章で事前学習するという方法がありました。あらかじめ幅広い知識を身につけておき、特定の用途には少量のデータでファインチューニング(微調整)する。この流れをロボット学習に持ち込もうとしているのが、Generalist AIの戦略です。言語モデルで実証された「大量データでの事前学習+少量データでの適応」という構図を、物理世界の動作学習に応用しようとしているわけです。
GEN-1が示したのは、この事前学習が実際に機能するという証拠です。新しいロボット機体と新しいタスクに同時に適応するとき、GEN-1はその機体も作業内容もどちらも初めて経験します。それでもたった1時間分のロボットデータで適応できるとGeneralist AIは主張しています。比較として参考になるのは、従来の90%超え成功率を達成した手法が「高コストで規模拡大の難しい大量のテレオペレーションデータ」に依存していた点です。テレオペレーション(専門家がロボットを遠隔操作しながらデータを生成する手法)は質の高いデータを作れる半面、専門家の時間を大量に消費するため、スケールさせるほどコストが膨らみます。
データ効率という観点でも変化があります。GEN-1は一部のテストで、GEN-0と同等の性能を10分の1のタスク専用データで達成したとされています。人間の動作データによる事前学習が、ロボット固有のデータへの依存度を下げている可能性があります。
技術実装の面では、GEN-1はいくつかの改善を積み重ねています。訓練の安定性向上、カスタムカーネル(処理の最適化モジュール)の実装、リアルタイム推論を可能にするページドアテンション(メモリを分割して効率的に処理する技術)の新形式、強化学習(試行錯誤を通じて経験から学ぶ手法)やマルチモーダル(映像・音・言語など複数の情報を組み合わせて処理する)ガイダンスの改善などです。ペタバイト規模のデータを扱うため、分散トレーニングインフラも再設計したと公式ブログは述べています。
どうやらGEN-1の方向性は、ロボット産業の長年のボトルネックだった「高品質なロボット実機データを大量に集めるコスト」を、別の角度から回避しようとしているのかもしれません。人間が普通に仕事をするだけで学習データが積み上がっていく世界、そこにどんな可能性があるのかは、次のセクションで掘り下げます。
熟練者の「手の動き」がデータ資産になる時代
前のセクションで、人間がウェアラブルデバイスを着けて作業するだけで学習データが積み上がるという話をしました。ここではその先にある含意を掘り下げてみます。
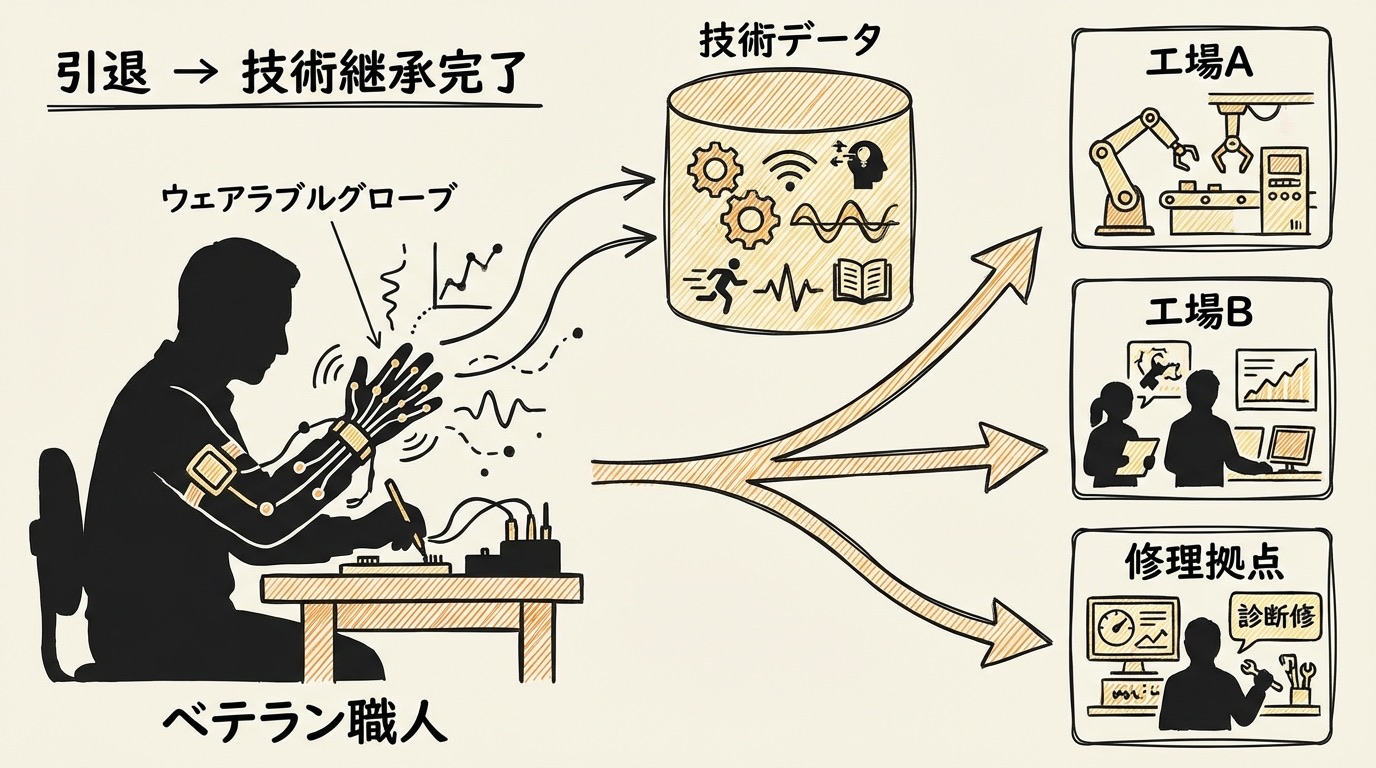
