
AIエージェントに「仕事を任せたい」けど、怖くて任せられない

ChatGPTやClaude、Geminiといった生成AIを業務で使っている方なら、一度はこう思ったことがあるのではないでしょうか。「もっと自動でやってくれたらいいのに。でも、勝手に暴走されたら困る」と。
実際、2025年頃から「AIエージェント」という言葉を頻繁に耳にするようになりました。ユーザーの指示を受けて、AIが自律的にツールを操り、タスクを完了してくれる。そんな夢のような仕組みです。ただ、いざ導入を検討すると、「間違った情報をもとに勝手にメールを送ったらどうしよう」「計算ミスに気づかず決済されたら」という不安がつきまといます。
この不安を解消するために注目されているのが、「ニューロシンボリックAI」という考え方です。
ニューロシンボリックAIとは、LLM(大規模言語モデル、生成AIの一つでテキストを生成するもの)のような「ニューラルネットワーク(直感的な判断を得意とするAI)」と、ルールや論理式で動く「シンボリックAI(厳密な推論を得意とするAI)」を組み合わせたアプローチのことを指します。
ざっくり言えば、「柔軟だけど間違えることもあるAI」に、「融通は利かないが絶対にルールを守る仕組み」を組み合わせて、信頼性を高めようという発想です。
ここで一つ、よくある誤解を先に解いておきたいと思います。この「ルールを守る仕組み」は、LLMの中に埋め込まれているわけではありません。LLMの外側に、完全に独立したレイヤーとして存在しています。なぜ中に入れないのか。
理由はシンプルで、LLMはどれだけ訓練しても「たまにルールを忘れる」確率がゼロにならないからです。だからこそ、信頼が必要な部分は確率に頼らず、LLMとは別の場所で、別の仕組みで動かす。この設計判断が、ニューロシンボリックAIの出発点になっています。
ニューロシンボリックAIと既存の生成AIエージェントの違いはどこ?
ただ、この説明を聞いて、ふとこんな疑問が湧いてきた方もいるかもしれません。
「それって結局、AIが裏で別のプログラムを動かしてるだけなんじゃないの? 見た目が賢そうなだけで、中身は同じでしょ?」もっと詳しく言えば、「これ、結局LLMが裏でPythonのコードを書いて実行してるだけなんじゃないの?」とも言えるかもしれません。
正直なところ、このツッコミはあまりにも鋭く、そして的を射ています。実際、私がこれまで見てきた多くの「AIエージェント」の実装は、LangChainやOpenAI Function Callingを使って、LLM(大規模言語モデル)に「計算が必要ならPythonのライブラリ(SymPyなど)を呼んでね」と指示しているだけのものがほとんどでした。
「なんだ、やっぱりそうか」とガッカリされたかもしれません。さらに突っ込んで、「じゃあニューロシンボリックAIって、結局『関数+LLM』を便利にパッケージ化しただけなの?」と思う方もいるでしょう。
