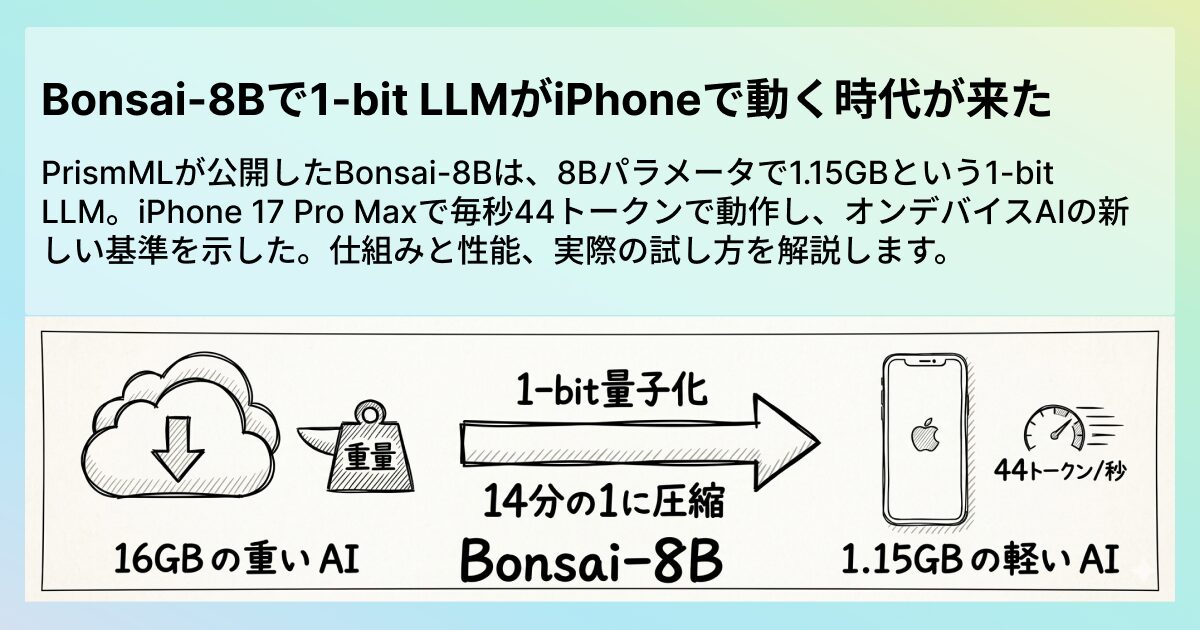
1.15GBのAIがiPhoneで動いた話
要点:PrismMLが2026年4月4日に公開した1-bit LLM「Bonsai-8B」は、8.2Bパラメータでわずか1.15GBというサイズを実現しました。iPhone 17 Pro Maxでも毎秒44トークンで動作し、8Bクラスのオンデバイスローカル推論が現実的な選択肢になってきています。
スマートフォンのストレージを確認してみてほしいのですが、写真アプリやSNSのアプリが数GBを占領している中に、1.15GBのAIモデルが収まるとしたら、どう感じるでしょうか。
2026年4月4日、カリフォルニア工科大学発のスタートアップであるPrismMLが、Bonsai-8Bと名付けた1-bit LLM(重みの精度を1ビットまで下げることでモデルを極限まで圧縮する技術)を公開しました。8.2Bパラメータを持つこのオンデバイスAIモデルのサイズは、わずか1.15GBです。
「8Bパラメータで1.15GB」という数字を聞いても、最初はピンとこないかもしれません。ただ、少し比較してみると差がわかります。通常の16-bit量子化(モデルの重みを16ビット精度で保存する標準的な方式)で保存した8Bモデルは約16.38GBになります。つまりBonsai-8Bは、ほぼ同等のパラメータ数を持ちながら、容量が14分の1以下に抑えられているということです。
この差が何を意味するかというと、「iPhoneで動くかどうか」という具体的な境界線になってきます。現行のiPhoneはメモリの制約から、16GBを超える16-bit版の8Bモデルを動かすことができません。ところがBonsai-8Bは、iPhone 17 Pro Maxで毎秒44トークンを処理できることが確認されています。会話が自然に感じられる速度として一般的に目安となる毎秒30〜40トークンを超えているのです。
「スマホでローカルLLMが動く」という話自体は、ここ数年でよく聞くようになりました。ただ、これまでの多くはパラメータ数を大きく削ったモデルでの話でした。7Bや8Bクラスのモデルが、パラメータ数を維持したままiPhoneで実用的な速度で動くというのは、どうやら少し話の質が違う気がしています。