日本の製造業が長年抱えてきた課題のひとつに、技術継承があります。ベテランの職人が引退するとき、その「手の感覚」や「判断の勘所」を次世代に伝えるのがどれほど難しいか、多くの現場が実感しているところです。マニュアルに書き起こしても、動画で撮影しても、実際に身体に染み込んだ技術のすべては記録しきれません。
GEN-1の学習方式は、この問題に別のアプローチをとり得ます。
Generalist AIが採用しているのは、ウェアラブルグローブ(手袋型のセンサーデバイス)などで人間の作業動作を丸ごと収集する方式です。工具に加える力の強さ、指の細かい動き、物体を持ち直す瞬間の判断—文字では伝えにくいものも、センサーデータとしては記録できます。そのデータを基盤モデル(多様なタスクに対応できる汎用AIシステム)に学習させることで、少量のロボット動作データで新しいタスクに適応できるモデルが育っていきます。
投資家のboldstart venturesは自社ブログの中で、Generalistの「データハンド」が人間の細かな動きや直感をロボット学習に取り込む仕組みの核心だと説明しています。
この仕組みが広がると、現場で何が変わるのでしょうか。
ひとつの可能性として、ベテランの引退が「技術の消滅」ではなく「技術の継承完了」になり得ます。優れた職人がウェアラブルを着けながら数週間から数ヶ月作業するだけで、そのデータが基盤モデルに反映されます。工場であれば、ある現場のノウハウを別の拠点に展開するコストが、従来より下がる可能性があります。
GEN-1のデモに「ロボット掃除機の整備」が含まれていたのも、注目に値します。物を組み立てるだけでなく、機械を点検・修理するという作業にも踏み込んでいるからです。これは工場内で「組み立てロボット」「検査ロボット」「保守ロボット」が連携する形への足がかりとも読めます。人手不足が深刻な製造現場や修理拠点にとって、このシナリオは現実味のある話です。
もちろん、楽観的に見すぎるのは禁物です。
GEN-1の数字はGeneralist AI自身の発表に基づいており、第三者による広範なベンチマーク検証はまだこれからです。99%という成功率も「特定の繰り返しタスクに限った数字」であり、工場や医療の現場によっては1%の失敗が許されないケースもあります。動画デモで見える器用さと、24時間365日の連続稼働での安定性は、また別の話です。
ただ、「ベテランの動作が学習データ資産になる」という発想が製造業の現場と交わる地点は、AIチャットボットの普及が業務に与えた変化より、社会的な影響として大きくなる可能性があります。その構造的な変化が次の産業競争の軸にどう影響するか、続けて見ていきましょう。