半分は正解です。表面だけ見れば、LLMが何かを提案し、別のプログラムが動く、という点では確かに同じに見えます。でも、ちょっと待ってください。どうやら、2025年から2026年にかけて登場している「本物の」ニューロシンボリックAIは、「誰がそのプログラムを動かす許可を出すか」という一点において、従来のものとは根本的に設計思想が異なるようなのです。
今回は、多くの人が抱くこの疑問を解きほぐしながら、なぜ今、世界中の企業や研究者がこの技術に注目しているのか、その本質に迫ってみたいと思います。
その「エージェント」、誰がボスですか?
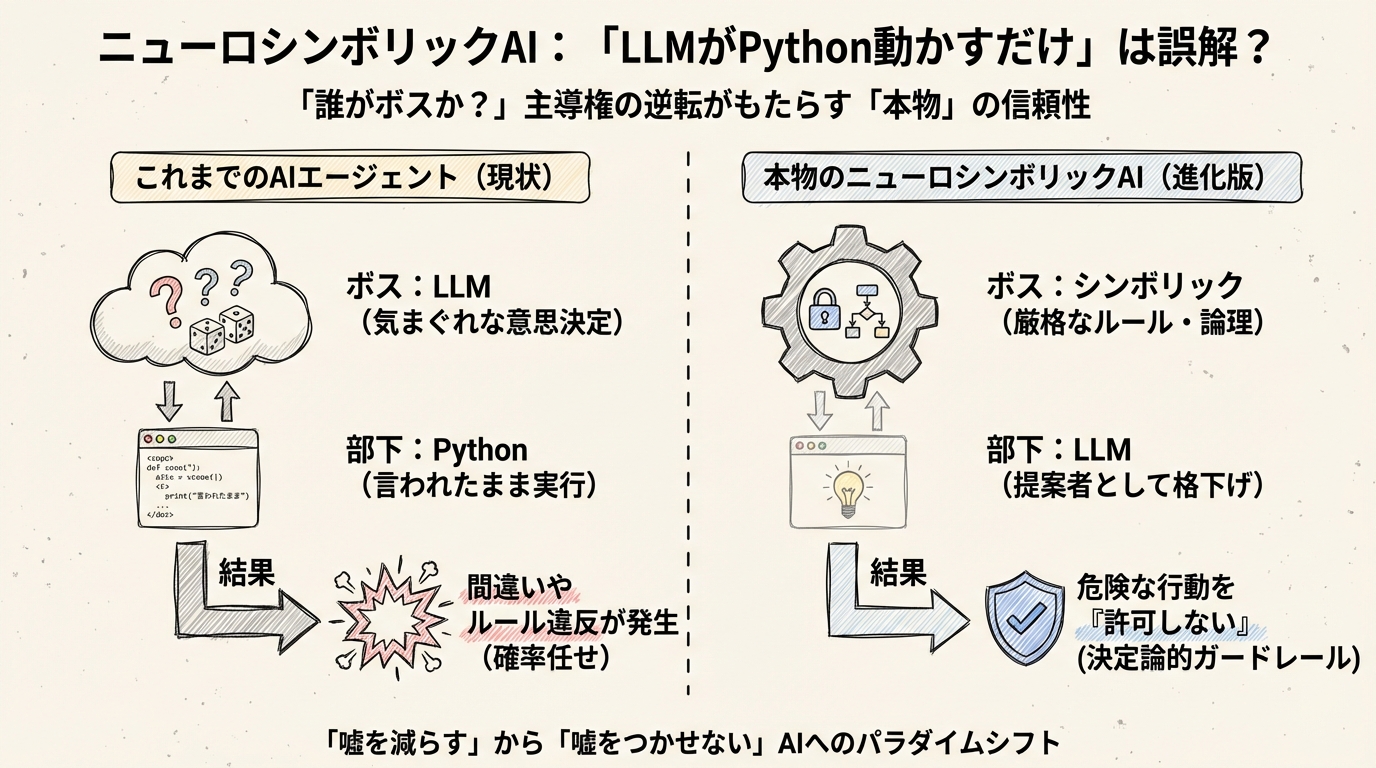
「LLMがプログラム(例:Python)を呼ぶだけ」のエージェントと、「本物のニューロシンボリックAI」の違いとはなんでしょうか。それは、技術の複雑さではありません。シンプルに言えば、「誰がボス(意思決定者)なのか」という主導権の問題に集約される気がします。
一般的なAIエージェントの場合、ボスは間違いなくLLMです。
LLMがユーザーの指示を受け、「次は検索ツールを使おうかな」「いや、Pythonで計算しようかな」と、確率的に次の行動を決定します。Pythonなどのツールは、LLMという気まぐれなボスに使われる「ただの部下」に過ぎません。
これが何を意味するか、想像できるでしょうか。
もしボス(LLM)が、「売上予測の計算式、ちょっと間違えちゃったけどまあいいか」と判断して適当なPythonコードを書いたらどうなるでしょう? あるいは、「予算制限なんてルールあったっけ?」と忘れてしまい、高額な決済APIを叩いてしまったら?
部下であるPythonは、ボスの命令通りに忠実に、間違った計算をし、予算オーバーの決済を実行してしまいます。これが、現在のAIエージェントが抱える「信頼性」の限界です。どれだけ優秀なLLMでも、確率的に動く以上、サイコロの目が悪ければミスを犯します。
「主導権の逆転」がもたらす安心感
ところが、AWS AgentCore Policyや最新の研究論文に見られる「本物の」ニューロシンボリックAIは、この関係性を完全にひっくり返しています。
ここでは、シンボリック(論理・ルール・知識グラフ)がボスであり、LLMは「提案をするだけの部下」に格下げされているのです。
例えば、あるAIエージェントが「今月の予算残高」を計算するタスクを任されたとしましょう。
ニューロシンボリックAIのアプローチでは、LLMが「この計算式でどうですか?」とPythonコードを提案します。すると、ボスであるシンボリックエンジン(論理検証機能)が、その提案を厳密にチェックします。
「待て、その計算式は社の会計ルールに違反している」
「安全マージンが10%未満になる計算は許可できない」