しかもBonsai-8BはApache 2.0ライセンスで公開されており、開発者が商用サービスにBonsai-8Bを組み込む場合も、追加費用や利用制限なく使えます。実際のアプリ開発やオンデバイスAI機能の組み込みを検討している方にとって、見逃せないポイントではないでしょうか。
では、なぜこれほどのサイズ圧縮が可能になったのでしょうか。答えは「1-bit量子化」という技術にあります。この仕組みを理解すると、Bonsai-8Bが何を犠牲にして、何を手に入れたのかが見えてくるはずです。
そもそも「1-bit」ってどういう意味か
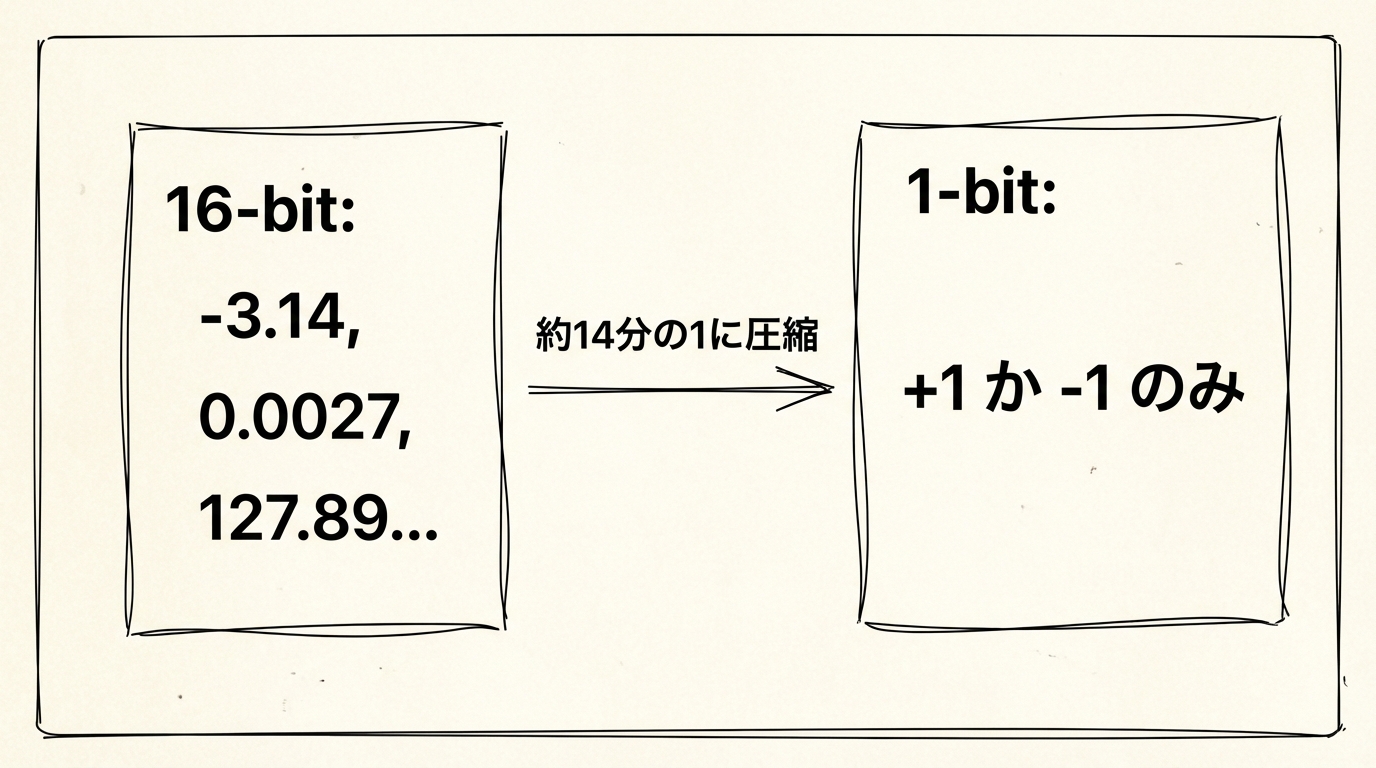
要点:LLMの重みとは、モデルが判断を下すための数値パラメータのこと。従来の16-bit形式を±1のバイナリに切り替えることで、ファイルサイズを約14分の1に圧縮できます。Bonsai-8BはQwen3-8Bの設計を土台にしつつ、重みの表現だけを1-bitに置き換えたモデルです。
LLMがなぜこれほど重いのか、その答えは「重み」にあります。
AIモデルを料理に例えると、重みはレシピの「さじ加減」のようなものです。砂糖を何グラム、塩を何グラム、火加減はどのくらい、という細かい数値の集まりが、料理の味を決めます。LLMも同じで、何百億という数の「さじ加減」が積み重なって、文章の意味を理解したり、次の単語を予測したりする能力が生まれます。
この「さじ加減」を表現するために、従来のモデルでは16-bit浮動小数点数という形式を使っています。これは「-3.14」「0.0027」「127.893」といった小数点以下まで細かく表現できる数値の形式で、1つの重みを格納するのに16bit(2バイト)のデータ量が必要になります。Llama-3やGPT系のモデルが数GBから数十GBになるのは、この「細かいさじ加減」を何十億個も抱えているからです。
ここで考えてみてください。「入れる」か「入れない」かだけで判断したとしたら、どれほどシンプルになるでしょうか。1-bitという発想は、まさにここから来ています。
Bonsai-8Bが採用した手法では、すべての重みを+1か-1という2つの値だけで表現します。小数点以下まで細かく指定するのをやめて、「プラス方向に働く」か「マイナス方向に働く」かの符号だけを残す。埋め込み層もAttentionも、MLPもLM headも、モデルの全ての構成要素がこの考え方で統一されています。