「ロボットOS」競争が始まる — 勝者はハードよりモデルを握る企業
GEN-1が示唆する変化は、個々のロボットが賢くなるという話にとどまらないように思えます。産業の競争構造そのものが書き変わっていく可能性があるのです。
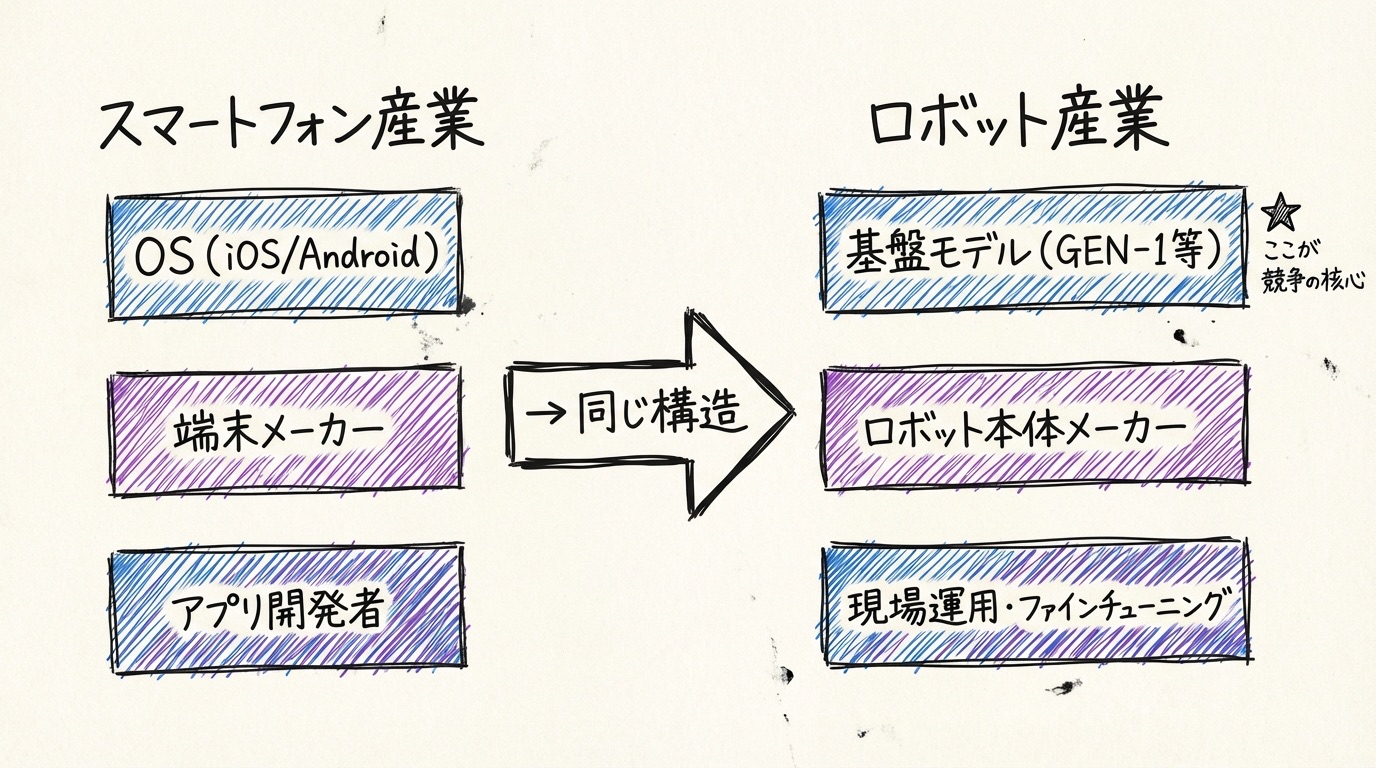
かつてのロボットは機械ごとに専用プログラムを組む必要がありました。タスクが変わるたびにエンジニアが細かく調整し、1台ごとに専門的な設定が求められました。GEN-1が目指しているのは、その発想を根本から変えることです。「汎用的なベース知能を配布し、各現場では少量のデータで動作を仕上げる」というアプローチ、これはスマートフォンのOSアップデートに近い構造です。ソフトウェアを更新するだけで本体の機能が向上するのと同じように、ロボットもモデルを差し替えれば対応範囲が広がる。そういう未来を指し示しています。
この構造が実現した先には、産業の分業が生まれてきそうです。汎用ロボット本体を作る会社、その上で動く基盤モデルを提供する会社、そして現場ごとにモデルをファインチューニング(少量のデータで動作を微調整すること)して運用する会社。この三層構造は、AndroidとiOSを軸に分かれたスマートフォン産業の構図と重なります。スマートフォンでは最終的にOSを押さえたAppleとGoogleが強い立場を確立しました。ロボット産業でも、物理AIのOS的な立場を握るモデル企業が優位に立つ可能性があると、私は感じています。
Generalist AIがGEN-0とGEN-1を通じて繰り返し主張するのは、「ロボティクスにもスケーリング則が存在する」という点です。スケーリング則とは、学習データの量と計算量を増やすほどモデルの性能が予測可能に向上するという経験則で、ChatGPTに代表される大規模言語モデルの発展を支えた原則でもあります。Generalist AIの公式ブログによれば、GEN-0でこの傾向を確認し、GEN-1でさらに前進させたとしています。
もしスケーリング則がロボティクスでも広く成立するなら、産業の勝負はアルゴリズムの巧拙だけでなく「どれだけ多様で質の高い物理動作データを持てるか」で決まっていきます。Generalist AIはすでに半年以上にわたり50万時間以上、ペタバイト規模のデータを積み上げており、データ量で先行しようとしている意図が透けて見えます。
足元のシナリオとして現実的なのは、ヒューマノイドより先に、工場や物流の現場に置かれている既製のロボットアームが賢くなるケースです。Forbesの取材でも、GEN-1は市販ロボットにより広い高器用度タスクをこなさせる方向が示唆されていました。ヒューマノイドはまだ高価で導入のハードルが高いですが、すでに現場に配備されているロボットアームにGEN-1の知能を載せられるなら、普及のペースは早まります。