もしルール違反が見つかれば、ボスは即座にLLMの提案を「却下」します。Pythonコードが実行されることはありません。これが、私が「決定論的ガードレール」と呼んでいるものです。
「嘘をつかせない」技術への進化
この「主導権の逆転」がもたらすインパクトは絶大です。
従来のAIが「ハルシネーション(嘘)を減らす」ことに四苦八苦していたのに対し、本物のニューロシンボリックAIは、構造的に「嘘の行動を実行させない」レベルへと進化しています。
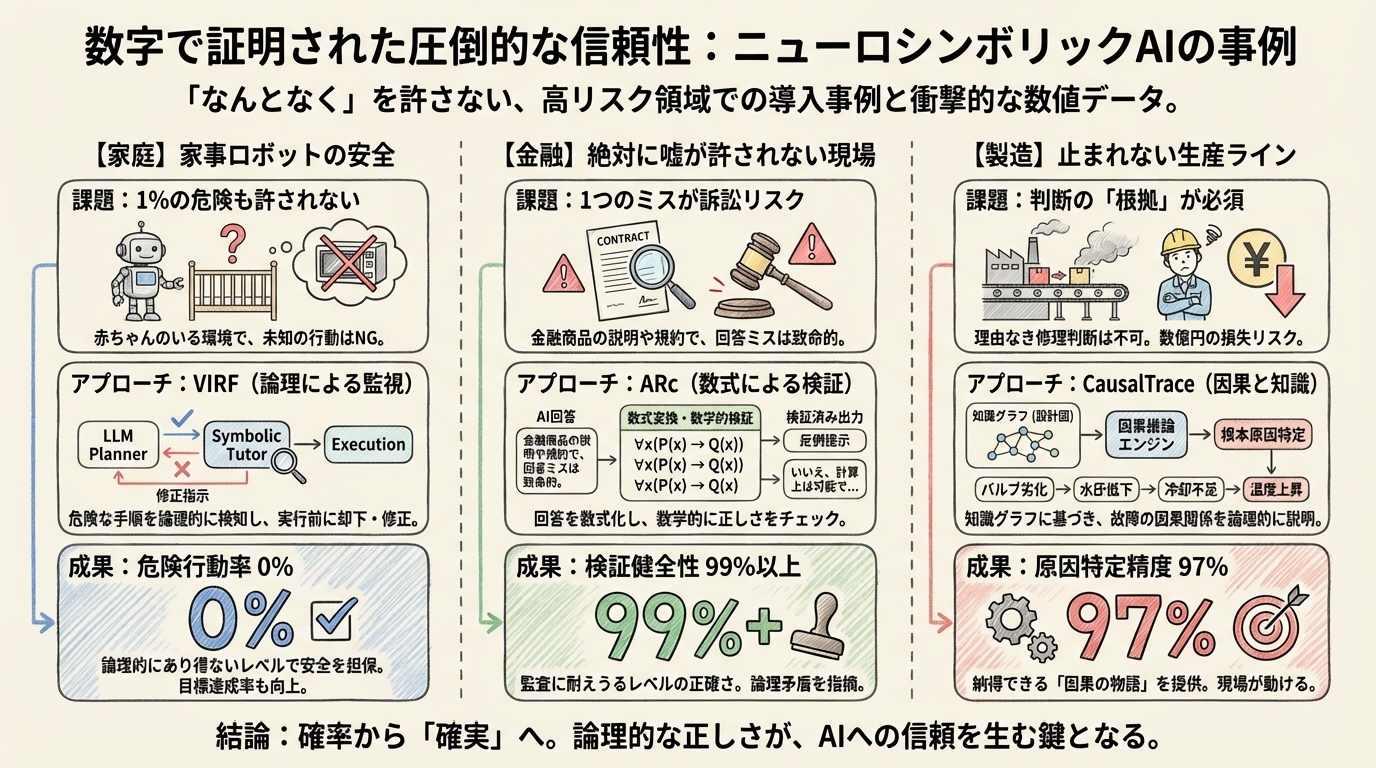
実際、家庭内の安全タスクを扱うVIRFという研究事例では、AIによる危険な行動率(HAR)を完全に0%に抑えつつ、77.3%という高い目標達成率を記録しました。また、規制産業向けのARcというフレームワークでは、LLMの出力に対して99%以上の検証健全性を達成しています。
これらは単なる精度の向上ではありません。「確率任せのAI」から、「ルールで統治されたAI」へのパラダイムシフトが起きている証拠ではないでしょうか。
「結局、Python動かしてるだけでしょ?」という問いに対する私の答えはこうです。
「半分は正解です。でも、そのPythonを実行する『許可』を誰が出しているかを見てください。そこにLLMの気まぐれではなく、厳格なルールが存在するなら、それは世界を変える本物のニューロシンボリックAIかもしれません」
次章では、この「主導権の逆転」が具体的にどのようなアーキテクチャで実現されているのか、LLMを「提案者」に格下げする仕組みについて、さらに詳しく掘り下げていきたいと思います。
主導権の逆転:LLMを「提案者」に格下げするアーキテクチャ
前章で、従来のAIエージェントとニューロシンボリックAIの違いは「誰がボスか」にあるとお話ししました。では、具体的にシステムの中で何が起きているのでしょうか。どうやら、ここにはエンジニアにとって非常に興味深い「アーキテクチャの大転換」が隠されているようです。
このセクションでは、LLM(大規模言語モデル)を「確率的に提案する部下」、シンボリック(論理・ルール)を「最終決定権を持つ上司」と定義し直すことで実現する、新しいAIの制御構造について解説します。
「優秀だけど、たまに嘘をつく部下」をどう使う?
少し想像してみてください。あなたのチームに、とてつもなく博識で、アイデアマンで、仕事が速い新入社員が入ってきたとします。彼はどんな質問にも即座に答え、素晴らしい企画書を一瞬で作ってくれます。
しかし、彼には一つだけ致命的な欠点があります。それは「息をするように嘘をつくこと」があり、しかも「悪気なくルールを無視して暴走すること」があるのです。
さて、あなたならこの新入社員(=LLM)に、会社の銀行口座を操作する権限や、顧客へメールを送信する権限をそのまま渡すでしょうか?