ただし、すべてを±1に丸めるだけでは精度が落ちすぎます。そこで少し工夫があって、128個の重みごとにFP16のスケール値(調整係数)を一つ共有する形で掛け合わせて使います。完全に情報を捨てるのではなく、「大まかな方向はバイナリで、微調整はグループで共有」という設計です。この仕組みにより、HuggingFaceで公開されているMLX形式では1重みあたり約1.25bit相当、GGUF形式では1.125bit相当に収まっています。
この差がファイルサイズに直接現れます。FP16のフルサイズで16.38GBあったモデルが、GGUF形式なら1.15GB、MLX形式なら1.28GBになります。14倍近い圧縮です。ノートPCのSSD数GBを占有していたものが、スマートフォンのアプリ一つ分の容量に収まる計算になります。
なお、Bonsai-8Bのアーキテクチャ自体はQwen3-8Bをベースに設計されています。「一から作った小型モデル」ではなく、既存の高性能モデルの設計を借りつつ、重みの表現だけを1-bitに切り替えたものです。この設計の選択が性能にどう影響しているのかが、次に確かめたいところです。
Bonsai-8Bの性能は実際どうなのか
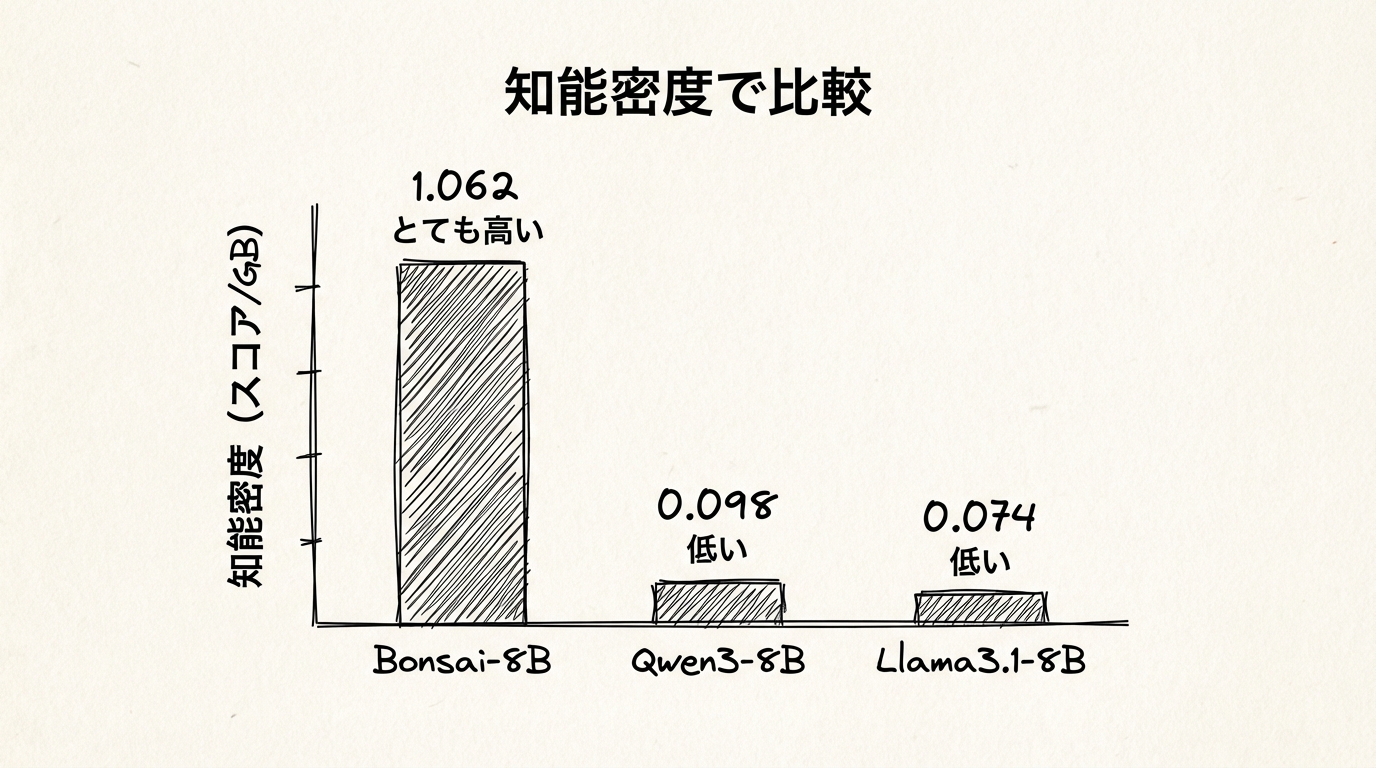
要点:生成速度はFP16比で5〜8倍速く、iPhoneでも44トークン/秒という実用的な数値が出ています。ベンチマークスコアはQwen 3 8Bに劣るものの、ファイルサイズあたりの「知能密度」では約10倍の差があります。1-bit専用ハードウェアが普及すれば、さらなる性能向上の余地がある過渡期の技術です。
数字の話をしてみます。なぜなら1-bitという言葉のインパクトだけで語られると、実際のところどう使えるのかがわからなくなるからです。
まず速度から見てみると、RTX 4090での生成速度は368トークン/秒で、同じモデルをFP16(通常の精度)で動かした場合の5.4倍に相当します。さらに印象的なのはAppleシリコンで、M4 Pro + MLXの組み合わせでは131トークン/秒(FP16比8.4倍)という数字が出ています。131トークン/秒というのは、人間が読める速度をはるかに超えるスピードです。そしてiPhone 17 Pro Maxでは44トークン/秒。スマホで動く8Bモデルとして、これは十分に実用的な速度と言っていいと思います。