さらに先を見ると、言語AIがクラウドからスマートフォンやPCなどエッジ端末(ネットワークから離れた手元の機器)に降りてきたように、ロボット基盤モデルも段階的に軽量化・ローカル化が進む可能性があります。工場の現場でリアルタイムに判断するには遅延を極力抑える必要があり、すべての処理をクラウドに頼る構造には限界があります。将来的には「大きな汎用基盤モデルで事前学習 → 現場では軽量な推論モデルでリアルタイム制御 → 判断が難しい場面だけクラウドが支援」という三層構造に収束しやすいのではないでしょうか。
この構造変化の中で、日本企業にとってのチャンスはどこにあるのかと考えると、鍵を握るのは現場データを持っている企業だと思います。自動車工場、物流倉庫、家電修理、病院補助といった現場を抱える会社が、データ供給者として強い立場を持ち得ます。ロボット本体を製造する力だけでなく、「どの現場でどんな作業データを蓄積しているか」が新しい競争軸になっていくかもしれません。
ロボットがソフトウェアのように進化し始める — GEN-1が示す入口
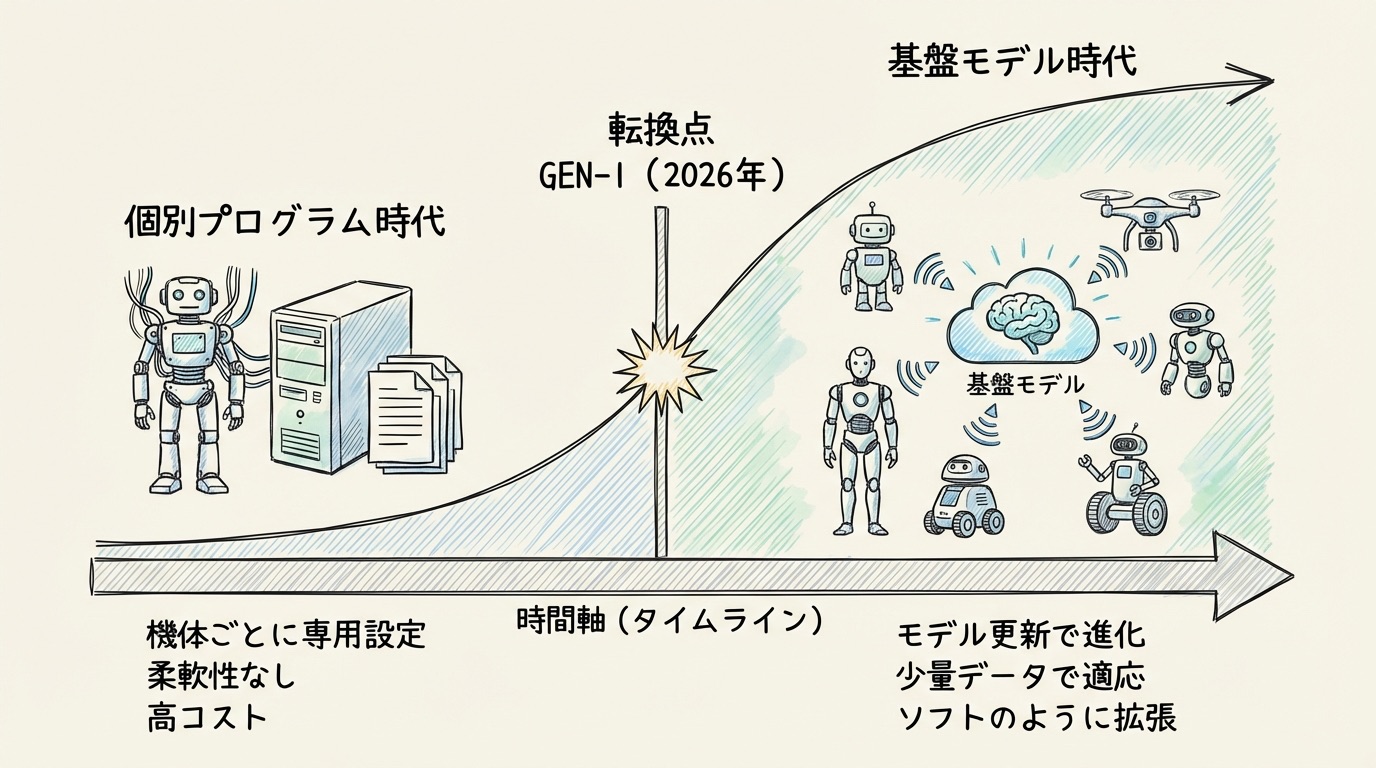
ここまで見てきた内容を振り返ると、GEN-1の本質は「ロボットが少し器用になった」という話ではないと思います。ロボットの学習が「個別案件の積み上げ」から「基盤モデルのスケール」で進む可能性を示した、そこに意味があります。
ただ、冷静に見るべき点もあります。GEN-1の数字の多くはGeneralist AI自身の発表に基づいており、第三者による広範なベンチマーク検証はまだこれからです。「99%成功率」「3倍の速度」という主張は強い分、今後は外部機関の検証と実際の顧客導入事例が判断材料になるでしょう。現場によっては残り1%の失敗が重大な事故につながる場面もあるため、動画デモで見える器用さと24時間連続稼働での安定性は別の問題として、制御・センサー・ハードウェアの信頼性をエンジニアたちがどう担保していくかが問われます。
そうした留保を踏まえても、「現場特化の高頻度タスクから順番に、ロボットが本当に役立ち始める」方向はかなり近づいているように見えます。「もうすぐ万能ロボットが家庭にやってくる」とまでは言えませんが、工場や物流の現場で先に変化が起きる可能性は十分あるのではないでしょうか。