答えは「NO」ですよね。怖くて渡せません。
従来のAIエージェント開発では、実はこれに近いことをやってしまっていた気がします。「君は優秀だから、このツールを使って自由に仕事をしていいよ」と、LLMに実行権限を丸投げしていたのです。これでは事故が起きるのも無理はありません。
そこで登場するのが、ニューロシンボリックAIのアプローチです。
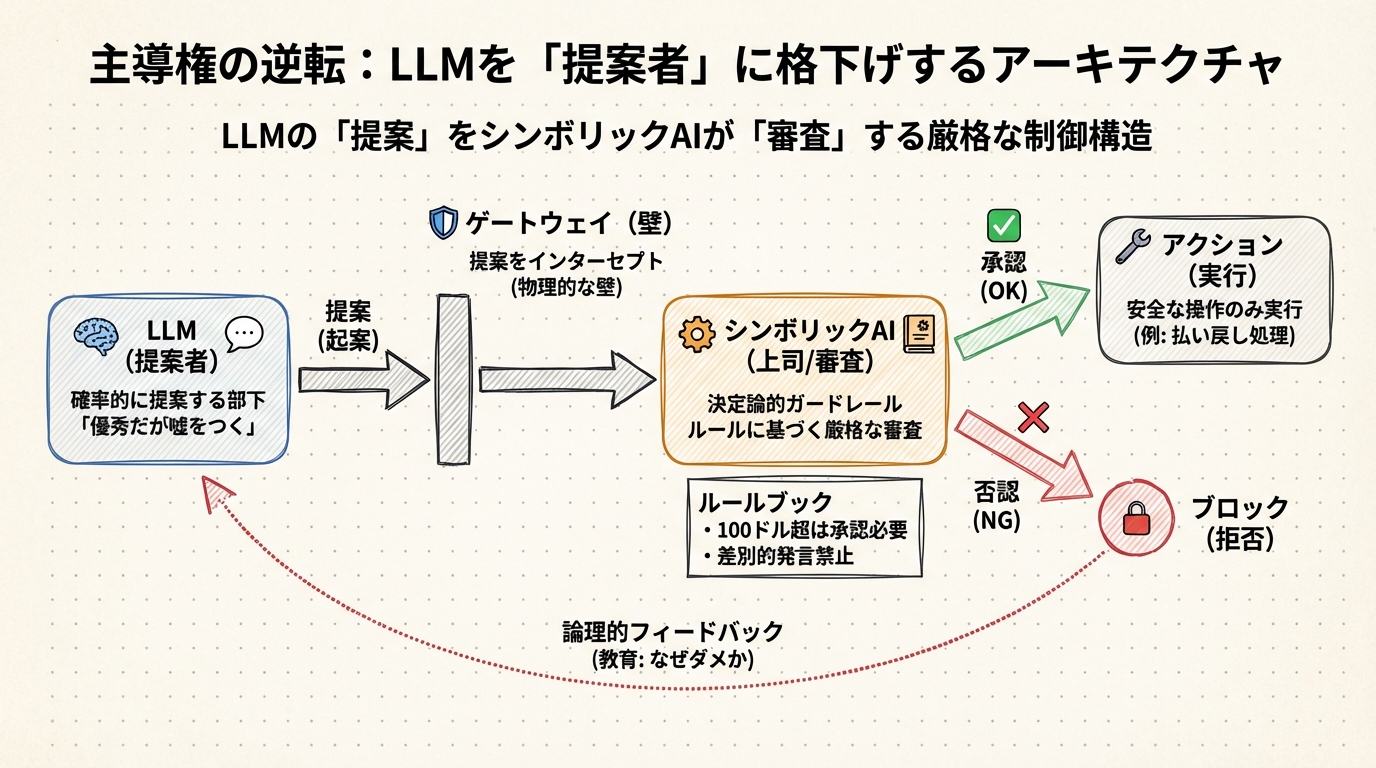
ここでは、LLMに直接「実行」させません。代わりに「提案(起案)」だけをさせます。そして、その提案を「融通の利かない堅物の上司(シンボリックAI)」が別室で審査し、ハンコを押さない限り一歩も外に出さない。そんな厳格なワークフローをシステムの中に組み込むのです。
実行直前に立ちはだかる「物理的な壁」
この仕組みを技術的に実装した好例が、先程申し上げたAWSが提供するAgentCore Policyです。
通常、AIエージェントが「150ドルの払い戻し処理を実行したい」と考えたとします。従来なら、そのまま払い戻しAPIを叩いて終わりでした。しかし、この新しいアーキテクチャでは、エージェントの思考とツールの間に、透明で分厚い「壁(ゲートウェイ)」が存在します。これはLLMの内部にある仕組みではなく、LLMの完全に外側で、独立して動いている別のシステムです。
LLMが「払い戻しツールを実行します」と信号を送っても、その信号は一旦この壁でインターセプト(遮断)されます。そこで待ち構えているのが、ポリシーエンジンと呼ばれる「ルールブックを持った門番」です。
このポリシーエンジンは、Cedar(シダー)という形式論理ベースの言語で書かれたルールに従って動きます。ユーザーは自然言語で書き込むことでルール化することができます。形式論理とは、数学のように「同じ条件なら常に同じ結果を返す」仕組みのことです。LLMのように「たぶんこうだろう」と確率で判断するのではなく、「このルールに該当するかどうか」を機械的に、一切のブレなく判定します。
門番は、LLMの流暢な言い訳には一切耳を貸しません。ただ冷徹に、手元のルールブックと照らし合わせます。
- ルール1: 払い戻し額が100ドルを超える場合は、人間による承認が必要である。
- 現状: 150ドルの払い戻しリクエスト。
判定は「拒否(DENY)」です。
どれだけLLMが「この顧客は重要なんです!」と訴えても、プログラム的に、物理的に、そのリクエストはブロックされます。これが、確率(もしかしたら止まるかも)ではなく、論理(絶対に止まる)で制御する「決定論的ガードレール」の正体です。
見た目は「LLMの中に厳しい上司がいる」ように映るかもしれません。LLMが提案して、それが拒否されたり修正されたりするフィードバックが返ってくるので、一見するとLLM自身が自制しているように見えるのです。
しかし実際には、LLMはあくまで「提案生成マシン」であり、決定論的な判定は完全に別のレイヤーで動いています。LLMを信用しないからこそ、外に分厚い壁を置いている。これが2025年から2026年にかけて企業が本気で採用し始めた設計思想の核心です。
「ダメ出し」がAIを賢くする
さらに面白いのが、ただ止めるだけではない点です。最近の研究事例を見ていると、この「上司」は部下の教育係としても機能し始めているようです。