ただ、ここで正直に伝えておきたいことがあります。この速度向上の主な要因は、メモリの使用量が大幅に減ったことによるもので、1-bit専用のハードウェア(専用の計算回路)はまだ前提としていません。言い換えると、今の数字は1-bitアーキテクチャが持つポテンシャルの入り口でしかなく、専用ハードが普及すればさらに向上する余地があります。
エネルギー効率についても触れておくと、M4 Proでは0.074 mWh/tok、iPhoneでは0.068 mWh/tokという数値が出ています。これはFP16比で4〜5倍の改善です。バッテリーの持ちを気にするモバイル用途では、この差は無視できません。ただし、iPhoneの消費電力の数値には推定が含まれており、実測値ではない部分もあることは覚えておいてください。
では精度(賢さ)はどうでしょうか。ここが一番気になるところだと思います。ベンチマークの平均スコアで見ると、Bonsai-8Bは70.5で、モデルサイズは1.15GB。一方、同じ8Bクラスで現在上位に位置するQwen 3 8Bは79.3ですが、サイズは16GBです。Llama 3.1 8Bは67.1で、こちらも16GB。スコアだけ見ると、Bonsai-8BはQwen 3に劣ります。これは事実として受け止める必要があります。
ただ、ここに「intelligence density(知能密度)」という見方を持ち込むと、少し話が変わってきます。知能密度とは、モデルの能力をファイルサイズで割った比率で、「1GBあたりどれだけ賢いか」を表す指標です。Bonsai-8Bの知能密度は1.062で、Qwen 3 8Bの0.098と比べると約10倍という計算になります。スコアで単純比較するのではなく、「どれだけ少ないリソースでどれだけの能力を発揮できるか」という軸で考えると、Bonsai-8Bの評価はかなり変わってきます。小さな荷物で遠くまで行ける、という感覚に近いかもしれません。