GEN-1の位置づけとして私がしっくりくるのは、「ロボットのChatGPTそのもの」というよりも「ロボットがソフトウェアのように進化し始める入口」という表現です。言語AIがテキストの世界でやったことを、GEN-1は物理世界でやろうとしています。モデルを更新するだけでロボットが賢くなり、新しい作業に少量のデータで適応できるようになり、データを持っている企業が競争力を持つ、このサイクルが回り始めたとすれば、ロボット産業の構造はハードウェア主導からモデル主導へと少しずつ傾いていくかもしれません。ベテラン作業者の動きが学習データ資産として評価されたり、既製のロボットがファームウェアではなくモデルのアップデートで後から賢くなったりする場面が増えると、現場の判断軸も変わってきます。
「スケーリング則がロボティクスにも効く」という仮説が実際に検証されていくプロセスとして、GEN-1は引き続き注目に値します。競合であるGoogle DeepMindのRT-2やPhysical IntelligenceのπOシリーズとの比較、あるいは日本の製造業がこの流れにどう乗るかという視点も、今後追いかけたい論点です。
もし自社でロボット導入を検討している方がいれば、まず自社の現場でどの作業が高頻度かつ定型性が高いかを棚卸しするところから始めてみるとよいかもしれません。GEN-1のようなアプローチが本領を発揮しやすいのは、まさにそういう領域です。
調査手法について
こちらの記事はグラフAIリサーチプラットフォームのSnorbeを使って作られています。Snorbeは研究開発・新規事業向けの調査テーマに応じた幅広い項目のオートリサーチや、ナレッジグラフの構築、構造化レポートの生成ができるAIリサーチツールです。
Screenshot
調査したいテーマを入力するだけで、AIが深堀りすべき観点や広げるべき調査項目をレコメンドしながら、自動でリサーチを進めます。収集した情報はナレッジグラフとして蓄積され、未調査領域(ホワイトスペース)を可視化しながら調査の網羅性を高めていけます。
また、観点マトリクスを30秒・構造化レポートを10分で自動生成する機能があり、出典付きのレポートをMarkdown/PDF形式でエクスポートできます。調査の元データも保存されるため、ファクトチェックや社内共有も容易です。
ご利用をご希望の方は、こちらよりお申し込みください。
また、グラフAIを活用した社内ナレッジ管理や、研究開発・新規事業のリサーチ支援、セルフホスト導入のご相談も受け付けています。お困りの方はお気軽にご連絡ください。
市場調査やデスクリサーチの生成AIエージェントを作っています 仲間探し中 / Founder of AI Desk Research Agent @deskrex , https://deskrex.ai

コメント