例えば、先述のVIRFというフレームワークでは、「ロジックチューター」と呼ばれるシンボリック機能が、LLMの提案したプランに対して「なぜダメなのか」を論理的にフィードバックします。
「君のプランだと、赤ちゃんが一人でキッチンにいる状態で包丁を使うことになる。それは危険だからダメだ」
このように因果関係を含めて却下されると、LLM(部下)は「すみません、では赤ちゃんを安全な場所に移動させてから料理します」と、修正案を出せるようになります。
先述のARcというシステムも同様で、自然言語を形式論理に変換し、数学的な証明ソルバーを使って「その回答は論理的に矛盾している」と指摘します。
単にエラーで止まるのではなく、「ルールに基づいた対話」を通じて、結果的に安全で正しい行動が生成される。これこそが、人間社会における「OJT(オン・ザ・ジョブ・トレーニング)」のようなプロセスを、AI内部で高速に回している姿ではないでしょうか。
なぜ今、この知識が必要なのか
「難しい話はいいから、便利なAIを使いたい」と思う方もいるかもしれません。しかし、もしあなたが企業で生成AIを導入しようとしているなら、このアーキテクチャを知っておくことは必須のリテラシーになりつつあります。
なぜなら、この「主導権の逆転」こそが、AIを「おもちゃ」から「業務ツール」へ昇華させる鍵だからです。
世の中のAIエージェントの9割は、いまだに「LLM+関数呼び出しのパッケージ」の域を出ていません。LLMがボスで、ツールはただ呼ばれるだけ。
でも、企業が本気でお金を出して導入するのは、AgentCore Policyのような「決定論的統治レイヤー付き」のものです。どんなに賢いLLMでも、確率的にミスをする可能性はゼロにできません。しかし、その後ろに「絶対にミスを許さないルールベースの監視役」を置くことで、システム全体としての信頼性を飛躍的に引き上げることができます。
- 営業資料を作るなら、誤った価格を絶対に記載させないチェック機能。
- 顧客対応ボットなら、差別的な発言や競合他社の推奨を物理的にブロックする機能。
これらは、プロンプトエンジニアリングで「気をつけてね」とお願いするレベルの話ではありません。システムとして「できないようにする」設計の話です。
さて、この「シンボリック上司」が実際にどれほど優秀なのか、気になってきませんか? 理屈はわかったけれど、本当にそこまで完璧に制御できるのか。次章では、驚くべきことに「危険行動率0%」や「検証健全性99%」といった数字を叩き出した、最新の実証データを見ていきましょう。
「なんとなく」を許さない:数字で証明された圧倒的な信頼性と事例
前章で、LLM(部下)をシンボリックAI(上司)が管理する「主導権の逆転」という仕組みについてお話ししました。理論としては美しく聞こえますが、読者の皆さんは正直なところ、「本当にそんなにうまくいくの?」と感じているのではないでしょうか。
私も最初は半信半疑でした。AIの世界では「90%の精度」と言えば優秀とされますが、残り10%のミスが命取りになる現場もあります。「上司」をつけただけで、そのリスクが本当に消えるのか。
しかし、2025年から2026年にかけて発表された最新の研究データを見て、どうやら認識を改める必要がありそうな気がしてきました。ニューロシンボリックAIが叩き出している数字は、「精度が上がった」というレベルではなく、「信頼の質が変わった」ことを示唆しているからです。
ここでは、製造現場という高リスク領域における、衝撃的な数値と事例をご紹介します。