制約についても触れておきましょう。1.15GBという数字はあくまでweights(モデルの本体)のサイズであって、実際に動かすにはKVキャッシュ(文脈を記憶するための作業領域)が別途必要になります。実際のメモリ消費はこれより多くなります。1-bitカーネルはMLXとllama.cppのfork(派生版)に実装されていますが、まだ公式のupstream PRは通っていない状況です。技術として機能はしているものの、主要なフレームワークへの統合という意味ではまだ過渡期にある、と理解しておくのが正確だと思います。
整理すると、Bonsai-8Bはスコアの絶対値では上位モデルに届きません。しかし1.15GBというサイズで70.5のスコアを出すというのは、従来の常識では考えにくい組み合わせでした。そして、この技術の面白さはスコアそのものよりも、「スマホに乗る」という事実が何を意味するかにあります。
ではその「スマホで動く」という状況が、実際の使われ方としてどんな未来を開くのでしょうか。
端末の中にAIが住む未来はどう変わるか
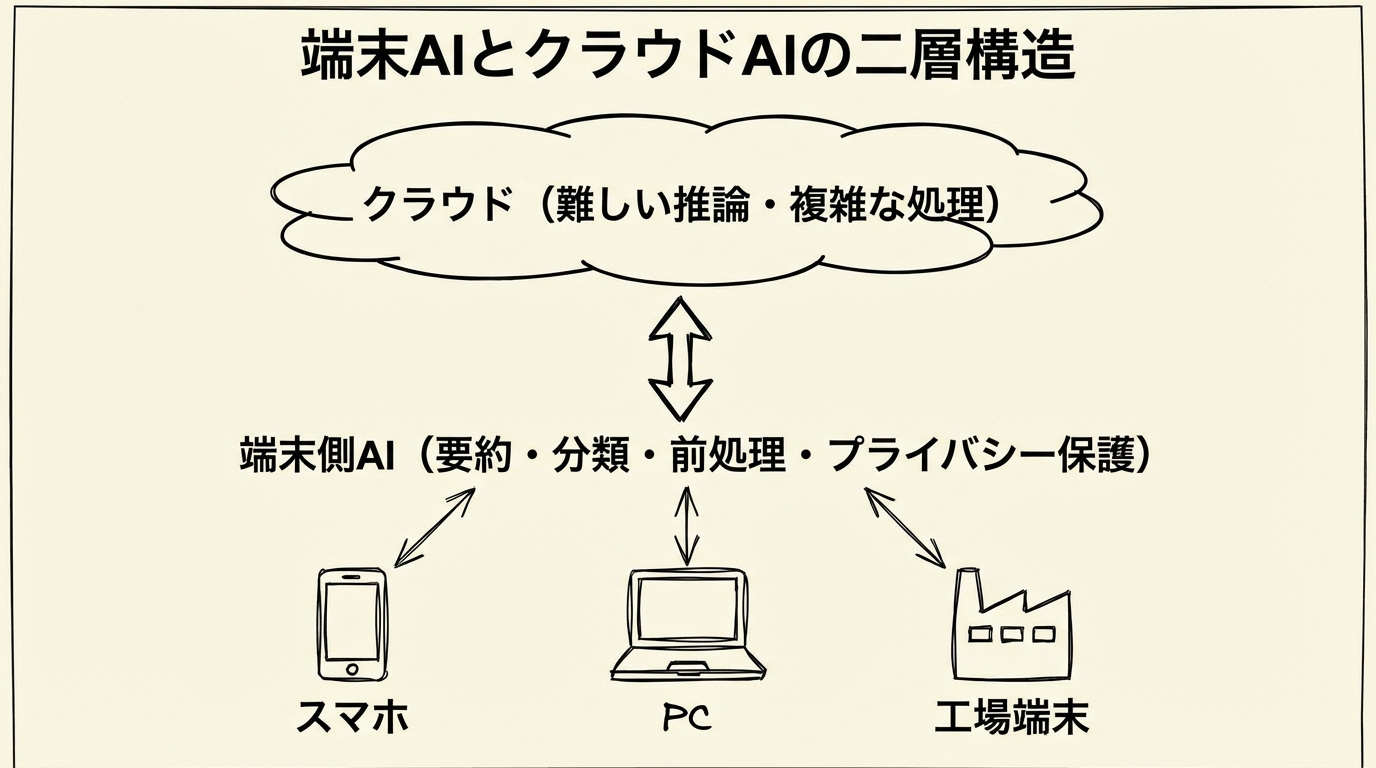
要点:Bonsai-8Bは8B/4B/1.7Bの3サイズ展開で、端末の性能に合わせた配置を最初から設計しています。端末側AIとクラウド側AIの二層構造により、通信量・コスト・情報漏洩リスクを構造的に下げられます。AIの競争軸がベンチマークスコアから、サイズ・消費電力・配備のしやすさへと広がりつつあります。
Bonsai-8Bが興味深いのは、単に「小さくても賢い」というスペックの話だけではありません。どうやら、AIそのものの使われ方が変わる起点になりそうな気がしてきたのです。
PrismMLの公式発表によると、Bonsai-8Bは8B(1.15GB)、4B(0.5GB)、1.7B(0.24GB)という3つのサイズ展開になっています。ハイエンドのスマートフォン、ミドルレンジの端末、そして組み込みデバイスや古めの機器——それぞれに合わせて最適なモデルを配置するという思想が、最初から設計に織り込まれているわけです。「とりあえず動く」ではなく、「どの端末にどう住まわせるか」を最初から考えた設計です。
では、この「端末に住むAI」が現実になったとき、私たちの日常や仕事はどう変わるのでしょうか。
まず思い浮かぶのは、スマートフォンの中に「前処理AI」が常駐するシナリオです。たとえば、日中に溜まったメモを自動的に整理して要約しておく、あるいはLINEやSlackの大量の通知を優先度順に並べ替えておく。これらはいずれも、毎回クラウドに情報を送らなくてもできる仕事です。そして実は、毎回クラウドに送ることへの小さな抵抗感——個人的なメモや会話の内容をサーバーに送ることへの違和感——を多くの人が薄々感じているのではないでしょうか。ローカルAIはその問題を静かに解消してくれます。
企業の現場ではもう少し具体的なシナリオが描けます。製造業の工場では、機械のセンサーデータを端末上のAIがリアルタイムに分析して異常の兆候を検知し、本当に人間の判断が必要なケースだけをクラウドに上げる。医療の現場では、患者の問診内容を端末側でマスキング処理してから、診断支援のためにクラウドへ送る。営業の現場では、商談メモを端末上で要約・分類して、重要な案件だけを営業管理システムに自動登録する。物流では、配送先ごとの最適ルートの下案を端末AIが作り、複雑な条件が絡む部分だけをクラウドの大きなモデルに渡す。
こうした「端末側AI+クラウド側AI」の二層構造は、通信量やAPIコストを減らすだけでなく、情報漏洩リスクを構造的に下げるという点でも企業にとって実用上の価値があります。クラウドAIの強みは複雑な推論や膨大な知識にあり、端末AIの強みはプライバシーと即応性にある。それぞれが得意な仕事を分担する形です。
ただ、ここで一つ正直に言っておきたいことがあります。「クラウドAIはもう不要になる」という方向の話には乗れません。複雑な文脈の推論や、最新の知識を必要とする作業では、まだクラウドの大きなモデルが優位です。1-bitアーキテクチャもエコシステムが形成途上で、専用ハードウェアが整えば「さらに一桁レベルで性能が上がる可能性がある」とPrismMLは示唆しているものの、それが現実になるにはもう少し時間がかかるでしょう。小さいモデルが大きいモデルを「置き換える」のではなく、「担当する仕事の種類が増える」というイメージが正確だと思います。
もう一つ、興味深い変化として感じているのは、AIの競争軸のシフトです。これまでは「ベンチマークで何点取ったか」が重要な指標でした。しかしBonsai-8Bのような動きを見ていると、サイズ・消費電力・オフライン動作の有無・配備のしやすさが、ベンチマークと同じくらい評価される時代が来そうな気がしてきました。「最も賢いAI」よりも「必要な場所で動くAI」が求められる局面が、現場には確実に存在するからです。