現場は「理由」を求める
最後に、製造業の事例です。工場で機械が故障した際、「AIがこう言っているから」という理由だけで修理を始める現場監督はいません。「なぜそう判断したのか」という根拠がなければ、数億円規模のラインを止める決断はできないからです。
スマート製造の分野で開発されたCausalTraceは、この課題に対して「因果推論」と「知識グラフ(物事の関係性を地図のようにしたもの)」を組み合わせることで挑みました。
結果として、根本原因を特定する精度(MAP@3)で94%、適合率(PR@2)で97%という極めて高い数値を記録しています。
これは、従来の統計ベースのAI(相関関係を見るだけのもの)が44%程度の精度しか出せなかったのと比べると、圧倒的な差です。
「温度が上がったから故障した」だけでなく、「バルブAの劣化が水圧低下を招き、それが冷却不足を引き起こして温度上昇につながった」という因果の物語を、工場の設計図(知識グラフ)に基づいて論理的に説明できる。だからこそ、現場のプロも納得して動けるのです。
同様のアプローチは造船業界でも進んでいます。ShipWeldプロジェクトでは、溶接ロボットの判断プロセスを完全に透明化することで、熟練工がAIの動きを信頼し、協働できる環境を作っています。ここでは「説明できること」自体が、品質保証の一部になっているのです。
「確率」から「確実」へ
これらの事例を見ていくと、ニューロシンボリックAIがもたらす価値の本質が見えてきます。それは、「ハルシネーション(嘘)を減らす」という消極的な改善ではありません。
- 危険行動率 0%
- 検証健全性 99%以上
- 原因特定精度 97%
これらの数字は、AIが「確率的に、なんとなく正しそうなことを言うツール」から、「論理的に、確実に正しい手順を踏むシステム」へと進化したことを示しています。
「なんとなく」を許さない。
この厳格さこそが、これまでAI導入を躊躇していた高リスク領域の扉をこじ開ける鍵になるのではないでしょうか。
さて、ここまで読めば、ニューロシンボリックAIのすごさは十分に伝わったかと思います。では、実際に私たちがこの技術を導入しようとしたとき、何から始めればいいのでしょうか? 世の中には「自称AIエージェント」が溢れています。その中から「本物」を見極め、設計するための具体的なポイントを、次章で解説します。
明日から使える「本物」の見極め方と設計思想
ここまで、ニューロシンボリックAIが単なる流行語ではなく、信頼性を担保するための必然的な進化であることをお話ししてきました。論理が「上司」として振る舞うことで、AIは初めて「責任ある仕事」を任せられる存在になるわけです。
では、私たちが明日からプロジェクトでAIを選定したり、設計したりする際、具体的にどう動けばいいのでしょうか?
市場には今、「AIエージェント」を名乗るツールやフレームワークが溢れています。その中から、実運用に耐えうる「本物」を見極め、実装するための羅針盤が必要な気がしてきました。ここでは、私が実務で意識している具体的なチェックポイントと、設計思想の転換について共有したいと思います。
「名ばかりエージェント」を見抜く3つの質問
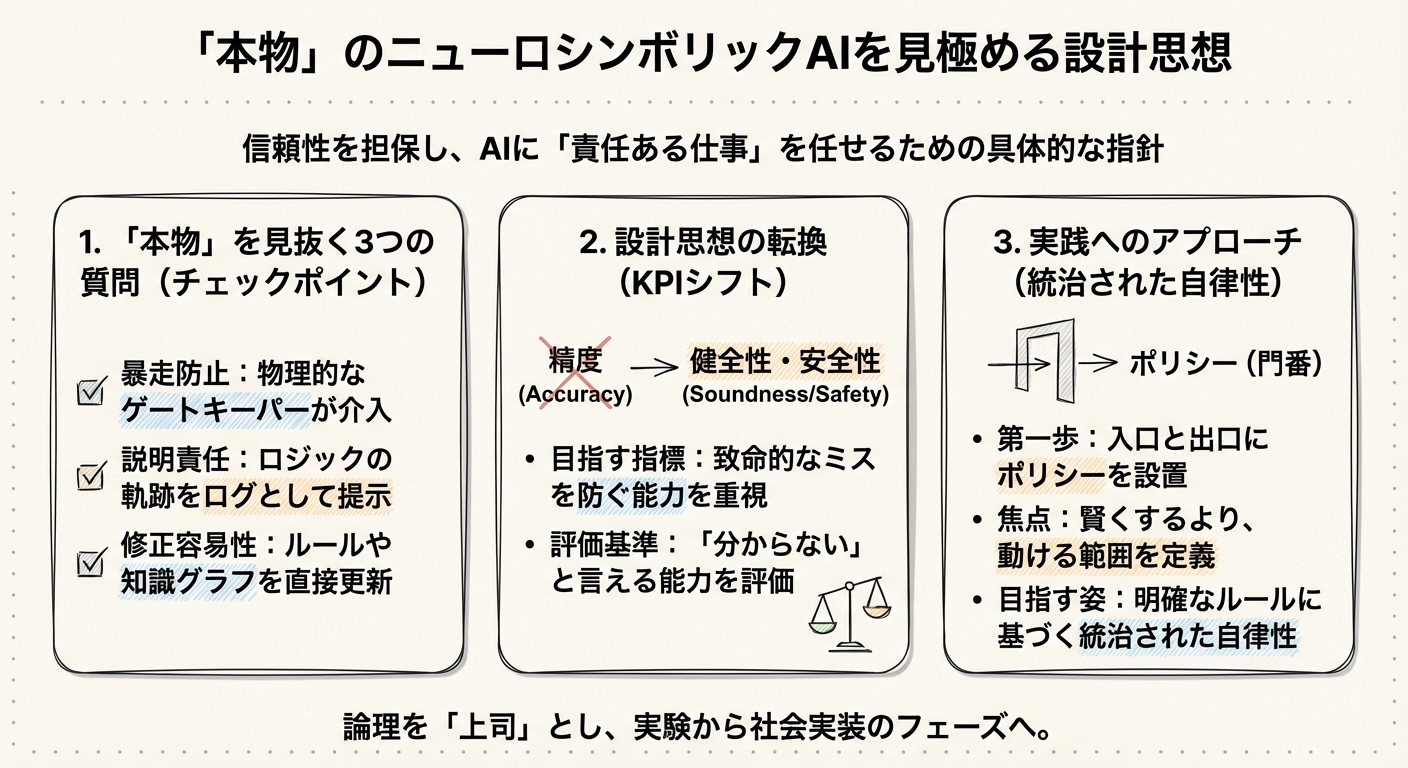
目の前のAIエージェントが、LLMに丸投げの「ツール呼び出し型」なのか、それとも論理が主導する「ニューロシンボリック型」なのか。それを見分けるには、開発ベンダーや設計担当者に次の3つの質問を投げてみるといいかもしれません。
Q1. 「AIが暴走しそうなとき、誰が止めますか?」
もし答えが「プロンプトで『危険なことはしないで』と指示しています」だったら、それは黄色信号です。プロンプトはあくまで「お願い」であり、強制力はありません。
本物のニューロシンボリックAIなら、「推論ループの外側に、決定論的なゲートキーパーがいます」と答えるはずです。
例えばAWS AgentCoreのような基盤では、エージェントがツールを実行しようとした瞬間、そのリクエストを物理的にインターセプト(傍受)し、事前に定義したポリシーと照合します。「人間による承認がない限り、150ドル以上の送金はブロックする」といったルールがシステム的に強制されるのです。この「物理的に止める仕組み」があるかどうかが、最初の分かれ目になります。
Q2. 「『なぜ』をどう説明しますか?」
「LLMが推論過程を要約して教えてくれます」という回答も、実は少し危ういものです。それはLLMが後付けで作った、もっともらしい「言い訳」に過ぎない可能性があるからです。
監査に耐えうる本物のシステムは、ARcの事例のように、「どのルールが発火したか」「どの制約に違反したか」をログとして提示します。「検証ロジックAがエラーコードBを返したため、却下しました」という無機質なログこそが、ビジネスの現場では最も雄弁な説明になるのです。自然言語の流暢さに騙されず、ロジックの足跡が残るかを確認してみてください。
Q3. 「失敗したとき、どう修正しますか?」
「追加学習させます」や「プロンプトを調整します」という答えは、運用コストの増大を意味します。
一方、ニューロシンボリックな設計では、「ルールや知識グラフを更新します」という選択肢が出てきます。NeSyCの研究で見られたように、失敗を教訓にして論理ルール自体を書き換えることができれば、再学習という重いプロセスを経ずに、即座に挙動を修正できます。この「介入可能性」の高さこそが、長く使えるシステムの条件ではないでしょうか。
KPIを変える:「精度」から「健全性」へ
設計思想において最も重要なチェンジは、追うべき数字(KPI)を変えることです。
私たちはつい「正答率(Accuracy)」を追いたくなります。「95%の精度で正解しました!」と言われると嬉しくなりますよね。しかし、高リスクな業務において重要なのは、「どれだけ正解したか」よりも「どれだけ致命的なミスをしなかったか」です。
これからは、「健全性(Soundness)」や「安全性(Safety)」をKPIの主軸に据えるべきかもしれません。
- Accuracy(精度):正解の数 ÷ 全体の数
- Soundness(健全性):出力された答えの中に、論理的に間違っているものが含まれていない割合
前章で紹介したARcが「検証健全性99%以上」を掲げているのは、まさにこの思想です。「分からないときは答えない」「怪しいときは止める」ことができる能力を評価するのです。また、VIRFのように「危険な行動率(HAR)を0%にする」ことを最優先KPIに置くのも良いアプローチでしょう。
「たまに凄いホームランを打つが、たまに三振するバッター」よりも、「絶対にフォアボールを選んで出塁し、チームを危険に晒さないバッター」を評価する。そんなシフトチェンジが必要な気がしています。
まずは「小さく」始めよう
「知識グラフを作ったり、数理論理学を導入したりするのは大変そうだ」