Apache 2.0ライセンスで商用利用が可能という点も、この流れを加速させる要因だと思います。スタートアップも大企業も、自社の端末やサービスにBonsai-8Bを組み込んで使い始めることへの障壁がほぼありません。
「AIを使う」という行為が、いつかブラウザを開く感覚と同じくらい自然になる——そんな未来の輪郭が、Bonsai-8Bというモデルを通じて少し見えてきたような気がします。では実際に、このモデルがどれくらいの感覚で動くのか、自分の手で確かめてみませんか。
今すぐ試せる?Bonsai-8Bを動かしてみるには
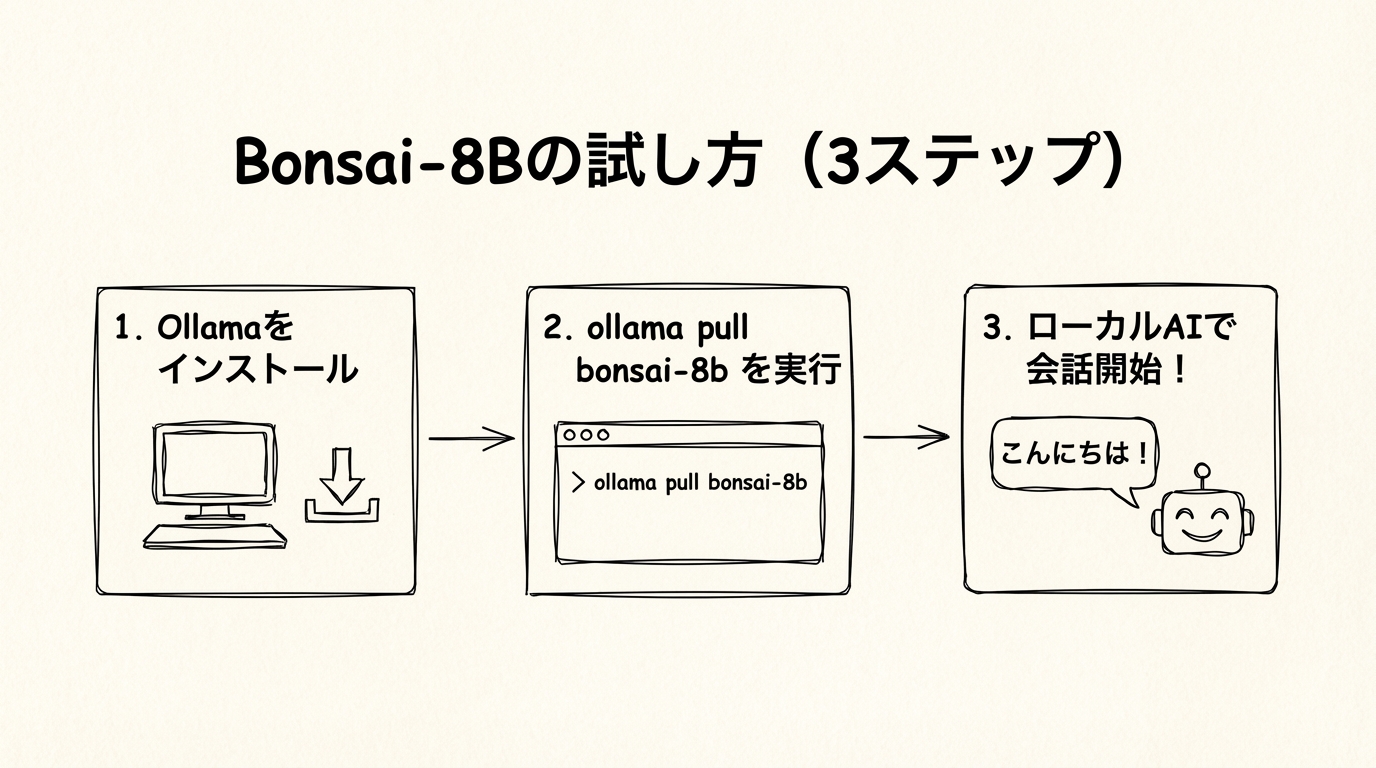
要点:Ollamaを使えばollama pull bonsai-8bのコマンド一つでダウンロードでき、Mac・Linux・Windows全てに対応しています。Apple Silicon MacではMLX形式、他の環境ではGGUF形式を選ぶと1-bitの恩恵を受けられます。1-bitカーネルはまだ公式フレームワークへの統合が進行中のため、将来的にさらに手軽になる見込みです。
ここまで読んで「面白そうだけど、自分には難しそう」と感じた方もいるかもしれません。でも実は、Bonsai-8Bは今日から試せる状態になっています。
最も手軽なのは、Ollamaを使う方法です。Mac・Linux・Windows問わず対応していて、ターミナルでollama pull bonsai-8bと打つだけでダウンロードが始まります。Ollamaをまだ入れたことがない方も、公式サイトからインストーラーを落とすだけなので、ハードルはかなり低いと思います。モデルの実体はGGUF形式のファイルとしてHugging Faceにも公開されており、llama.cppが動く環境であればそちらから直接ダウンロードすることもできます。
Apple Silicon Macをお持ちの方には、MLX形式での動作も選択肢に入ります。load("prism-ml/Bonsai-8B-mlx-1bit")の数行でモデルが読み込めて、M1〜M4チップの性能をきちんと引き出せる設計になっています。
「コマンドはちょっと……」という方には、GitHubのデモリポジトリが用意されています。Mac/Linux向けはsetup.sh、Windowsはsetup.ps1を実行するだけで環境が整う作りになっているので、セットアップで詰まることも少ないはずです。