そう思われた方もいるかもしれません。確かに、完全なニューロシンボリックAIを一から構築するのは骨が折れます。
でも、明日からできることはあります。まずは「入り口と出口に門番を置く」ことから始めてみてはいかがでしょうか。
いきなり複雑な推論をさせるのではなく、エージェントが使うツール(APIなど)一つひとつに、「誰が、いつ、どんな条件なら使っていいか」というポリシー(アクセス制御)を設定するのです。
Amazon Bedrock AgentCore Policyのような機能を使えば、エージェントのコード自体を書き換えなくても、外側から「最小権限の原則」を適用できます。
これは「AIを賢くする」アプローチではなく、「AIが動ける範囲を定義する」アプローチです。
CausalTraceのような高度な因果推論システムも、結局は「人間が定義した知識」をベースにしています。私たちが持っている業務ルールやマニュアル、安全基準といった「既存の知」を、AIが参照できる形(ルールセットや簡易的なナレッジベース)に整理してあげる。それだけで、AIの信頼性は劇的に向上します。
統治された自律性を目指して
「AIエージェント」という言葉には、AIが何でも自由にやってくれるという夢が含まれています。しかし、ビジネスの現場で本当に必要なのは、無制限の自由ではなく、「統治された自律性(Governed Autonomy)」ではないでしょうか。
ニューロシンボリックAIは、決してAIの可能性を縛るものではありません。むしろ、明確なルールという土台を与えることで、AIが迷いなく実力を発揮できる環境を作る技術だと言えます。
「精度」という確率のゲームから抜け出し、「論理」という確実性の世界へ。
このパラダイムシフトを受け入れたとき、あなたのプロジェクトは「実験」のフェーズを終え、真の意味での「社会実装」へと歩み出すことになるはずです。さて、あなたの現場には、どんな「上司(論理)」が必要でしょうか?
調査手法について
こちらの記事はデスクリサーチAIツール/エージェントのDeskrex.AIを使って作られています。DeskRexは市場調査のテーマに応じた幅広い項目のオートリサーチや、レポート生成ができるAIデスクリサーチツールです。
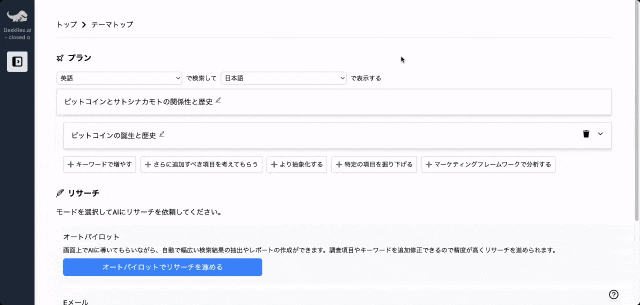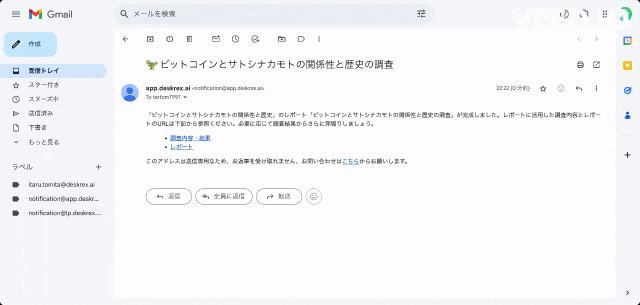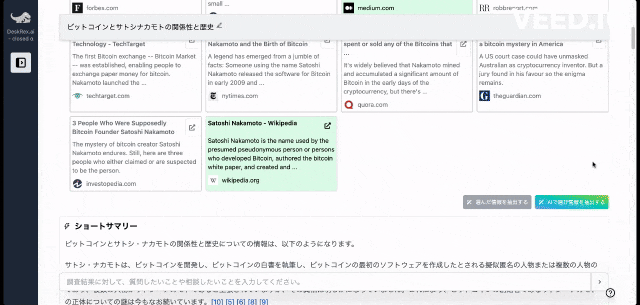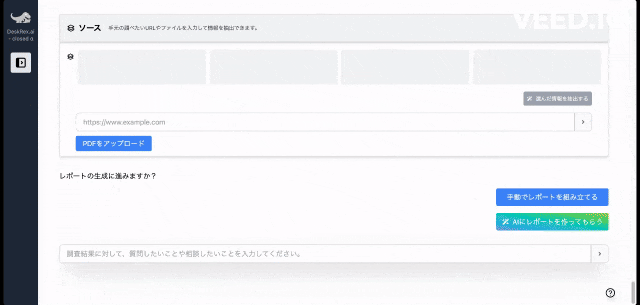
調査したいテーマの入力に応じて、AIが深堀りすべきキーワードや、広げるべき調査項目をレコメンドしながら、自動でリサーチを進めることができます。

また、ワンボタンで最新の100個以上のソースと20個以上の詳細な情報を調べもらい、レポートを生成してEmailに通知してくれる機能もあります。
ご利用をされたい方はこちらからお問い合わせください。
また、生成AI活用におけるLLMアプリ開発や新規事業のリサーチとコンサルティングも受け付けていますので、お困りの方はぜひお気軽にご相談ください。
市場調査やデスクリサーチの生成AIエージェントを作っています 仲間探し中 / Founder of AI Desk Research Agent @deskrex , https://deskrex.ai


コメント