一つ正直にお伝えしておきたい注意点があります。Hugging Faceにはunpacked FP16版も存在しますが、これは1-bitの恩恵がない通常のモデルです。省メモリで動かしたい場合は、必ずGGUF版かMLX版(mlx-1bitの名前がついているもの)を選んでください。1-bitカーネルはllama.cppとMLXのfork版に含まれていて、公式のupstreamへの統合はまだ進行中という状況です。将来的にはより手軽になっていく可能性が高いので、この点は長い目で見守るのがよいかもしれません。
スマホで動く1-bit LLMという話は、半年前まではほぼSFの領域でした。それが今、手元のMacやWindowsマシンで試せる段階まで来ています。あなたのパソコンで、ローカルのAIが静かに動き出す瞬間を、ぜひ一度体験してみてください。
調査手法について
こちらの記事はグラフAIリサーチプラットフォームのSnorbeを使って作られています。Snorbeは研究開発・新規事業向けの調査テーマに応じた幅広い項目のオートリサーチや、ナレッジグラフの構築、構造化レポートの生成ができるAIリサーチツールです。
Screenshot
調査したいテーマを入力するだけで、AIが深堀りすべき観点や広げるべき調査項目をレコメンドしながら、自動でリサーチを進めます。収集した情報はナレッジグラフとして蓄積され、未調査領域(ホワイトスペース)を可視化しながら調査の網羅性を高めていけます。
また、観点マトリクスを30秒・構造化レポートを10分で自動生成する機能があり、出典付きのレポートをMarkdown/PDF形式でエクスポートできます。調査の元データも保存されるため、ファクトチェックや社内共有も容易です。
ご利用をご希望の方は、こちらよりお申し込みください。
また、グラフAIを活用した社内ナレッジ管理や、研究開発・新規事業のリサーチ支援、セルフホスト導入のご相談も受け付けています。お困りの方はお気軽にご連絡ください。
市場調査やデスクリサーチの生成AIエージェントを作っています 仲間探し中 / Founder of AI Desk Research Agent @deskrex , https://deskrex.ai


コメント